Repurposing of the Run 2 CMS High Level Trigger Infrastructure as a Cloud Resource for Offline Computing

0
🤔
Sign in to get full access
Overview
- The CMS experiment at the Large Hadron Collider (LHC) uses a large compute farm to process data from the detector
- This farm, known as the High Level Trigger (HLT), provides around 25,000 job slots for offline computing
- The HLT farm was initially used as an opportunistic resource during gaps in LHC operation, but has since become a permanent part of the CMS computing infrastructure
- The HLT farm is located on-site at the LHC interaction point and is used to perform critical tasks like prompt data reconstruction
- A new "vacuum-like" configuration has been implemented to improve the resource provisioning and usage compared to the previous static VM-based model
Plain English Explanation
The CMS experiment at the Large Hadron Collider (LHC) relies on a large computer system, called the High Level Trigger (HLT) farm, to process the massive amounts of data collected by the CMS detector. This HLT farm provides around 25,000 "job slots" that can be used for various offline computing tasks.
Initially, the HLT farm was used as an occasional resource, only activated during the gaps between LHC operation periods. However, it has since become a permanent and integral part of the CMS computing infrastructure. The HLT farm is located right at the LHC interaction point where the CMS detector is installed, making it a convenient and readily available resource for the experiment.
The HLT farm is used to perform critical tasks like quickly reconstructing the data collected by the CMS detector. This helps the CMS team process the huge stream of data coming from the experiment in a timely manner. The original setup for the HLT farm used statically configured virtual machines (VMs), which provided the necessary functionality.
However, as the HLT farm became a more regular part of the CMS computing landscape, the researchers identified some limitations with the static VM-based approach. To address these issues, they have implemented a new "vacuum-like" configuration for the HLT farm. This new setup aims to improve the way resources are provisioned and used, providing better support for the CMS offline computing needs.
Technical Explanation
The former CMS Run 2 High Level Trigger (HLT) farm is a significant contributor to the overall CMS compute resources, providing around 25,000 job slots for offline computing tasks. This HLT farm was initially used as an opportunistic resource, only active during the gaps between LHC operation periods.
Over time, the HLT farm has become a more permanent and integrated part of the CMS computing infrastructure. It is located on-site at the LHC interaction point 5 (P5), where the CMS detector is installed, making it a readily available resource for the experiment. The HLT farm is configured to support the execution of critical CMS tasks, such as prompt detector data reconstruction, and can be used in combination with the dedicated Tier 0 capacity at CERN to process and absorb peaks in the data stream from the CMS detector.
The initial configuration for the HLT farm was based on statically configured virtual machines (VMs), which provided the required level of functionality. However, regular operations of this cluster revealed certain limitations compared to the resource provisioning and usage model employed in the case of WLCG sites.
To address these limitations, a new "vacuum-like" configuration has been implemented for the HLT farm. This new setup aims to improve the resource provisioning and usage compared to the previous static VM-based model. The paper describes this redeployment work and the commissioning effort for the new setup, as well as the comparison between the former and new models' respective functionalities.
Critical Analysis
The paper provides a detailed overview of the evolution and integration of the CMS HLT farm into the broader CMS computing infrastructure. It highlights the importance of this resource in supporting critical tasks like prompt data reconstruction, and the need to adapt the resource provisioning and usage model to better fit the requirements of the CMS experiment.
One potential area of concern is the reliance on a "vacuum-like" configuration, which may introduce additional complexity or potential issues that are not fully addressed in the paper. The authors do not delve into the specifics of this new setup or provide a comprehensive comparison to the previous static VM-based approach.
Additionally, the paper could have benefited from a more in-depth discussion of the limitations and challenges encountered with the initial VM-based configuration. While the authors mention certain limitations, they do not provide a detailed analysis of the specific issues that led to the adoption of the new "vacuum-like" model.
Further research could explore the long-term performance, reliability, and scalability of the new "vacuum-like" configuration, as well as its broader applicability to other HEP computing infrastructures. Comparison to alternative resource provisioning and management approaches, such as those discussed in Modeling Distributed Computing Infrastructures for HEP Applications or Accelerating Time to Science by Streaming Detector, could also provide valuable insights.
Conclusion
The CMS experiment at the LHC has integrated the former HLT farm as a critical component of its offline computing infrastructure, providing around 25,000 job slots for various computing tasks. The evolution of this resource, from an opportunistic to a more permanent and integrated role, highlights the flexibility and adaptability required in managing large-scale HEP computing resources.
The implementation of a new "vacuum-like" configuration for the HLT farm aims to address the limitations of the previous static VM-based approach, improving resource provisioning and usage to better support the CMS experiment's computing needs. This work demonstrates the ongoing efforts to optimize and streamline the computing infrastructure for HEP experiments, which is essential for maximizing the scientific output and discovery potential of these complex endeavors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
Repurposing of the Run 2 CMS High Level Trigger Infrastructure as a Cloud Resource for Offline Computing
Marco Mascheroni, Antonio Perez-Calero Yzquierdo, Edita Kizinevic, Farrukh Aftab Khan, Hyunwoo Kim, Maria Acosta Flechas, Nikos Tsipinakis, Saqib Haleem, Damiele Spiga, Christoph Wissing, Frank Wurthwein
The former CMS Run 2 High Level Trigger (HLT) farm is one of the largest contributors to CMS compute resources, providing about 25k job slots for offline computing. This CPU farm was initially employed as an opportunistic resource, exploited during inter-fill periods, in the LHC Run 2. Since then, it has become a nearly transparent extension of the CMS capacity at CERN, being located on-site at the LHC interaction point 5 (P5), where the CMS detector is installed. This resource has been configured to support the execution of critical CMS tasks, such as prompt detector data reconstruction. It can therefore be used in combination with the dedicated Tier 0 capacity at CERN, in order to process and absorb peaks in the stream of data coming from the CMS detector. The initial configuration for this resource, based on statically configured VMs, provided the required level of functionality. However, regular operations of this cluster revealed certain limitations compared to the resource provisioning and use model employed in the case of WLCG sites. A new configuration, based on a vacuum-like model, has been implemented for this resource in order to solve the detected shortcomings. This paper reports about this redeployment work on the permanent cloud for an enhanced support to CMS offline computing, comparing the former and new models' respective functionalities, along with the commissioning effort for the new setup.
Read more5/24/2024
📉
0
HPC resources for CMS offline computing: An integration and scalability challenge for the Submission Infrastructure
Antonio Perez-Calero Yzquierdo, Marco Mascheroni, Edita Kizinevic, Farrukh Aftab Khan, Hyunwoo Kim, Maria Acosta Flechas, Nikos Tsipinakis, Saqib Haleem
The computing resource needs of LHC experiments are expected to continue growing significantly during the Run 3 and into the HL-LHC era. The landscape of available resources will also evolve, as High Performance Computing (HPC) and Cloud resources will provide a comparable, or even dominant, fraction of the total compute capacity. The future years present a challenge for the experiments' resource provisioning models, both in terms of scalability and increasing complexity. The CMS Submission Infrastructure (SI) provisions computing resources for CMS workflows. This infrastructure is built on a set of federated HTCondor pools, currently aggregating 400k CPU cores distributed worldwide and supporting the simultaneous execution of over 200k computing tasks. Incorporating HPC resources into CMS computing represents firstly an integration challenge, as HPC centers are much more diverse compared to Grid sites. Secondly, evolving the present SI, dimensioned to harness the current CMS computing capacity, to reach the resource scales required for the HLLHC phase, while maintaining global flexibility and efficiency, will represent an additional challenge for the SI. To preventively address future potential scalability limits, the SI team regularly runs tests to explore the maximum reach of our infrastructure. In this note, the integration of HPC resources into CMS offline computing is summarized, the potential concerns for the SI derived from the increased scale of operations are described, and the most recent results of scalability test on the CMS SI are reported.
Read more5/24/2024
🤷
0
The integration of heterogeneous resources in the CMS Submission Infrastructure for the LHC Run 3 and beyond
Antonio Perez-Calero Yzquierdo, Marco Mascheroni, Edita Kizinevic, Farrukh Aftab Khan, Hyunwoo Kim, Maria Acosta Flechas, Nikos Tsipinakis, Saqib Haleem
While the computing landscape supporting LHC experiments is currently dominated by x86 processors at WLCG sites, this configuration will evolve in the coming years. LHC collaborations will be increasingly employing HPC and Cloud facilities to process the vast amounts of data expected during the LHC Run 3 and the future HL-LHC phase. These facilities often feature diverse compute resources, including alternative CPU architectures like ARM and IBM Power, as well as a variety of GPU specifications. Using these heterogeneous resources efficiently is thus essential for the LHC collaborations reaching their future scientific goals. The Submission Infrastructure (SI) is a central element in CMS Computing, enabling resource acquisition and exploitation by CMS data processing, simulation and analysis tasks. The SI must therefore be adapted to ensure access and optimal utilization of this heterogeneous compute capacity. Some steps in this evolution have been already taken, as CMS is currently using opportunistically a small pool of GPU slots provided mainly at the CMS WLCG sites. Additionally, Power9 processors have been validated for CMS production at the Marconi-100 cluster at CINECA. This note will describe the updated capabilities of the SI to continue ensuring the efficient allocation and use of computing resources by CMS, despite their increasing diversity. The next steps towards a full integration and support of heterogeneous resources according to CMS needs will also be reported.
Read more5/24/2024
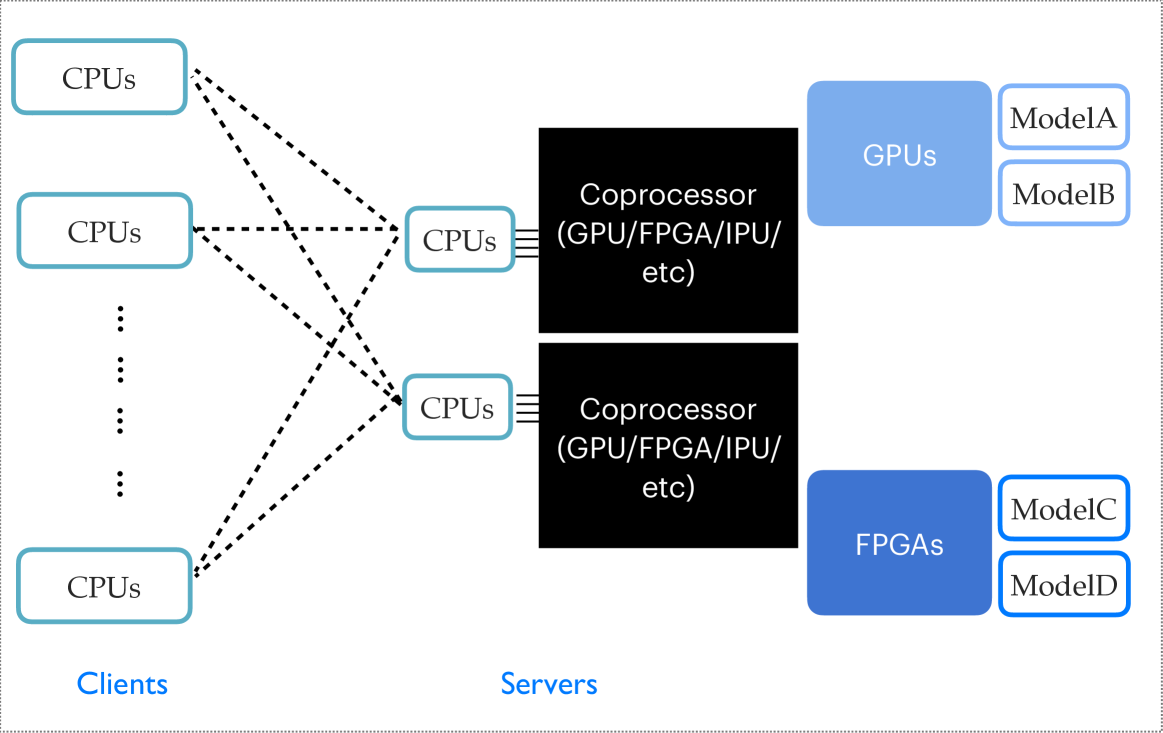
0
Portable acceleration of CMS computing workflows with coprocessors as a service
CMS Collaboration
Computing demands for large scientific experiments, such as the CMS experiment at the CERN LHC, will increase dramatically in the next decades. To complement the future performance increases of software running on central processing units (CPUs), explorations of coprocessor usage in data processing hold great potential and interest. Coprocessors are a class of computer processors that supplement CPUs, often improving the execution of certain functions due to architectural design choices. We explore the approach of Services for Optimized Network Inference on Coprocessors (SONIC) and study the deployment of this as-a-service approach in large-scale data processing. In the studies, we take a data processing workflow of the CMS experiment and run the main workflow on CPUs, while offloading several machine learning (ML) inference tasks onto either remote or local coprocessors, specifically graphics processing units (GPUs). With experiments performed at Google Cloud, the Purdue Tier-2 computing center, and combinations of the two, we demonstrate the acceleration of these ML algorithms individually on coprocessors and the corresponding throughput improvement for the entire workflow. This approach can be easily generalized to different types of coprocessors and deployed on local CPUs without decreasing the throughput performance. We emphasize that the SONIC approach enables high coprocessor usage and enables the portability to run workflows on different types of coprocessors.
Read more9/9/2024