Reputational Algorithm Aversion

0
🔍
Sign in to get full access
Overview
- This research paper explores the concept of "reputational algorithm aversion," which refers to people's reluctance to use algorithmic decision-making systems due to concerns about their reputation.
- The study examines how this aversion affects the adoption and use of algorithmic decision aids, particularly in the context of "credence goods" (products or services where the consumer has difficulty evaluating the quality).
- The paper presents a theoretical model to understand the factors that contribute to reputational algorithm aversion and its implications for the use of algorithmic decision-making tools.
Plain English Explanation
In this research, the authors investigate why people might be hesitant to use algorithms or AI-powered decision-making tools, even when these tools could potentially make better decisions than humans. The key reason they explore is "reputational algorithm aversion" - the idea that people may avoid using algorithms because they're worried about how it might affect their reputation or how others perceive them.
The researchers use the example of "credence goods" to illustrate this concept. Credence goods are products or services where it's difficult for the consumer to evaluate the quality, such as specialized medical treatments or complex home repairs. In these situations, people may be more reluctant to rely on an algorithm's recommendation, even if the algorithm is more accurate, because they're concerned about what others will think if the decision turns out poorly.
The paper presents a theoretical model to understand the factors that contribute to this reputational algorithm aversion and how it might impact the adoption and usage of algorithmic decision-making tools in various contexts. By exploring this issue, the researchers hope to provide insights that can help developers and policymakers design more effective and widely accepted algorithmic systems.
Technical Explanation
The paper develops a theoretical model to examine the concept of "reputational algorithm aversion" and its implications for the use of algorithmic decision aids, particularly in the context of credence goods.
The model assumes that individuals derive utility not only from the outcome of a decision but also from the reputational consequences of that decision. When faced with a decision, individuals can choose to rely on their own judgment or an algorithmic decision aid. The model explores how the relative accuracy of the human decision-maker and the algorithm, as well as the individual's concern for their reputation, affect the likelihood of choosing the algorithmic decision aid.
The key findings from the model include:
- Reputational concerns can lead individuals to avoid using algorithmic decision aids, even when the algorithm is more accurate than the individual's own judgment.
- This aversion is more pronounced for credence goods, where it is difficult for the individual to evaluate the quality of the decision outcome.
- The degree of reputational algorithm aversion depends on factors such as the individual's concern for their reputation, the relative accuracy of the algorithm and the individual, and the visibility of the decision outcome to others.
The model provides a framework for understanding the factors that contribute to reputational algorithm aversion and its implications for the adoption and use of algorithmic decision-making tools in various contexts. The insights from this research can inform the design of algorithmic systems and decision-making processes to address these reputational concerns and promote the effective use of these tools.
Critical Analysis
The paper presents a well-developed theoretical model that offers valuable insights into the concept of reputational algorithm aversion. However, the authors acknowledge that the model relies on several simplifying assumptions, such as perfect information about the relative accuracy of the human and algorithmic decision-makers, and a binary choice between the two.
In practice, the real-world dynamics of reputational concerns and the use of algorithmic decision aids may be more complex. For example, individuals may have imperfect information about the accuracy of the algorithm, or they may consider a range of decision-making strategies beyond the binary choice presented in the model.
Additionally, the paper does not address potential solutions or interventions that could mitigate reputational algorithm aversion. Further research could explore ways to design algorithmic systems or decision-making processes that address these reputational concerns and promote greater acceptance and use of these tools.
Conclusion
This research paper provides a valuable theoretical framework for understanding the concept of "reputational algorithm aversion" and its implications for the adoption and use of algorithmic decision-making tools, particularly in the context of credence goods.
The findings suggest that reputational concerns can lead individuals to avoid using algorithmic decision aids, even when the algorithm is more accurate than their own judgment. This aversion is more pronounced for credence goods, where it is difficult for the individual to evaluate the quality of the decision outcome.
The insights from this research can inform the design of algorithmic systems and decision-making processes to address these reputational concerns and promote the effective use of these tools. By understanding the factors that contribute to reputational algorithm aversion, developers and policymakers can work to create more widely accepted and trusted algorithmic decision-making systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Reputational Algorithm Aversion
Gregory Weitzner
People are often reluctant to incorporate information produced by algorithms into their decisions, a phenomenon called ``algorithm aversion''. This paper shows how algorithm aversion arises when the choice to follow an algorithm conveys information about a human's ability. I develop a model in which workers make forecasts of an uncertain outcome based on their own private information and an algorithm's signal. Low-skill workers receive worse information than the algorithm and hence should always follow the algorithm's signal, while high-skill workers receive better information than the algorithm and should sometimes override it. However, due to reputational concerns, low-skill workers inefficiently override the algorithm to increase the likelihood they are perceived as high-skill. The model provides a fully rational microfoundation for algorithm aversion that aligns with the broad concern that AI systems will displace many types of workers.
Read more8/2/2024
📶
0
Technological Shocks and Algorithmic Decision Aids in Credence Goods Markets
Alexander Erlei, Lukas Meub
In credence goods markets such as health care or repair services, consumers rely on experts with superior information to adequately diagnose and treat them. Experts, however, are constrained in their diagnostic abilities, which hurts market efficiency and consumer welfare. Technological breakthroughs that substitute or complement expert judgments have the potential to alleviate consumer mistreatment. This article studies how competitive experts adopt novel diagnostic technologies when skills are heterogeneously distributed and obfuscated to consumers. We differentiate between novel technologies that increase expert abilities, and algorithmic decision aids that complement expert judgments, but do not affect an expert's personal diagnostic precision. We show that high-ability experts may be incentivized to forego the decision aid in order to escape a pooling equilibrium by differentiating themselves from low-ability experts. Results from an online experiment support our hypothesis, showing that high-ability experts are significantly less likely than low-ability experts to invest into an algorithmic decision aid. Furthermore, we document pervasive under-investments, and no effect on expert honesty.
Read more4/16/2024
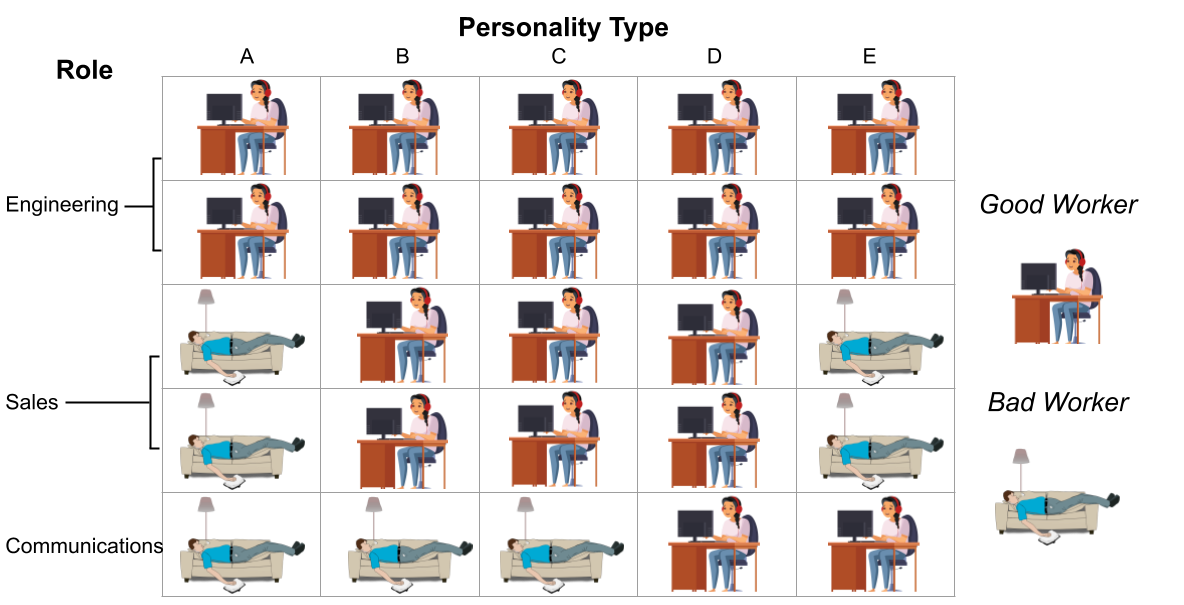
0
Designing Algorithmic Recommendations to Achieve Human-AI Complementarity
Bryce McLaughlin, Jann Spiess
Algorithms frequently assist, rather than replace, human decision-makers. However, the design and analysis of algorithms often focus on predicting outcomes and do not explicitly model their effect on human decisions. This discrepancy between the design and role of algorithmic assistants becomes of particular concern in light of empirical evidence that suggests that algorithmic assistants again and again fail to improve human decisions. In this article, we formalize the design of recommendation algorithms that assist human decision-makers without making restrictive ex-ante assumptions about how recommendations affect decisions. We formulate an algorithmic-design problem that leverages the potential-outcomes framework from causal inference to model the effect of recommendations on a human decision-maker's binary treatment choice. Within this model, we introduce a monotonicity assumption that leads to an intuitive classification of human responses to the algorithm. Under this monotonicity assumption, we can express the human's response to algorithmic recommendations in terms of their compliance with the algorithm and the decision they would take if the algorithm sends no recommendation. We showcase the utility of our framework using an online experiment that simulates a hiring task. We argue that our approach explains the relative performance of different recommendation algorithms in the experiment, and can help design solutions that realize human-AI complementarity.
Read more5/3/2024
🔮
0
Human Expertise in Algorithmic Prediction
Rohan Alur, Manish Raghavan, Devavrat Shah
We introduce a novel framework for incorporating human expertise into algorithmic predictions. Our approach focuses on the use of human judgment to distinguish inputs which `look the same' to any feasible predictive algorithm. We argue that this framing clarifies the problem of human/AI collaboration in prediction tasks, as experts often have access to information -- particularly subjective information -- which is not encoded in the algorithm's training data. We use this insight to develop a set of principled algorithms for selectively incorporating human feedback only when it improves the performance of any feasible predictor. We find empirically that although algorithms often outperform their human counterparts on average, human judgment can significantly improve algorithmic predictions on specific instances (which can be identified ex-ante). In an X-ray classification task, we find that this subset constitutes nearly 30% of the patient population. Our approach provides a natural way of uncovering this heterogeneity and thus enabling effective human-AI collaboration.
Read more5/24/2024