ReLU-KAN: New Kolmogorov-Arnold Networks that Only Need Matrix Addition, Dot Multiplication, and ReLU

0

Sign in to get full access
Overview
- The paper introduces a new type of artificial neural network called ReLU-KAN, which is based on the Kolmogorov-Arnold representation theorem.
- ReLU-KAN networks require only matrix addition, dot multiplication, and ReLU activation, making them computationally efficient.
- The authors demonstrate the universal approximation capabilities of ReLU-KAN networks and show their effectiveness on various tasks.
Plain English Explanation
The paper describes a new kind of artificial neural network called ReLU-KAN, which is inspired by the Kolmogorov-Arnold representation theorem. This theorem states that any continuous function can be represented using just simple operations like addition and multiplication.
The key idea behind ReLU-KAN is that it can perform complex computations using only three basic operations: matrix addition, dot multiplication, and the rectified linear unit (ReLU) activation function. This makes ReLU-KAN networks very efficient and easy to implement compared to traditional neural networks, which often require more complex operations.
The authors show that ReLU-KAN networks can "universally approximate" any continuous function, meaning they can learn to represent any type of input-output relationship. They also demonstrate that ReLU-KAN networks perform well on various tasks, such as time series analysis and wavelet-based signal processing.
Technical Explanation
The paper introduces a new class of neural networks called ReLU-KAN (Rectified Linear Unit Kolmogorov-Arnold Networks) that can be constructed using only matrix addition, dot multiplication, and the ReLU activation function. This is made possible by leveraging the Kolmogorov-Arnold representation theorem, which states that any continuous function can be represented as a superposition of simpler functions.
The authors prove that ReLU-KAN networks can universally approximate any continuous function, meaning they can learn to represent any input-output relationship. They also provide detailed constructions of ReLU-KAN networks and analyze their properties, such as the number of parameters required and their expressive power.
Experiments on various tasks, including time series analysis, wavelet-based signal processing, and structural knowledge representation, demonstrate the effectiveness of ReLU-KAN networks compared to other neural network architectures.
Critical Analysis
The paper provides a solid theoretical foundation for ReLU-KAN networks and demonstrates their practical effectiveness. However, the authors do not discuss potential limitations or challenges in using ReLU-KAN networks, such as their scalability to larger problem sizes or their robustness to noisy or adversarial inputs.
Additionally, while the authors show the universal approximation capabilities of ReLU-KAN networks, they do not explore the trade-offs between the simplicity of the network architecture and its learning efficiency compared to more complex neural network designs.
Further research could investigate the practical implications of the Kolmogorov-Arnold representation theorem for the design of efficient and interpretable neural network architectures, as well as explore the application of ReLU-KAN networks to a wider range of real-world problems.
Conclusion
The ReLU-KAN architecture introduced in this paper represents a promising new direction in neural network design, leveraging the Kolmogorov-Arnold representation theorem to create computationally efficient networks that can universally approximate any continuous function. The simplicity of the ReLU-KAN architecture, combined with its strong theoretical properties and empirical performance, suggests that it could have significant implications for the development of more interpretable and resource-efficient AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ReLU-KAN: New Kolmogorov-Arnold Networks that Only Need Matrix Addition, Dot Multiplication, and ReLU
Qi Qiu, Tao Zhu, Helin Gong, Liming Chen, Huansheng Ning
Limited by the complexity of basis function (B-spline) calculations, Kolmogorov-Arnold Networks (KAN) suffer from restricted parallel computing capability on GPUs. This paper proposes a novel ReLU-KAN implementation that inherits the core idea of KAN. By adopting ReLU (Rectified Linear Unit) and point-wise multiplication, we simplify the design of KAN's basis function and optimize the computation process for efficient CUDA computing. The proposed ReLU-KAN architecture can be readily implemented on existing deep learning frameworks (e.g., PyTorch) for both inference and training. Experimental results demonstrate that ReLU-KAN achieves a 20x speedup compared to traditional KAN with 4-layer networks. Furthermore, ReLU-KAN exhibits a more stable training process with superior fitting ability while preserving the catastrophic forgetting avoidance property of KAN. You can get the code in https://github.com/quiqi/relu_kan
Read more8/13/2024

0
rKAN: Rational Kolmogorov-Arnold Networks
Alireza Afzal Aghaei
The development of Kolmogorov-Arnold networks (KANs) marks a significant shift from traditional multi-layer perceptrons in deep learning. Initially, KANs employed B-spline curves as their primary basis function, but their inherent complexity posed implementation challenges. Consequently, researchers have explored alternative basis functions such as Wavelets, Polynomials, and Fractional functions. In this research, we explore the use of rational functions as a novel basis function for KANs. We propose two different approaches based on Pade approximation and rational Jacobi functions as trainable basis functions, establishing the rational KAN (rKAN). We then evaluate rKAN's performance in various deep learning and physics-informed tasks to demonstrate its practicality and effectiveness in function approximation.
Read more6/21/2024
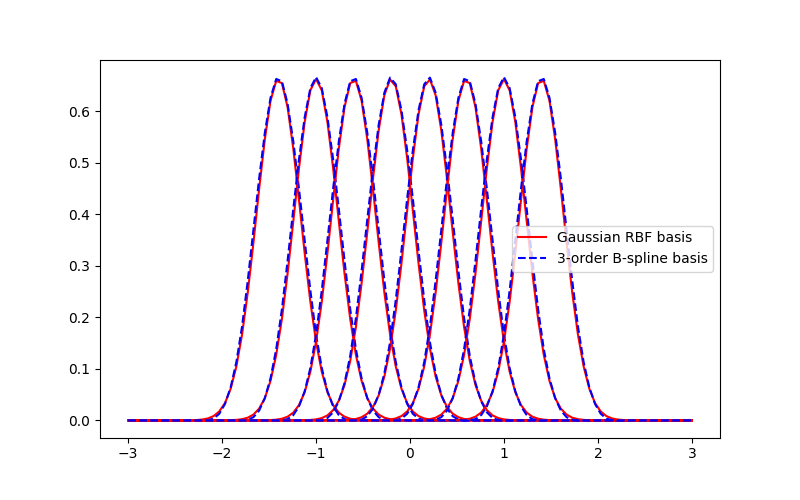
0
Kolmogorov-Arnold Networks are Radial Basis Function Networks
Ziyao Li
This short paper is a fast proof-of-concept that the 3-order B-splines used in Kolmogorov-Arnold Networks (KANs) can be well approximated by Gaussian radial basis functions. Doing so leads to FastKAN, a much faster implementation of KAN which is also a radial basis function (RBF) network.
Read more5/14/2024
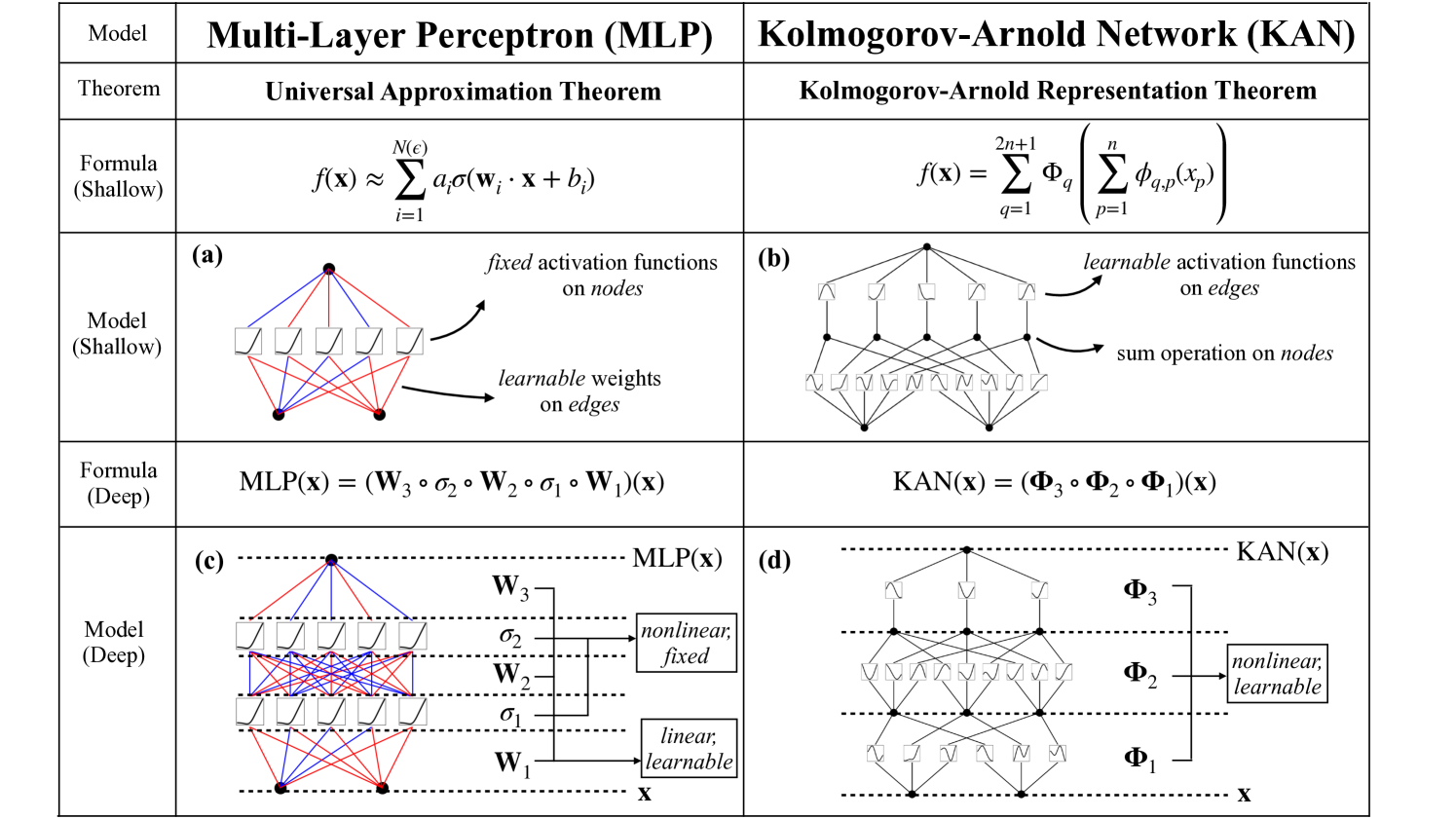
19
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljav{c}i'c, Thomas Y. Hou, Max Tegmark
Inspired by the Kolmogorov-Arnold representation theorem, we propose Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs). While MLPs have fixed activation functions on nodes (neurons), KANs have learnable activation functions on edges (weights). KANs have no linear weights at all -- every weight parameter is replaced by a univariate function parametrized as a spline. We show that this seemingly simple change makes KANs outperform MLPs in terms of accuracy and interpretability. For accuracy, much smaller KANs can achieve comparable or better accuracy than much larger MLPs in data fitting and PDE solving. Theoretically and empirically, KANs possess faster neural scaling laws than MLPs. For interpretability, KANs can be intuitively visualized and can easily interact with human users. Through two examples in mathematics and physics, KANs are shown to be useful collaborators helping scientists (re)discover mathematical and physical laws. In summary, KANs are promising alternatives for MLPs, opening opportunities for further improving today's deep learning models which rely heavily on MLPs.
Read more6/18/2024