Refining Joint Text and Source Code Embeddings for Retrieval Task with Parameter-Efficient Fine-Tuning
2405.04126
0
0
Abstract
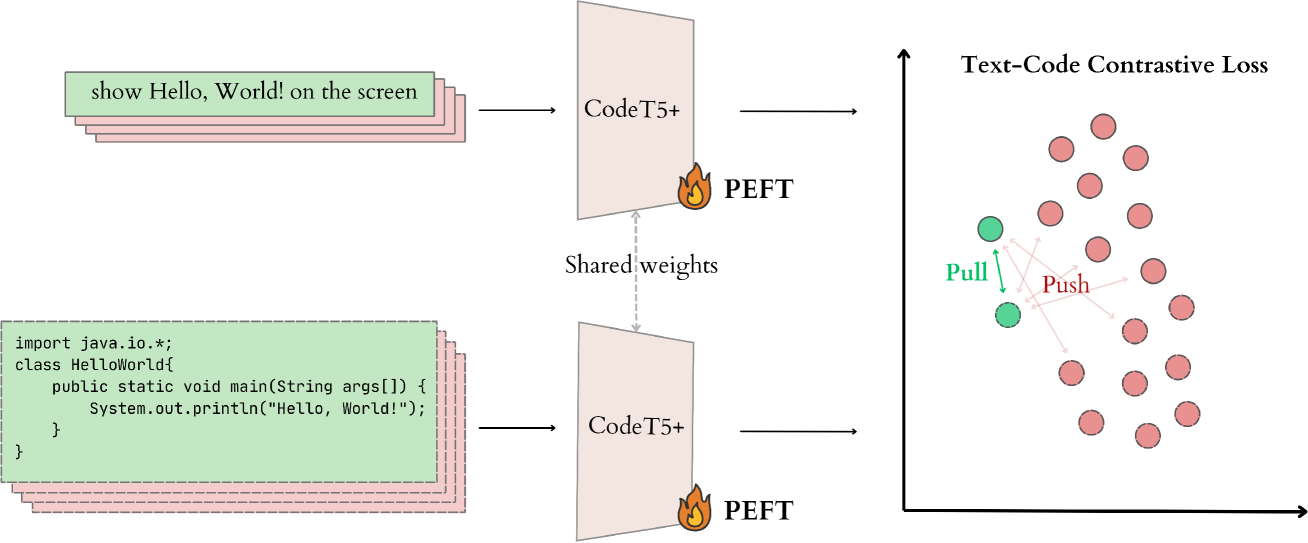
The latest developments in Natural Language Processing (NLP) have demonstrated remarkable progress in a code-text retrieval problem. As the Transformer-based models used in this task continue to increase in size, the computational costs and time required for end-to-end fine-tuning become substantial. This poses a significant challenge for adapting and utilizing these models when computational resources are limited. Motivated by these concerns, we propose a fine-tuning framework that leverages Parameter-Efficient Fine-Tuning (PEFT) techniques. Moreover, we adopt contrastive learning objectives to improve the quality of bimodal representations learned by transformer models. Additionally, for PEFT methods we provide extensive benchmarking, the lack of which has been highlighted as a crucial problem in the literature. Based on the thorough experimentation with the CodeT5+ model conducted on two datasets, we demonstrate that the proposed fine-tuning framework has the potential to improve code-text retrieval performance by tuning only 0.4% parameters at most.
Create account to get full access
Overview
- This paper presents a method for refining joint text and source code embeddings to improve retrieval performance.
- The approach involves parameter-efficient fine-tuning, which updates a small number of parameters in a pre-trained model rather than retraining the entire model.
- The authors demonstrate the effectiveness of their method on a code retrieval task, showing improved performance over baseline approaches.
Plain English Explanation
The paper describes a way to enhance the quality of embedding vectors, which are numerical representations of text and code. Embedding vectors are fundamental building blocks used in many AI and machine learning models, as they allow the computer to understand and work with unstructured data like text and code.
The researchers developed a technique called "parameter-efficient fine-tuning" to refine the embedding vectors. This approach selectively updates a small number of parameters in a pre-trained model, rather than retraining the entire model from scratch. By making targeted updates, the method can improve the embeddings without requiring a complete retraining process, which can be computationally intensive.
The researchers tested their refined embeddings on a code retrieval task, where the goal is to find relevant code snippets based on a textual query. They showed that the embeddings produced by their parameter-efficient fine-tuning method led to better retrieval performance compared to baseline approaches. This suggests the technique can be useful for tasks that rely on effectively representing and matching text and code, such as code search, recommendation, and analysis.
Technical Explanation
The paper introduces a method for refining joint text and source code embeddings to improve their performance on retrieval tasks. The key aspect of the approach is the use of parameter-efficient fine-tuning, which updates a small subset of the model parameters rather than retraining the entire model.
Specifically, the authors leverage a query-dependent parameter-efficient fine-tuning (Q-PEFT) technique, where the fine-tuned parameters are conditioned on the input query. This allows the model to adapt its representation to better match the specific query, rather than using a static set of fine-tuned parameters.
The authors evaluate their approach on a code retrieval task, where the goal is to find relevant code snippets given a natural language query. They show that the refined embeddings produced by their parameter-efficient fine-tuning method lead to improved retrieval performance compared to baseline approaches, including those that use full model fine-tuning.
Critical Analysis
The paper presents a compelling approach for enhancing text and code embeddings to improve retrieval performance. The use of parameter-efficient fine-tuning is a promising technique, as it can improve model performance without the computational cost of retraining the entire model.
One potential limitation of the work is the focus on a single code retrieval task. While the results on this task are promising, it would be valuable to see how the method performs on a wider range of applications that rely on joint text and code representations, such as code summarization, code generation, or program understanding.
Additionally, the paper does not provide a detailed analysis of the types of queries or code snippets where the refined embeddings are most beneficial. Understanding the specific characteristics of queries and code that lead to improved retrieval performance could provide valuable insights for practitioners.
Overall, the research presented in this paper represents an interesting contribution to the field of joint text and code representation learning. The parameter-efficient fine-tuning approach is a promising direction, and further exploration of its applications and limitations could lead to important advancements in this area.
Conclusion
This paper introduces a method for refining joint text and source code embeddings using parameter-efficient fine-tuning. The approach selectively updates a small number of model parameters to adapt the embeddings for improved retrieval performance, without the need for a complete retraining process.
The authors demonstrate the effectiveness of their technique on a code retrieval task, showing significant improvements over baseline approaches. This suggests the refined embeddings can better capture the semantic relationships between text and code, which is crucial for tasks that require understanding and matching natural language queries with relevant code snippets.
The parameter-efficient fine-tuning method presented in this paper represents an important step forward in the development of robust and versatile text and code representation models. As AI systems continue to play a growing role in software development and other domains that rely on the intersection of natural language and programming, techniques like this will become increasingly valuable for enhancing the performance and capabilities of these systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Q-PEFT: Query-dependent Parameter Efficient Fine-tuning for Text Reranking with Large Language Models
Zhiyuan Peng, Xuyang Wu, Qifan Wang, Sravanthi Rajanala, Yi Fang
0
0
Parameter Efficient Fine-Tuning (PEFT) methods have been extensively utilized in Large Language Models (LLMs) to improve the down-streaming tasks without the cost of fine-tuing the whole LLMs. Recent studies have shown how to effectively use PEFT for fine-tuning LLMs in ranking tasks with convincing performance; there are some limitations, including the learned prompt being fixed for different documents, overfitting to specific tasks, and low adaptation ability. In this paper, we introduce a query-dependent parameter efficient fine-tuning (Q-PEFT) approach for text reranking to leak the information of the true queries to LLMs and then make the generation of true queries from input documents much easier. Specifically, we utilize the query to extract the top-$k$ tokens from concatenated documents, serving as contextual clues. We further augment Q-PEFT by substituting the retrieval mechanism with a multi-head attention layer to achieve end-to-end training and cover all the tokens in the documents, guiding the LLMs to generate more document-specific synthetic queries, thereby further improving the reranking performance. Extensive experiments are conducted on four public datasets, demonstrating the effectiveness of our proposed approach.
4/15/2024

Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, Sai Qian Zhang
0
0
Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
4/30/2024

An Empirical Study on Parameter-Efficient Fine-Tuning for MultiModal Large Language Models
Xiongtao Zhou, Jie He, Yuhua Ke, Guangyao Zhu, V'ictor Guti'errez-Basulto, Jeff Z. Pan
0
0
Multimodal large language models (MLLMs) fine-tuned with multimodal instruction datasets have demonstrated remarkable capabilities in multimodal tasks. However, fine-tuning all parameters of MLLMs has become challenging as they usually contain billions of parameters. To address this issue, we study parameter-efficient fine-tuning (PEFT) methods for MLLMs. We aim to identify effective methods for enhancing the performance of MLLMs in scenarios where only a limited number of parameters are trained. This paper conducts empirical studies using four popular PEFT methods to fine-tune the LLM component of open-source MLLMs. We present a comprehensive analysis that encompasses various aspects, including the impact of PEFT methods on various models, parameters and location of the PEFT module, size of fine-tuning data, model stability based on PEFT methods, MLLM's generalization, and hallucination. We evaluated four PEFT methods on seven datasets from two different categories: unseen and seen datasets. Across all experiments, we show that the adapter is the best-performing PEFT method. At the same time, fine-tuning the connector layers leads to improved performance in most MLLMs. Code and data are available at https://github.com/alenai97/PEFT-MLLM.git.
6/10/2024

Parameter Efficient Fine Tuning: A Comprehensive Analysis Across Applications
Charith Chandra Sai Balne, Sreyoshi Bhaduri, Tamoghna Roy, Vinija Jain, Aman Chadha
0
0
The rise of deep learning has marked significant progress in fields such as computer vision, natural language processing, and medical imaging, primarily through the adaptation of pre-trained models for specific tasks. Traditional fine-tuning methods, involving adjustments to all parameters, face challenges due to high computational and memory demands. This has led to the development of Parameter Efficient Fine-Tuning (PEFT) techniques, which selectively update parameters to balance computational efficiency with performance. This review examines PEFT approaches, offering a detailed comparison of various strategies highlighting applications across different domains, including text generation, medical imaging, protein modeling, and speech synthesis. By assessing the effectiveness of PEFT methods in reducing computational load, speeding up training, and lowering memory usage, this paper contributes to making deep learning more accessible and adaptable, facilitating its wider application and encouraging innovation in model optimization. Ultimately, the paper aims to contribute towards insights into PEFT's evolving landscape, guiding researchers and practitioners in overcoming the limitations of conventional fine-tuning approaches.
4/23/2024