Benchmarking Instance-Centric Counterfactual Algorithms for XAI: From White Box to Black Bo
2203.02399
0
0
🎯
Abstract
This study investigates the impact of machine learning models on the generation of counterfactual explanations by conducting a benchmark evaluation over three different types of models: a decision tree (fully transparent, interpretable, white-box model), a random forest (semi-interpretable, grey-box model), and a neural network (fully opaque, black-box model). We tested the counterfactual generation process using four algorithms (DiCE, WatcherCF, prototype, and GrowingSpheresCF) in the literature in 25 different datasets. Our findings indicate that: (1) Different machine learning models have little impact on the generation of counterfactual explanations; (2) Counterfactual algorithms based uniquely on proximity loss functions are not actionable and will not provide meaningful explanations; (3) One cannot have meaningful evaluation results without guaranteeing plausibility in the counterfactual generation. Algorithms that do not consider plausibility in their internal mechanisms will lead to biased and unreliable conclusions if evaluated with the current state-of-the-art metrics; (4) A counterfactual inspection analysis is strongly recommended to ensure a robust examination of counterfactual explanations and the potential identification of biases.
Create account to get full access
Overview
- This study investigates the impact of different machine learning models on the generation of counterfactual explanations.
- The researchers tested four counterfactual generation algorithms across three types of machine learning models: decision tree, random forest, and neural network.
- The study was conducted on 25 different datasets to evaluate the performance of these methods.
Plain English Explanation
Counterfactual explanations are a way to understand how machine learning models make decisions. They show what changes would need to be made to the input data for the model to produce a different output. This can be helpful for making machine learning more transparent and interpretable.
The researchers in this study wanted to see how the choice of machine learning model - from a simple decision tree to a complex neural network - affects the generation of counterfactual explanations. They tested four different algorithms for producing counterfactual explanations on 25 different datasets, using three types of models: a decision tree (which is fully transparent), a random forest (which is partially interpretable), and a neural network (which is a black box).
The key findings were:
- The type of machine learning model doesn't have much impact on the counterfactual explanations that are generated.
- Counterfactual algorithms that focus only on proximity (how close the counterfactual is to the original input) don't produce very meaningful or actionable explanations.
- It's important for counterfactual generation algorithms to consider whether the generated counterfactuals are plausible in the real world. Algorithms that don't do this can produce biased and unreliable results.
- Closely inspecting the counterfactual explanations, rather than just looking at summary metrics, is crucial to identify potential issues or biases.
Technical Explanation
The researchers conducted a benchmark evaluation of counterfactual explanation generation across three different types of machine learning models: a decision tree, a random forest, and a neural network. They tested four counterfactual generation algorithms from the literature: DiCE, WatcherCF, prototype, and GrowingSpheresCF.
The experiments were run on 25 diverse datasets to assess the performance of these methods. The researchers evaluated factors like the proximity of the counterfactuals to the original input, the diversity of the counterfactuals, and the plausibility of the generated counterfactuals.
The key findings were:
-
The choice of machine learning model (decision tree, random forest, or neural network) had little impact on the generation of counterfactual explanations. This suggests that the counterfactual generation process is more dependent on the specific algorithm used than the underlying model.
-
Counterfactual algorithms that focus solely on proximity, without considering plausibility, do not produce meaningful or actionable explanations. These algorithms may generate counterfactuals that are mathematically close to the original input, but not actually feasible in the real world.
-
Evaluating counterfactual explanations without accounting for plausibility can lead to biased and unreliable conclusions. The researchers emphasize the importance of ensuring plausibility in the counterfactual generation process.
-
Conducting a detailed, qualitative inspection of the generated counterfactuals, rather than relying only on summary metrics, is crucial for identifying potential issues or biases in the explanations.
Critical Analysis
The researchers acknowledge several limitations and areas for further research. They note that the study focused on a limited set of counterfactual generation algorithms and machine learning models, and that expanding the evaluation to a wider range of methods could provide additional insights.
The researchers also highlight the challenge of defining and measuring plausibility in the context of counterfactual explanations. While they emphasize the importance of this factor, they admit that there is no universally agreed-upon way to assess the plausibility of generated counterfactuals.
Additionally, the study does not delve into the potential societal implications or ethical considerations of counterfactual explanations, such as the risk of perpetuating biases or the impact on decision-making processes. Further research in this area could provide valuable insights.
Overall, the study offers a valuable contribution to the understanding of counterfactual explanations and the factors that influence their generation. The researchers' emphasis on the need for plausibility and qualitative analysis in evaluating counterfactual explanations is a key takeaway that could inform future research and practical applications of these techniques.
Conclusion
This study provides important insights into the generation of counterfactual explanations for machine learning models. The researchers found that the choice of machine learning model has little impact on the counterfactual explanations produced, but that the specific algorithm used and its consideration of plausibility are crucial factors.
The study highlights the need for a more nuanced approach to evaluating counterfactual explanations, moving beyond just quantitative metrics and towards a deeper, qualitative analysis of the generated explanations. This can help identify potential biases and ensure the explanations are meaningful and actionable for users.
As machine learning models become increasingly complex and widely deployed, the ability to provide transparent and interpretable explanations will be crucial. This research contributes to the ongoing efforts to develop robust and reliable counterfactual explanation techniques that can enhance the trustworthiness and accountability of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
Counterfactual Explanations of Black-box Machine Learning Models using Causal Discovery with Applications to Credit Rating
Daisuke Takahashi, Shohei Shimizu, Takuma Tanaka
0
0
Explainable artificial intelligence (XAI) has helped elucidate the internal mechanisms of machine learning algorithms, bolstering their reliability by demonstrating the basis of their predictions. Several XAI models consider causal relationships to explain models by examining the input-output relationships of prediction models and the dependencies between features. The majority of these models have been based their explanations on counterfactual probabilities, assuming that the causal graph is known. However, this assumption complicates the application of such models to real data, given that the causal relationships between features are unknown in most cases. Thus, this study proposed a novel XAI framework that relaxed the constraint that the causal graph is known. This framework leveraged counterfactual probabilities and additional prior information on causal structure, facilitating the integration of a causal graph estimated through causal discovery methods and a black-box classification model. Furthermore, explanatory scores were estimated based on counterfactual probabilities. Numerical experiments conducted employing artificial data confirmed the possibility of estimating the explanatory score more accurately than in the absence of a causal graph. Finally, as an application to real data, we constructed a classification model of credit ratings assigned by Shiga Bank, Shiga prefecture, Japan. We demonstrated the effectiveness of the proposed method in cases where the causal graph is unknown.
4/30/2024
Watermarking Counterfactual Explanations
Hangzhi Guo, Amulya Yadav
0
0
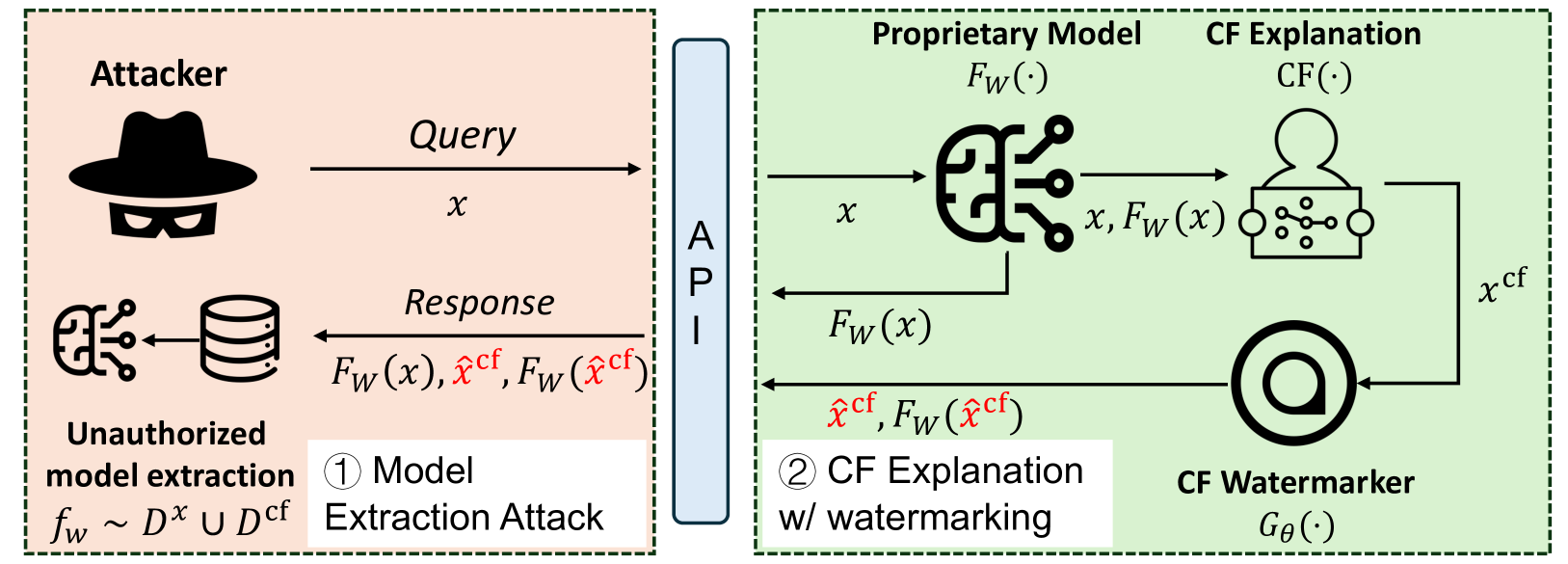
The field of Explainable Artificial Intelligence (XAI) focuses on techniques for providing explanations to end-users about the decision-making processes that underlie modern-day machine learning (ML) models. Within the vast universe of XAI techniques, counterfactual (CF) explanations are often preferred by end-users as they help explain the predictions of ML models by providing an easy-to-understand & actionable recourse (or contrastive) case to individual end-users who are adversely impacted by predicted outcomes. However, recent studies have shown significant security concerns with using CF explanations in real-world applications; in particular, malicious adversaries can exploit CF explanations to perform query-efficient model extraction attacks on proprietary ML models. In this paper, we propose a model-agnostic watermarking framework (for adding watermarks to CF explanations) that can be leveraged to detect unauthorized model extraction attacks (which rely on the watermarked CF explanations). Our novel framework solves a bi-level optimization problem to embed an indistinguishable watermark into the generated CF explanation such that any future model extraction attacks that rely on these watermarked CF explanations can be detected using a null hypothesis significance testing (NHST) scheme, while ensuring that these embedded watermarks do not compromise the quality of the generated CF explanations. We evaluate this framework's performance across a diverse set of real-world datasets, CF explanation methods, and model extraction techniques, and show that our watermarking detection system can be used to accurately identify extracted ML models that are trained using the watermarked CF explanations. Our work paves the way for the secure adoption of CF explanations in real-world applications.
5/30/2024
DiffExplainer: Unveiling Black Box Models Via Counterfactual Generation
Yingying Fang, Shuang Wu, Zihao Jin, Caiwen Xu, Shiyi Wang, Simon Walsh, Guang Yang
0
0
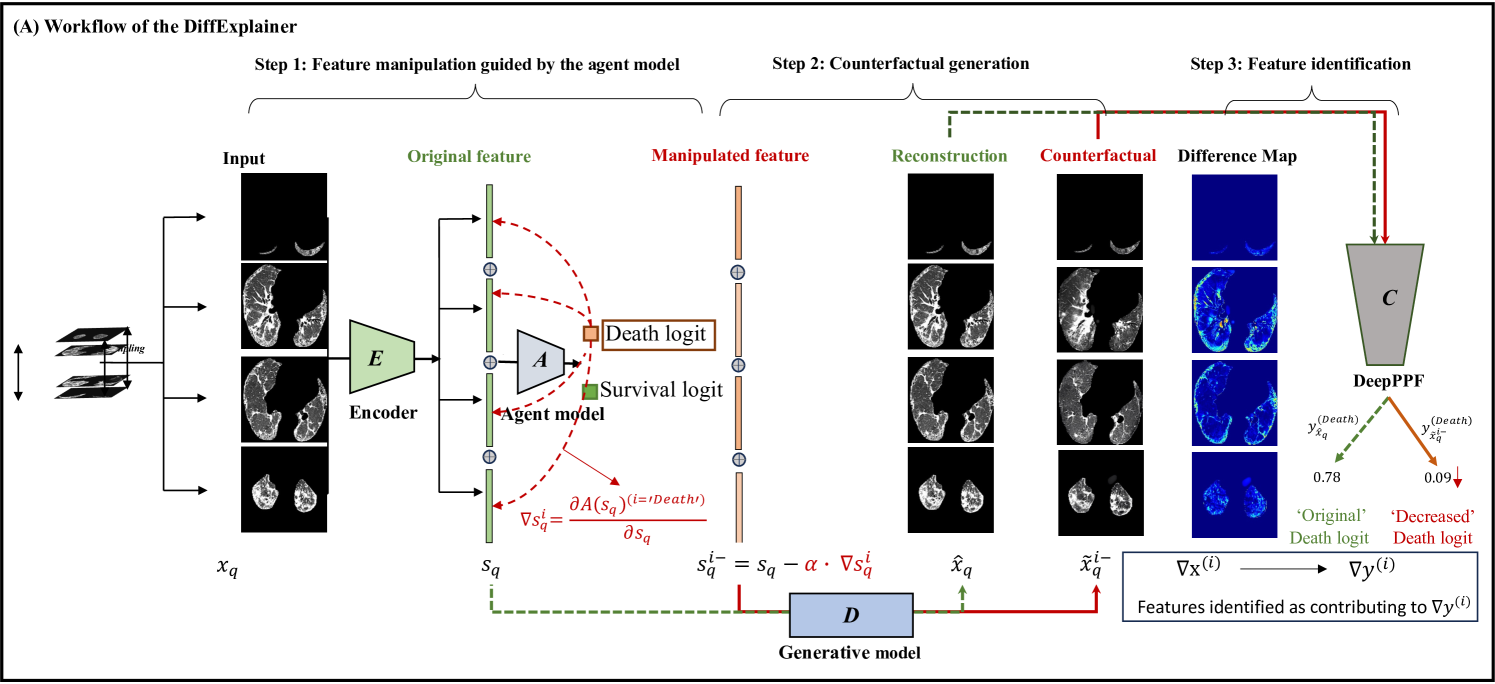
In the field of medical imaging, particularly in tasks related to early disease detection and prognosis, understanding the reasoning behind AI model predictions is imperative for assessing their reliability. Conventional explanation methods encounter challenges in identifying decisive features in medical image classifications, especially when discriminative features are subtle or not immediately evident. To address this limitation, we propose an agent model capable of generating counterfactual images that prompt different decisions when plugged into a black box model. By employing this agent model, we can uncover influential image patterns that impact the black model's final predictions. Through our methodology, we efficiently identify features that influence decisions of the deep black box. We validated our approach in the rigorous domain of medical prognosis tasks, showcasing its efficacy and potential to enhance the reliability of deep learning models in medical image classification compared to existing interpretation methods. The code will be publicly available at https://github.com/ayanglab/DiffExplainer.
6/28/2024
🔍
A Two-Stage Algorithm for Cost-Efficient Multi-instance Counterfactual Explanations
Andr'e Artelt, Andreas Gregoriades
0
0
Counterfactual explanations constitute among the most popular methods for analyzing black-box systems since they can recommend cost-efficient and actionable changes to the input of a system to obtain the desired system output. While most of the existing counterfactual methods explain a single instance, several real-world problems, such as customer satisfaction, require the identification of a single counterfactual that can satisfy multiple instances (e.g. customers) simultaneously. To address this limitation, in this work, we propose a flexible two-stage algorithm for finding groups of instances and computing cost-efficient multi-instance counterfactual explanations. The paper presents the algorithm and its performance against popular alternatives through a comparative evaluation.
5/22/2024