Relevant Irrelevance: Generating Alterfactual Explanations for Image Classifiers
2405.05295
0
0
🖼️
Abstract
In this paper, we demonstrate the feasibility of alterfactual explanations for black box image classifiers. Traditional explanation mechanisms from the field of Counterfactual Thinking are a widely-used paradigm for Explainable Artificial Intelligence (XAI), as they follow a natural way of reasoning that humans are familiar with. However, most common approaches from this field are based on communicating information about features or characteristics that are especially important for an AI's decision. However, to fully understand a decision, not only knowledge about relevant features is needed, but the awareness of irrelevant information also highly contributes to the creation of a user's mental model of an AI system. To this end, a novel approach for explaining AI systems called alterfactual explanations was recently proposed on a conceptual level. It is based on showing an alternative reality where irrelevant features of an AI's input are altered. By doing so, the user directly sees which input data characteristics can change arbitrarily without influencing the AI's decision. In this paper, we show for the first time that it is possible to apply this idea to black box models based on neural networks. To this end, we present a GAN-based approach to generate these alterfactual explanations for binary image classifiers. Further, we present a user study that gives interesting insights on how alterfactual explanations can complement counterfactual explanations.
Create account to get full access
Overview
- This paper explores the feasibility of using "alterfactual explanations" to explain the decisions of black box image classifiers.
- Alterfactual explanations are a novel approach to Explainable AI (XAI) that complement traditional "counterfactual explanations" by showing how irrelevant features of an AI's input can be changed without affecting the final decision.
- The authors present a Generative Adversarial Network (GAN)-based approach to generate alterfactual explanations for binary image classifiers.
- The paper also includes a user study that provides insights on how alterfactual explanations can complement counterfactual explanations.
Plain English Explanation
Artificial Intelligence (AI) systems, especially those based on complex neural networks, can be difficult for humans to understand. Counterfactual explanations are a common way to explain AI decisions by showing how the output would change if certain input features were different.
However, to fully understand an AI system, it's also important to know which input features don't affect the decision. That's where "alterfactual explanations" come in. Alterfactual explanations show an alternative reality where irrelevant features of the input are changed, but the AI's decision remains the same.
In this paper, the researchers demonstrate how to generate alterfactual explanations for black box image classifiers using a Generative Adversarial Network (GAN). By seeing which image features can be altered without changing the classification, users can better understand the AI's decision-making process.
The researchers also conducted a user study to understand how alterfactual explanations complement traditional counterfactual explanations. The insights from this study can help improve the way we explain AI systems to human users.
Technical Explanation
The authors present a novel approach for generating "alterfactual explanations" for black box image classifiers. Alterfactual explanations are based on the idea of showing an alternative reality where irrelevant features of the AI's input are changed, while the final decision remains the same.
To generate these alterfactual explanations, the researchers developed a Generative Adversarial Network (GAN)-based approach. The GAN is trained to generate images that are visually similar to the original input, but with certain features altered. The key is that these altered features do not affect the classification output of the black box model.
Through a user study, the authors also explored how alterfactual explanations can complement traditional counterfactual explanations. Counterfactual explanations focus on showing how the AI's decision would change if certain input features were different. By combining counterfactual and alterfactual explanations, users can gain a more comprehensive understanding of the AI's decision-making process.
Critical Analysis
The researchers acknowledge that their work is an initial step in applying alterfactual explanations to black box models, and there are some limitations to their approach. For example, the GAN-based method may not be able to generate highly realistic alterfactual images for all types of input data.
Additionally, the user study provided valuable insights, but had a relatively small sample size. Further research with larger and more diverse user groups would be beneficial to better understand the practical implications of alterfactual explanations.
Another potential issue is that the approach is currently limited to binary classification tasks. Extending the method to handle multi-class classification or other types of AI models would be an important next step.
Despite these limitations, the paper represents an important contribution to the field of Explainable AI (XAI). By introducing alterfactual explanations as a complement to counterfactual explanations, the authors have opened up new avenues for researchers and practitioners to explore in making AI systems more transparent and understandable to human users.
Conclusion
This paper demonstrates the feasibility of using alterfactual explanations to explain the decisions of black box image classifiers. By generating alternative versions of the input where irrelevant features are altered but the classification output remains the same, the approach provides users with a more comprehensive understanding of the AI's decision-making process.
The authors' GAN-based method and user study insights represent an important step forward in the field of Explainable AI. As AI systems become more prevalent in our lives, developing effective techniques to explain their inner workings will be crucial for building trust and ensuring these technologies are used responsibly. The ideas presented in this paper contribute to this broader goal and inspire future research in this exciting area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
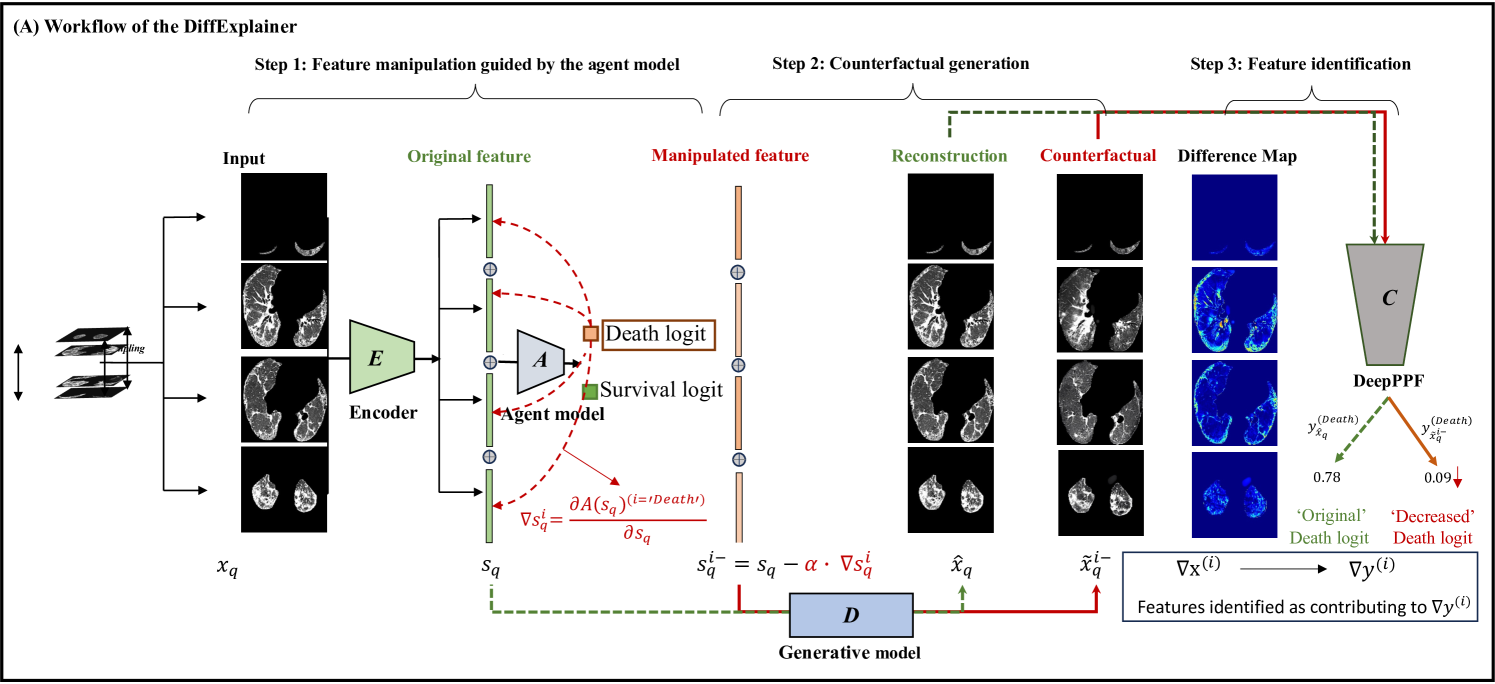
DiffExplainer: Unveiling Black Box Models Via Counterfactual Generation
Yingying Fang, Shuang Wu, Zihao Jin, Caiwen Xu, Shiyi Wang, Simon Walsh, Guang Yang
0
0
In the field of medical imaging, particularly in tasks related to early disease detection and prognosis, understanding the reasoning behind AI model predictions is imperative for assessing their reliability. Conventional explanation methods encounter challenges in identifying decisive features in medical image classifications, especially when discriminative features are subtle or not immediately evident. To address this limitation, we propose an agent model capable of generating counterfactual images that prompt different decisions when plugged into a black box model. By employing this agent model, we can uncover influential image patterns that impact the black model's final predictions. Through our methodology, we efficiently identify features that influence decisions of the deep black box. We validated our approach in the rigorous domain of medical prognosis tasks, showcasing its efficacy and potential to enhance the reliability of deep learning models in medical image classification compared to existing interpretation methods. The code will be publicly available at https://github.com/ayanglab/DiffExplainer.
6/28/2024
🔮
Counterfactual Explanations of Black-box Machine Learning Models using Causal Discovery with Applications to Credit Rating
Daisuke Takahashi, Shohei Shimizu, Takuma Tanaka
0
0
Explainable artificial intelligence (XAI) has helped elucidate the internal mechanisms of machine learning algorithms, bolstering their reliability by demonstrating the basis of their predictions. Several XAI models consider causal relationships to explain models by examining the input-output relationships of prediction models and the dependencies between features. The majority of these models have been based their explanations on counterfactual probabilities, assuming that the causal graph is known. However, this assumption complicates the application of such models to real data, given that the causal relationships between features are unknown in most cases. Thus, this study proposed a novel XAI framework that relaxed the constraint that the causal graph is known. This framework leveraged counterfactual probabilities and additional prior information on causal structure, facilitating the integration of a causal graph estimated through causal discovery methods and a black-box classification model. Furthermore, explanatory scores were estimated based on counterfactual probabilities. Numerical experiments conducted employing artificial data confirmed the possibility of estimating the explanatory score more accurately than in the absence of a causal graph. Finally, as an application to real data, we constructed a classification model of credit ratings assigned by Shiga Bank, Shiga prefecture, Japan. We demonstrated the effectiveness of the proposed method in cases where the causal graph is unknown.
4/30/2024
💬
Viewing the process of generating counterfactuals as a source of knowledge: a new approach for explaining classifiers
Vincent Lemaire, Nathan Le Boudec, Victor Guyomard, Franc{c}oise Fessant
0
0
There are now many explainable AI methods for understanding the decisions of a machine learning model. Among these are those based on counterfactual reasoning, which involve simulating features changes and observing the impact on the prediction. This article proposes to view this simulation process as a source of creating a certain amount of knowledge that can be stored to be used, later, in different ways. This process is illustrated in the additive model and, more specifically, in the case of the naive Bayes classifier, whose interesting properties for this purpose are shown.
4/15/2024
🎯
Benchmarking Instance-Centric Counterfactual Algorithms for XAI: From White Box to Black Bo
Catarina Moreira, Yu-Liang Chou, Chihcheng Hsieh, Chun Ouyang, Joaquim Jorge, Jo~ao Madeiras Pereira
0
0
This study investigates the impact of machine learning models on the generation of counterfactual explanations by conducting a benchmark evaluation over three different types of models: a decision tree (fully transparent, interpretable, white-box model), a random forest (semi-interpretable, grey-box model), and a neural network (fully opaque, black-box model). We tested the counterfactual generation process using four algorithms (DiCE, WatcherCF, prototype, and GrowingSpheresCF) in the literature in 25 different datasets. Our findings indicate that: (1) Different machine learning models have little impact on the generation of counterfactual explanations; (2) Counterfactual algorithms based uniquely on proximity loss functions are not actionable and will not provide meaningful explanations; (3) One cannot have meaningful evaluation results without guaranteeing plausibility in the counterfactual generation. Algorithms that do not consider plausibility in their internal mechanisms will lead to biased and unreliable conclusions if evaluated with the current state-of-the-art metrics; (4) A counterfactual inspection analysis is strongly recommended to ensure a robust examination of counterfactual explanations and the potential identification of biases.
6/12/2024