Reinforcement Learning in Dynamic Treatment Regimes Needs Critical Reexamination
2405.18556
0
0

Abstract
In the rapidly changing healthcare landscape, the implementation of offline reinforcement learning (RL) in dynamic treatment regimes (DTRs) presents a mix of unprecedented opportunities and challenges. This position paper offers a critical examination of the current status of offline RL in the context of DTRs. We argue for a reassessment of applying RL in DTRs, citing concerns such as inconsistent and potentially inconclusive evaluation metrics, the absence of naive and supervised learning baselines, and the diverse choice of RL formulation in existing research. Through a case study with more than 17,000 evaluation experiments using a publicly available Sepsis dataset, we demonstrate that the performance of RL algorithms can significantly vary with changes in evaluation metrics and Markov Decision Process (MDP) formulations. Surprisingly, it is observed that in some instances, RL algorithms can be surpassed by random baselines subjected to policy evaluation methods and reward design. This calls for more careful policy evaluation and algorithm development in future DTR works. Additionally, we discussed potential enhancements toward more reliable development of RL-based dynamic treatment regimes and invited further discussion within the community. Code is available at https://github.com/GilesLuo/ReassessDTR.
Create account to get full access
Overview
- This paper critically examines the use of reinforcement learning (RL) in dynamic treatment regimes (DTRs), a field that aims to optimize personalized healthcare interventions.
- The authors argue that the current applications of RL in DTRs need a careful reassessment, as they may not fully capture the complexities and challenges inherent in real-world healthcare settings.
- The paper suggests that the field of RL in DTRs requires a more rigorous, multi-faceted approach to ensure the reliability and ethical deployment of these techniques in clinical practice.
Plain English Explanation
Reinforcement learning (RL) is a type of artificial intelligence that can be used to help make decisions in complex, changing environments. In the field of healthcare, researchers are exploring how RL can be used to create "dynamic treatment regimes" (DTRs) – personalized treatment plans that adapt over time based on a patient's response.
However, this paper argues that the current use of RL in DTRs needs to be carefully re-evaluated. The authors suggest that the way RL is being applied in healthcare may not fully account for the unique challenges and complexities of real-world medical settings.
For example, RL algorithms may struggle to handle the uncertainty and variability inherent in patient responses to treatment. They may also fail to consider important ethical considerations, such as the potential for biases or unintended consequences that could harm vulnerable patients.
The paper calls for a more rigorous, multi-faceted approach to using RL in DTRs. This could involve developing more realistic simulation environments to test RL algorithms, improving the consistency of clinician evaluations, and incorporating a wider range of statistical and ethical considerations into the design and deployment of these systems.
By taking a more critical and comprehensive approach, the authors believe researchers can help ensure that RL-based DTRs are reliable, safe, and beneficial for patients, rather than potentially harmful or biased.
Technical Explanation
The paper argues that the current applications of reinforcement learning (RL) in dynamic treatment regimes (DTRs) require a critical reassessment. DTRs are personalized treatment plans that adapt over time based on a patient's response, and RL has been proposed as a promising approach for optimizing these regimes.
However, the authors suggest that the way RL is being applied in DTRs may not fully capture the complexities and challenges of real-world healthcare settings. For example, RL algorithms may struggle to handle the uncertainty and variability inherent in patient responses, as well as the need to consider important ethical and safety considerations.
The paper highlights several key areas where the use of RL in DTRs needs to be more carefully evaluated:
-
Simulation environments: The authors argue that current simulation environments used to test RL algorithms for DTRs may not be sufficiently realistic, leading to overly optimistic results that do not translate to clinical practice.
-
Clinician evaluations: The paper suggests that the consistency and reliability of clinician evaluations of RL-based DTRs need to be improved, as these evaluations are crucial for assessing the real-world performance of these systems.
-
Statistical and ethical considerations: The authors argue that a more comprehensive approach is needed, one that incorporates a wider range of statistical and ethical factors into the design and deployment of RL-based DTRs, such as unintended consequences and potential biases.
The paper also highlights the need for more rigorous offline RL techniques that can better account for the complexities of healthcare settings and ensure the safe and ethical deployment of RL-based DTRs.
Critical Analysis
The paper raises important concerns about the current state of reinforcement learning (RL) in dynamic treatment regimes (DTRs). The authors make a compelling case that the field needs a more critical and comprehensive approach to ensure the reliability and ethical deployment of these systems in clinical practice.
One key strength of the paper is its acknowledgment of the inherent complexities and challenges in real-world healthcare settings. The authors rightly point out that RL algorithms may struggle to account for factors such as patient variability, uncertainty, and the need for ethical considerations. These are crucial issues that must be addressed if RL-based DTRs are to be successfully implemented and trusted by clinicians and patients.
The paper's call for more realistic simulation environments, improved clinician evaluations, and a broader incorporation of statistical and ethical factors is well-justified. These recommendations align with the growing emphasis on responsible AI development and the need to ensure that these technologies are aligned with human values and interests.
However, the paper could be strengthened by providing more concrete examples or case studies to illustrate the specific challenges and pitfalls associated with current RL applications in DTRs. Additionally, the paper could explore in more depth the potential barriers to implementing the authors' proposed solutions, such as the technical, organizational, or regulatory hurdles that may need to be overcome.
Overall, this paper is a valuable contribution to the ongoing discussion around the responsible development and deployment of RL in healthcare. By encouraging a more critical and comprehensive approach, the authors are helping to pave the way for RL-based DTRs that are reliable, safe, and truly beneficial for patients.
Conclusion
This paper makes a compelling case for a critical reassessment of the use of reinforcement learning (RL) in dynamic treatment regimes (DTRs). The authors argue that the current applications of RL in this domain may not fully capture the complexities and challenges inherent in real-world healthcare settings, potentially leading to unreliable or even harmful outcomes.
To address these concerns, the paper calls for a more rigorous, multi-faceted approach to using RL in DTRs. This includes the development of more realistic simulation environments, improved consistency in clinician evaluations, and the incorporation of a wider range of statistical and ethical considerations into the design and deployment of these systems.
By taking a more critical and comprehensive approach, the authors believe researchers can help ensure that RL-based DTRs are reliable, safe, and ultimately beneficial for patients, rather than potentially harmful or biased. This paper serves as an important wake-up call for the field, encouraging researchers and clinicians to think deeply about the responsible development and deployment of these promising AI technologies in healthcare.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DTR-Bench: An in silico Environment and Benchmark Platform for Reinforcement Learning Based Dynamic Treatment Regime
Zhiyao Luo, Mingcheng Zhu, Fenglin Liu, Jiali Li, Yangchen Pan, Jiandong Zhou, Tingting Zhu
0
0
Reinforcement learning (RL) has garnered increasing recognition for its potential to optimise dynamic treatment regimes (DTRs) in personalised medicine, particularly for drug dosage prescriptions and medication recommendations. However, a significant challenge persists: the absence of a unified framework for simulating diverse healthcare scenarios and a comprehensive analysis to benchmark the effectiveness of RL algorithms within these contexts. To address this gap, we introduce textit{DTR-Bench}, a benchmarking platform comprising four distinct simulation environments tailored to common DTR applications, including cancer chemotherapy, radiotherapy, glucose management in diabetes, and sepsis treatment. We evaluate various state-of-the-art RL algorithms across these settings, particularly highlighting their performance amidst real-world challenges such as pharmacokinetic/pharmacodynamic (PK/PD) variability, noise, and missing data. Our experiments reveal varying degrees of performance degradation among RL algorithms in the presence of noise and patient variability, with some algorithms failing to converge. Additionally, we observe that using temporal observation representations does not consistently lead to improved performance in DTR settings. Our findings underscore the necessity of developing robust, adaptive RL algorithms capable of effectively managing these complexities to enhance patient-specific healthcare. We have open-sourced our benchmark and code at https://github.com/GilesLuo/DTR-Bench.
5/30/2024
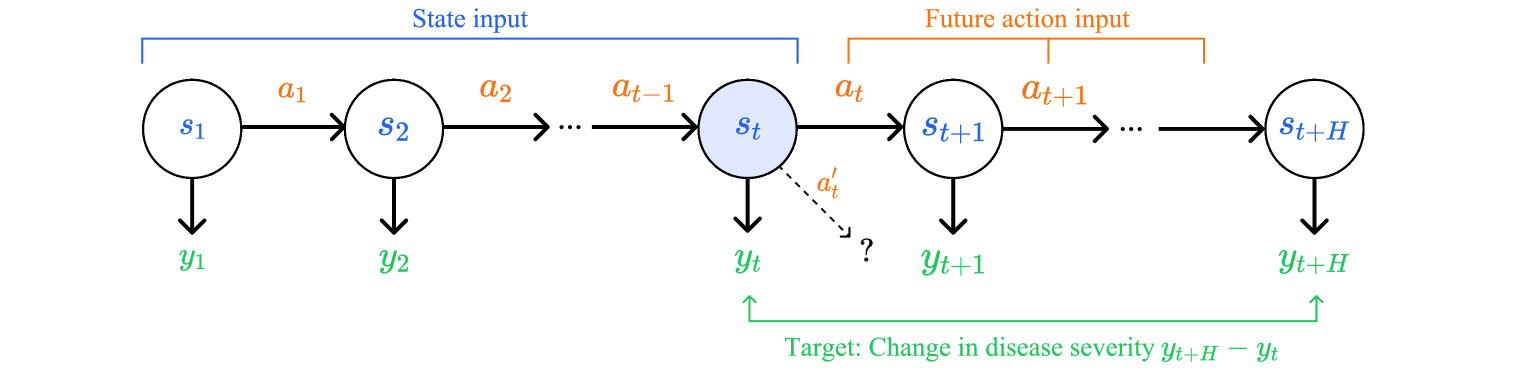
How Consistent are Clinicians? Evaluating the Predictability of Sepsis Disease Progression with Dynamics Models
Unnseo Park, Venkatesh Sivaraman, Adam Perer
0
0
Reinforcement learning (RL) is a promising approach to generate treatment policies for sepsis patients in intensive care. While retrospective evaluation metrics show decreased mortality when these policies are followed, studies with clinicians suggest their recommendations are often spurious. We propose that these shortcomings may be due to lack of diversity in observed actions and outcomes in the training data, and we construct experiments to investigate the feasibility of predicting sepsis disease severity changes due to clinician actions. Preliminary results suggest incorporating action information does not significantly improve model performance, indicating that clinician actions may not be sufficiently variable to yield measurable effects on disease progression. We discuss the implications of these findings for optimizing sepsis treatment.
4/11/2024
🏅
Reinforcement Learning in Modern Biostatistics: Constructing Optimal Adaptive Interventions
Nina Deliu, Joseph Jay Williams, Bibhas Chakraborty
0
0
In recent years, reinforcement learning (RL) has acquired a prominent position in health-related sequential decision-making problems, gaining traction as a valuable tool for delivering adaptive interventions (AIs). However, in part due to a poor synergy between the methodological and the applied communities, its real-life application is still limited and its potential is still to be realized. To address this gap, our work provides the first unified technical survey on RL methods, complemented with case studies, for constructing various types of AIs in healthcare. In particular, using the common methodological umbrella of RL, we bridge two seemingly different AI domains, dynamic treatment regimes and just-in-time adaptive interventions in mobile health, highlighting similarities and differences between them and discussing the implications of using RL. Open problems and considerations for future research directions are outlined. Finally, we leverage our experience in designing case studies in both areas to showcase the significant collaborative opportunities between statistical, RL, and healthcare researchers in advancing AIs.
5/14/2024
🏅
Performative Reinforcement Learning in Gradually Shifting Environments
Ben Rank, Stelios Triantafyllou, Debmalya Mandal, Goran Radanovic
0
0
When Reinforcement Learning (RL) agents are deployed in practice, they might impact their environment and change its dynamics. We propose a new framework to model this phenomenon, where the current environment depends on the deployed policy as well as its previous dynamics. This is a generalization of Performative RL (PRL) [Mandal et al., 2023]. Unlike PRL, our framework allows to model scenarios where the environment gradually adjusts to a deployed policy. We adapt two algorithms from the performative prediction literature to our setting and propose a novel algorithm called Mixed Delayed Repeated Retraining (MDRR). We provide conditions under which these algorithms converge and compare them using three metrics: number of retrainings, approximation guarantee, and number of samples per deployment. MDRR is the first algorithm in this setting which combines samples from multiple deployments in its training. This makes MDRR particularly suitable for scenarios where the environment's response strongly depends on its previous dynamics, which are common in practice. We experimentally compare the algorithms using a simulation-based testbed and our results show that MDRR converges significantly faster than previous approaches.
6/3/2024