Rethink Arbitrary Style Transfer with Transformer and Contrastive Learning

0

Sign in to get full access
Overview
- Proposes a new approach to arbitrary style transfer using transformer and contrastive learning
- Aims to improve upon existing methods by addressing their limitations
- Introduces a novel architecture and training strategy to achieve better style transfer results
Plain English Explanation
The paper presents a new way to transfer the artistic style from one image to another, known as "arbitrary style transfer." This is a challenging task in computer vision, as it requires the model to capture the unique style of a given artwork and apply it to a different image while preserving the content of that image.
The researchers build on previous work in this area, but they identify some limitations in existing methods. To address these, they propose a transformer-based architecture and a contrastive learning strategy to train the model.
The key idea is to use the transformer's ability to capture long-range dependencies in the content and style images, and then leverage contrastive learning to encourage the model to learn a robust representation of the style. This allows the model to more effectively transfer the style while preserving the content of the target image.
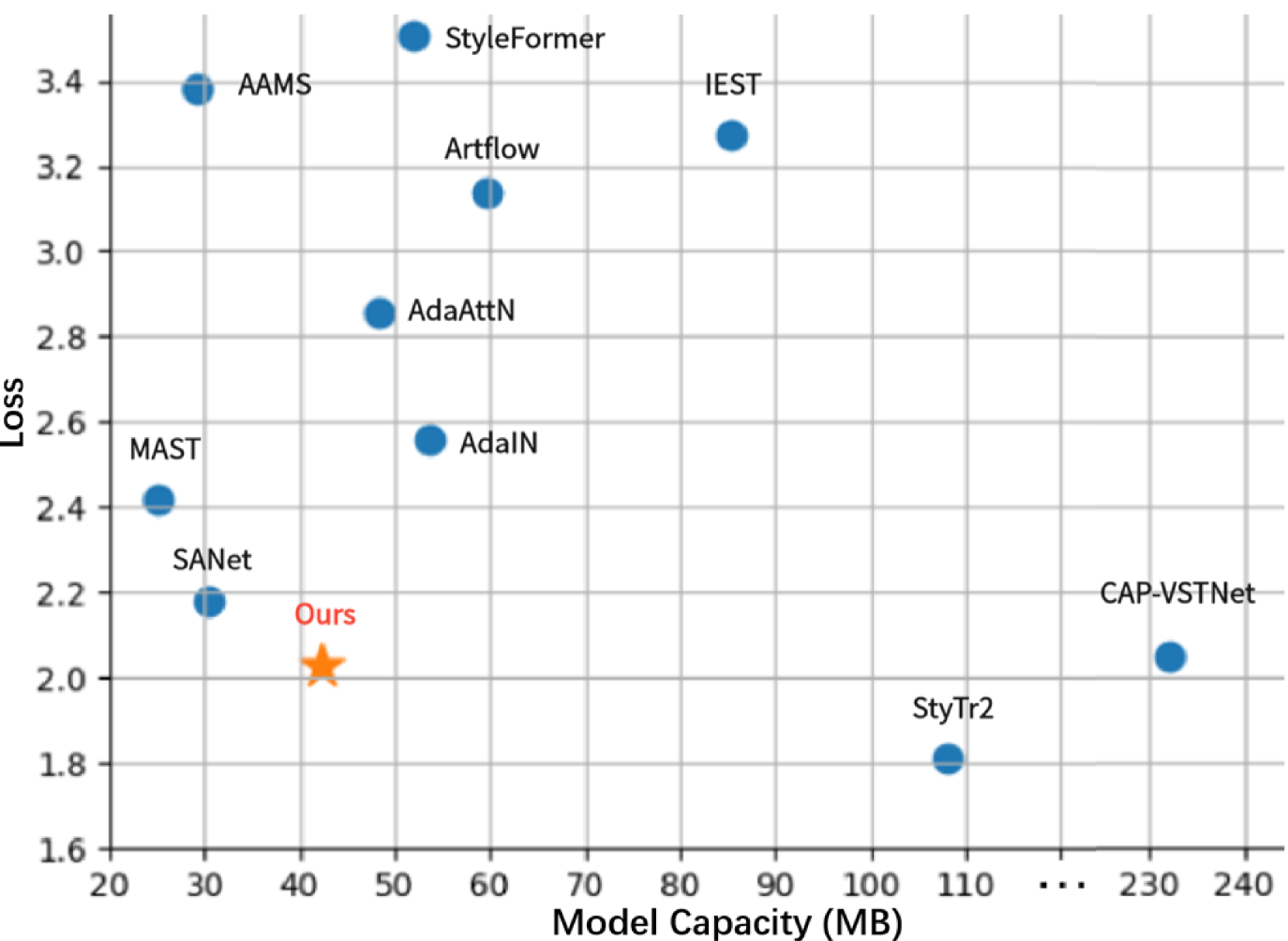
The researchers demonstrate that their approach, which they call "ReTIC," outperforms previous state-of-the-art methods on a range of style transfer benchmarks. This suggests their technique could be useful for applications such as artistic image editing and fashion design.
Technical Explanation
The paper proposes a novel approach to arbitrary style transfer called "ReTIC" (Rethink Arbitrary Style Transfer with Transformer and Contrastive Learning). The key contributions are:
-
Transformer-based Architecture: The researchers develop a transformer-based encoder-decoder network to capture long-range dependencies in the content and style images. This allows the model to better understand the global structure and semantics of the input, which is crucial for effective style transfer.
-
Contrastive Learning: The team introduces a contrastive learning strategy to train the model. This involves learning a robust representation of the style by encouraging the model to maximize the similarity between the encoded style features and minimize the similarity between the encoded content features.
-
Experiments and Evaluation: The authors conduct extensive experiments on several style transfer benchmarks and compare their approach to previous state-of-the-art methods. The results demonstrate that ReTIC outperforms existing techniques in terms of both quantitative metrics and qualitative assessments.
The transformer-based architecture consists of an encoder that extracts features from the content and style images, and a decoder that generates the stylized output image. The contrastive learning objective ensures that the encoded style features are distinct from the encoded content features, enabling the model to better capture and transfer the unique style while preserving the content.
Critical Analysis
The paper makes a compelling case for the effectiveness of the proposed ReTIC approach, providing strong empirical evidence to support its performance advantages over prior methods. However, there are a few potential limitations and areas for further research worth considering:
-
Computational Complexity: Transformer-based models can be computationally intensive, especially for high-resolution images. The authors do not provide a detailed analysis of the computational cost of their approach, which could be an important practical consideration.
-
Generalization to Diverse Styles: While the experiments demonstrate impressive results on the tested benchmarks, it would be valuable to further investigate the model's ability to handle a wider range of artistic styles, including more abstract or unconventional ones.
-
Interpretability and Explainability: As with many deep learning models, the inner workings of the ReTIC approach may be difficult to interpret. Exploring methods to improve the interpretability of the style transfer process could help users better understand and trust the model's decisions.
-
Real-world Applications: The paper focuses on evaluating the model on standard style transfer benchmarks. Assessing its performance and robustness in real-world applications, such as in artistic image editing or fashion design, could provide valuable insights and guide future research.
Overall, the ReTIC approach represents a significant advancement in the field of arbitrary style transfer, and the researchers have made a strong contribution to the literature. Addressing the potential limitations and exploring further applications could help extend the impact of this work.
Conclusion
This paper introduces a novel approach to arbitrary style transfer, called "ReTIC," that leverages a transformer-based architecture and contrastive learning to achieve state-of-the-art performance. By capturing long-range dependencies in the content and style images and learning a robust representation of the style, ReTIC is able to transfer artistic styles more effectively while preserving the content of the target image.
The results demonstrate the potential of this technique for various applications, such as image editing and fashion design. While the paper identifies some promising directions for further research, the ReTIC approach represents a significant step forward in the field of style transfer and could have a meaningful impact on creative industries and the broader computer vision community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethink Arbitrary Style Transfer with Transformer and Contrastive Learning
Zhanjie Zhang, Jiakai Sun, Guangyuan Li, Lei Zhao, Quanwei Zhang, Zehua Lan, Haolin Yin, Wei Xing, Huaizhong Lin, Zhiwen Zuo
Arbitrary style transfer holds widespread attention in research and boasts numerous practical applications. The existing methods, which either employ cross-attention to incorporate deep style attributes into content attributes or use adaptive normalization to adjust content features, fail to generate high-quality stylized images. In this paper, we introduce an innovative technique to improve the quality of stylized images. Firstly, we propose Style Consistency Instance Normalization (SCIN), a method to refine the alignment between content and style features. In addition, we have developed an Instance-based Contrastive Learning (ICL) approach designed to understand the relationships among various styles, thereby enhancing the quality of the resulting stylized images. Recognizing that VGG networks are more adept at extracting classification features and need to be better suited for capturing style features, we have also introduced the Perception Encoder (PE) to capture style features. Extensive experiments demonstrate that our proposed method generates high-quality stylized images and effectively prevents artifacts compared with the existing state-of-the-art methods.
Read more4/23/2024

0
InstantStyle-Plus: Style Transfer with Content-Preserving in Text-to-Image Generation
Haofan Wang, Peng Xing, Renyuan Huang, Hao Ai, Qixun Wang, Xu Bai
Style transfer is an inventive process designed to create an image that maintains the essence of the original while embracing the visual style of another. Although diffusion models have demonstrated impressive generative power in personalized subject-driven or style-driven applications, existing state-of-the-art methods still encounter difficulties in achieving a seamless balance between content preservation and style enhancement. For example, amplifying the style's influence can often undermine the structural integrity of the content. To address these challenges, we deconstruct the style transfer task into three core elements: 1) Style, focusing on the image's aesthetic characteristics; 2) Spatial Structure, concerning the geometric arrangement and composition of visual elements; and 3) Semantic Content, which captures the conceptual meaning of the image. Guided by these principles, we introduce InstantStyle-Plus, an approach that prioritizes the integrity of the original content while seamlessly integrating the target style. Specifically, our method accomplishes style injection through an efficient, lightweight process, utilizing the cutting-edge InstantStyle framework. To reinforce the content preservation, we initiate the process with an inverted content latent noise and a versatile plug-and-play tile ControlNet for preserving the original image's intrinsic layout. We also incorporate a global semantic adapter to enhance the semantic content's fidelity. To safeguard against the dilution of style information, a style extractor is employed as discriminator for providing supplementary style guidance. Codes will be available at https://github.com/instantX-research/InstantStyle-Plus.
Read more7/2/2024
0
Puff-Net: Efficient Style Transfer with Pure Content and Style Feature Fusion Network
Sizhe Zheng, Pan Gao, Peng Zhou, Jie Qin
Style transfer aims to render an image with the artistic features of a style image, while maintaining the original structure. Various methods have been put forward for this task, but some challenges still exist. For instance, it is difficult for CNN-based methods to handle global information and long-range dependencies between input images, for which transformer-based methods have been proposed. Although transformers can better model the relationship between content and style images, they require high-cost hardware and time-consuming inference. To address these issues, we design a novel transformer model that includes only the encoder, thus significantly reducing the computational cost. In addition, we also find that existing style transfer methods may lead to images under-stylied or missing content. In order to achieve better stylization, we design a content feature extractor and a style feature extractor, based on which pure content and style images can be fed to the transformer. Finally, we propose a novel network termed Puff-Net, i.e., pure content and style feature fusion network. Through qualitative and quantitative experiments, we demonstrate the advantages of our model compared to state-of-the-art ones in the literature.
Read more5/31/2024
⚙️
0
CLAP: Isolating Content from Style through Contrastive Learning with Augmented Prompts
Yichao Cai, Yuhang Liu, Zhen Zhang, Javen Qinfeng Shi
Contrastive vision-language models, such as CLIP, have garnered considerable attention for various dowmsteam tasks, mainly due to the remarkable ability of the learned features for generalization. However, the features they learned often blend content and style information, which somewhat limits their generalization capabilities under distribution shifts. To address this limitation, we adopt a causal generative perspective for multimodal data and propose contrastive learning with data augmentation to disentangle content features from the original representations. To achieve this, we begin with exploring image augmentation techniques and develop a method to seamlessly integrate them into pre-trained CLIP-like models to extract pure content features. Taking a step further, recognizing the inherent semantic richness and logical structure of text data, we explore the use of text augmentation to isolate latent content from style features. This enables CLIP-like model's encoders to concentrate on latent content information, refining the learned representations by pre-trained CLIP-like models. Our extensive experiments across diverse datasets demonstrate significant improvements in zero-shot and few-shot classification tasks, alongside enhanced robustness to various perturbations. These results underscore the effectiveness of our proposed methods in refining vision-language representations and advancing the state-of-the-art in multimodal learning.
Read more7/12/2024