Rethinking The Uniformity Metric in Self-Supervised Learning

0

Sign in to get full access
Overview
- This paper examines the "uniformity" metric, a common evaluation used in self-supervised learning (SSL) algorithms.
- The authors argue that the uniformity metric has significant flaws and propose an alternative metric called "average pairwise similarity" (APS) that better captures the desired properties of SSL representations.
- The paper presents theoretical analysis and empirical results demonstrating the advantages of APS over uniformity.
Plain English Explanation
Self-supervised learning is a powerful technique used to train AI models on large datasets without the need for manual labeling. The key idea is to have the model learn useful representations by solving self-imposed "pretext" tasks, such as predicting the relative position of two image patches.
One common way to evaluate the quality of the learned representations is the "uniformity" metric, which measures how evenly distributed the representations are in the feature space. The paper argues that this metric has significant issues - for example, it can be optimized by simply pushing all representations to be very similar, even if they don't capture meaningful information about the data.
The authors propose an alternative metric called "average pairwise similarity" (APS) that they believe better captures the desired properties of good SSL representations. APS measures the average similarity between all pairs of representations, rather than just looking at the overall distribution. This encourages the model to learn diverse, informative representations that are still somewhat related to each other.
Through theoretical analysis and experimental results, the paper demonstrates that APS is a more reliable and informative metric than uniformity for evaluating SSL algorithms. The authors hope this work will lead to better design and analysis of self-supervised learning systems.
Technical Explanation
The paper first provides background on self-supervised representation learning, explaining how models are trained to solve pretext tasks in order to learn useful features from unlabeled data.
The key technical contribution is a critical analysis of the commonly used "uniformity" metric for evaluating SSL representations. The authors show that uniformity can be optimized in undesirable ways, such as by pushing all representations to be very similar to each other. This defeats the purpose of learning diverse, informative features.
To address this, the paper proposes a new metric called "average pairwise similarity" (APS). APS measures the average similarity between all pairs of representations, rather than just looking at the overall distribution. This encourages the model to learn a diverse set of representations that are still somewhat related to each other.
The authors provide theoretical analysis demonstrating the advantages of APS over uniformity. They show that APS better captures properties like class separability and semantic similarity, which are important for downstream tasks.
Extensive experiments on image classification benchmarks validate the superiority of APS. The results show that models optimized for APS outperform those optimized for uniformity, both in terms of linear evaluation and transfer learning performance.
Critical Analysis
The paper presents a thoughtful critique of the uniformity metric and a compelling alternative in APS. The theoretical and empirical analysis is rigorous and the insights are valuable for the self-supervised learning community.
That said, the paper does not address certain limitations or caveats. For example, the authors acknowledge that APS can be sensitive to hyperparameter choices, and it's unclear how robust the metric is to factors like dataset bias or distribution shift.
Additionally, the paper focuses solely on evaluating representation quality, but does not consider other important factors in SSL like training stability, computational efficiency, or downstream task performance. A more holistic evaluation would be ideal.
Overall, this work makes a strong case for rethinking uniformity and exploring alternative metrics like APS. However, further research is needed to fully understand the strengths, weaknesses, and appropriate use cases of these different evaluation approaches.
Conclusion
This paper makes a compelling argument for reconsidering the uniformity metric, a widely used evaluation method in self-supervised learning. The authors demonstrate significant flaws in uniformity and propose a new metric, average pairwise similarity (APS), that better captures desirable properties of learned representations.
Through theoretical analysis and empirical results, the paper shows that APS is a more reliable and informative metric than uniformity. Models optimized for APS exhibit superior performance on downstream tasks, suggesting that this new evaluation approach can lead to better self-supervised learning algorithms.
The insights from this work have important implications for the design and analysis of self-supervised systems. By rethinking core evaluation metrics, the authors hope to spur the development of more robust and effective representation learning methods - a crucial step towards realizing the full potential of unsupervised AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethinking The Uniformity Metric in Self-Supervised Learning
Xianghong Fang, Jian Li, Qiang Sun, Benyou Wang
Uniformity plays an important role in evaluating learned representations, providing insights into self-supervised learning. In our quest for effective uniformity metrics, we pinpoint four principled properties that such metrics should possess. Namely, an effective uniformity metric should remain invariant to instance permutations and sample replications while accurately capturing feature redundancy and dimensional collapse. Surprisingly, we find that the uniformity metric proposed by citet{Wang2020UnderstandingCR} fails to satisfy the majority of these properties. Specifically, their metric is sensitive to sample replications, and can not account for feature redundancy and dimensional collapse correctly. To overcome these limitations, we introduce a new uniformity metric based on the Wasserstein distance, which satisfies all the aforementioned properties. Integrating this new metric in existing self-supervised learning methods effectively mitigates dimensional collapse and consistently improves their performance on downstream tasks involving CIFAR-10 and CIFAR-100 datasets. Code is available at url{https://github.com/statsle/WassersteinSSL}.
Read more4/29/2024
👁️
0
Wasserstein Distortion: Unifying Fidelity and Realism
Yang Qiu, Aaron B. Wagner, Johannes Ball'e, Lucas Theis
We introduce a distortion measure for images, Wasserstein distortion, that simultaneously generalizes pixel-level fidelity on the one hand and realism or perceptual quality on the other. We show how Wasserstein distortion reduces to a pure fidelity constraint or a pure realism constraint under different parameter choices and discuss its metric properties. Pairs of images that are close under Wasserstein distortion illustrate its utility. In particular, we generate random textures that have high fidelity to a reference texture in one location of the image and smoothly transition to an independent realization of the texture as one moves away from this point. Wasserstein distortion attempts to generalize and unify prior work on texture generation, image realism and distortion, and models of the early human visual system, in the form of an optimizable metric in the mathematical sense.
Read more4/1/2024
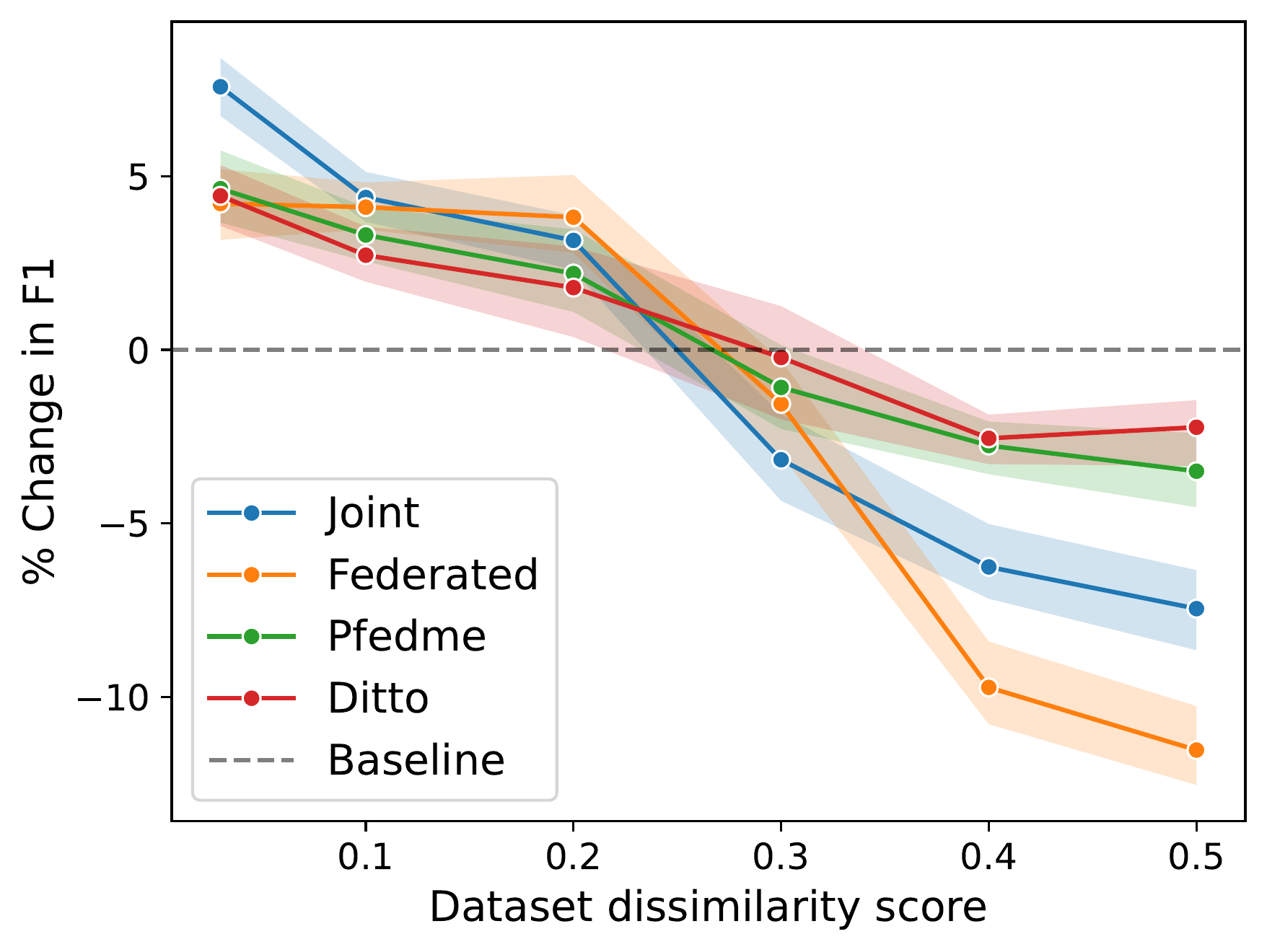
0
A Universal Metric of Dataset Similarity for Cross-silo Federated Learning
Ahmed Elhussein, Gamze Gursoy
Federated Learning is increasingly used in domains such as healthcare to facilitate collaborative model training without data-sharing. However, datasets located in different sites are often non-identically distributed, leading to degradation of model performance in FL. Most existing methods for assessing these distribution shifts are limited by being dataset or task-specific. Moreover, these metrics can only be calculated by exchanging data, a practice restricted in many FL scenarios. To address these challenges, we propose a novel metric for assessing dataset similarity. Our metric exhibits several desirable properties for FL: it is dataset-agnostic, is calculated in a privacy-preserving manner, and is computationally efficient, requiring no model training. In this paper, we first establish a theoretical connection between our metric and training dynamics in FL. Next, we extensively evaluate our metric on a range of datasets including synthetic, benchmark, and medical imaging datasets. We demonstrate that our metric shows a robust and interpretable relationship with model performance and can be calculated in privacy-preserving manner. As the first federated dataset similarity metric, we believe this metric can better facilitate successful collaborations between sites.
Read more4/30/2024

0
Distributional Reduction: Unifying Dimensionality Reduction and Clustering with Gromov-Wasserstein
Hugues Van Assel, C'edric Vincent-Cuaz, Nicolas Courty, R'emi Flamary, Pascal Frossard, Titouan Vayer
Unsupervised learning aims to capture the underlying structure of potentially large and high-dimensional datasets. Traditionally, this involves using dimensionality reduction (DR) methods to project data onto lower-dimensional spaces or organizing points into meaningful clusters (clustering). In this work, we revisit these approaches under the lens of optimal transport and exhibit relationships with the Gromov-Wasserstein problem. This unveils a new general framework, called distributional reduction, that recovers DR and clustering as special cases and allows addressing them jointly within a single optimization problem. We empirically demonstrate its relevance to the identification of low-dimensional prototypes representing data at different scales, across multiple image and genomic datasets.
Read more5/24/2024