Retrieval-Enhanced Visual Prompt Learning for Few-shot Classification
2306.02243
0
0
🏷️
Abstract
Prompt learning has become a popular approach for adapting large vision-language models, such as CLIP, to downstream tasks. Typically, prompt learning relies on a fixed prompt token or an input-conditional token to fit a small amount of data under full supervision. While this paradigm can generalize to a certain range of unseen classes, it may struggle when domain gap increases, such as in fine-grained classification and satellite image segmentation. To address this limitation, we propose Retrieval-enhanced Prompt learning (RePrompt), which introduces retrieval mechanisms to cache the knowledge representations from downstream tasks. we first construct a retrieval database from training examples, or from external examples when available. We then integrate this retrieval-enhanced mechanism into various stages of a simple prompt learning baseline. By referencing similar samples in the training set, the enhanced model is better able to adapt to new tasks with few samples. Our extensive experiments over 15 vision datasets, including 11 downstream tasks with few-shot setting and 4 domain generalization benchmarks, demonstrate that RePrompt achieves considerably improved performance. Our proposed approach provides a promising solution to the challenges faced by prompt learning when domain gap increases. The code and models will be available.
Create account to get full access
Overview
- Large vision-language models like CLIP have been adapted to downstream tasks through prompt learning
- Prompt learning typically uses a fixed prompt or input-conditional token to fit a small amount of data
- This approach can struggle when the domain gap increases, such as in fine-grained classification or satellite image segmentation
- The paper proposes Retrieval-enhanced Prompt learning (RePrompt), which integrates retrieval mechanisms to better adapt to new tasks with few samples
Plain English Explanation
Large AI models like CLIP have been trained on massive amounts of data to understand language and vision. To use these models for specific tasks, researchers often rely on a technique called prompt learning. Prompt learning involves providing the model with a short "prompt" - a phrase or sentence that instructs the model on what to do.
For example, to use CLIP for image classification, a prompt like "This is a photo of a [object]" could be used, where [object] is a placeholder for the class you want to identify. The model can then be fine-tuned on a small amount of data using this prompt.
While prompt learning can be effective, it has limitations. If the new task is very different from the original training data, the model may struggle to adapt. This could happen in specialized fields like fine-grained classification or satellite image segmentation.
To address this, the researchers propose a new approach called Retrieval-enhanced Prompt learning (RePrompt). RePrompt adds a "retrieval" mechanism to the prompt learning process. This means the model can reference similar examples it has seen before, either from the training data or from external sources, to better adapt to the new task.
By drawing on this additional knowledge, the RePrompt model is able to perform better on tasks with limited training data, even when the domain is quite different from the original model training. The researchers demonstrate significant improvements across a wide range of vision datasets and benchmarks.
Technical Explanation
The core idea behind Retrieval-enhanced Prompt learning (RePrompt) is to integrate retrieval mechanisms into the prompt learning process to better adapt to new tasks with few training samples.
Typically, prompt learning relies on a fixed prompt token or an input-conditional token to fit a small amount of data under full supervision. While this can generalize to some unseen classes, it struggles when the domain gap increases, such as in fine-grained classification or satellite image segmentation.
To address this, the RePrompt approach first constructs a retrieval database from the training examples, or from external examples if available. It then integrates this retrieval-enhanced mechanism into various stages of a simple prompt learning baseline.
By referencing similar samples in the training set or external data, the enhanced model is better able to adapt to new tasks with few samples. The researchers evaluate RePrompt across 15 vision datasets, including 11 downstream tasks with few-shot settings and 4 domain generalization benchmarks. The results demonstrate that RePrompt achieves considerable performance improvements compared to standard prompt learning.
This approach provides a promising solution to the challenges faced by prompt learning when the domain gap increases, as the retrieval-enhanced model can better leverage relevant knowledge to adapt to new tasks with limited data.
Critical Analysis
The paper presents a compelling approach to address the limitations of prompt learning, particularly when dealing with significant domain shifts. By incorporating retrieval mechanisms, RePrompt demonstrates the ability to better leverage relevant knowledge from training or external data to adapt to new tasks with few samples.
However, the paper does not delve into potential limitations or caveats of the RePrompt approach. For example, the performance gain may depend on the quality and relevance of the retrieval database, which could be challenging to curate in some scenarios. Additionally, the computational overhead of the retrieval process is not discussed, which could be a concern for real-world deployments.
Further research could explore the robustness of RePrompt to different types of domain shifts, the impact of the retrieval database size and composition, and potential trade-offs between performance and computational efficiency. Investigating how RePrompt compares to other few-shot or domain adaptation techniques, such as convolutional prompting, could also provide valuable insights.
Overall, the RePrompt approach is a promising step towards improving the generalization capabilities of prompt learning, particularly in challenging domains. However, deeper analysis of its limitations and further exploration of its potential applications and enhancements would be valuable for the research community.
Conclusion
The paper introduces Retrieval-enhanced Prompt learning (RePrompt), a novel approach that integrates retrieval mechanisms into the prompt learning process to better adapt large vision-language models to downstream tasks with limited training data.
By referencing similar examples from the training set or external sources, the RePrompt model is able to leverage relevant knowledge to perform well on new tasks, even when the domain gap is significant. The extensive experiments across 15 vision datasets demonstrate the considerable performance improvements of RePrompt compared to standard prompt learning.
This research provides a promising solution to the challenges faced by prompt learning when dealing with diverse domains and limited data, opening up new avenues for applying large pre-trained models to a broader range of real-world applications. Further exploration of RePrompt's capabilities, limitations, and potential enhancements could lead to even more impactful advancements in the field of few-shot and domain-adaptive learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
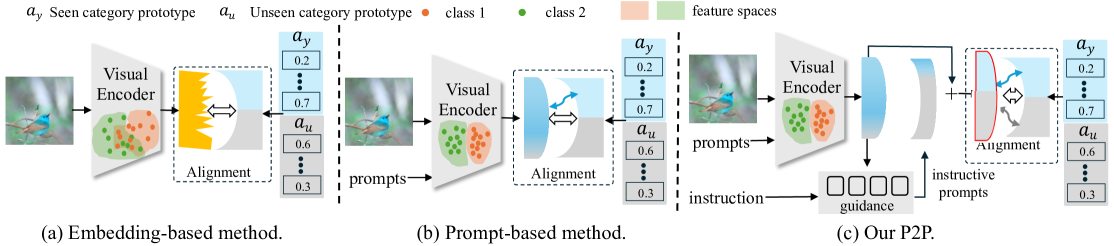
Instructing Prompt-to-Prompt Generation for Zero-Shot Learning
Man Liu, Huihui Bai, Feng Li, Chunjie Zhang, Yunchao Wei, Meng Wang, Tat-Seng Chua, Yao Zhao
0
0
Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a textbf{P}rompt-to-textbf{P}rompt generation methodology (textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.
6/6/2024
✨
New!Progressive Visual Prompt Learning with Contrastive Feature Re-formation
Chen Xu, Yuhan Zhu, Haocheng Shen, Fengyuan Shi, Boheng Chen, Yixuan Liao, Xiaoxin Chen, Limin Wang
0
0
Prompt learning has been designed as an alternative to fine-tuning for adapting Vision-language (V-L) models to the downstream tasks. Previous works mainly focus on text prompt while visual prompt works are limited for V-L models. The existing visual prompt methods endure either mediocre performance or unstable training process, indicating the difficulty of visual prompt learning. In this paper, we propose a new Progressive Visual Prompt (ProVP) structure to strengthen the interactions among prompts of different layers. More importantly, our ProVP could effectively propagate the image embeddings to deep layers and behave partially similar to an instance adaptive prompt method. To alleviate generalization deterioration, we further propose a new contrastive feature re-formation, which prevents the serious deviation of the prompted visual feature from the fixed CLIP visual feature distribution. Combining both, our method (ProVP-Ref) is evaluated on 11 image benchmark datasets and achieves 7/11 state-of-theart results on both few-shot and base-to-novel settings. To the best of our knowledge, we are the first to demonstrate the superior performance of visual prompts in V-L models to previous prompt-based methods in downstream tasks. Meanwhile, it implies that our ProVP-Ref shows the best capability to adapt and to generalize.
7/2/2024

Conditional Prototype Rectification Prompt Learning
Haoxing Chen, Yaohui Li, Zizheng Huang, Yan Hong, Zhuoer Xu, Zhangxuan Gu, Jun Lan, Huijia Zhu, Weiqiang Wang
0
0
Pre-trained large-scale vision-language models (VLMs) have acquired profound understanding of general visual concepts. Recent advancements in efficient transfer learning (ETL) have shown remarkable success in fine-tuning VLMs within the scenario of limited data, introducing only a few parameters to harness task-specific insights from VLMs. Despite significant progress, current leading ETL methods tend to overfit the narrow distributions of base classes seen during training and encounter two primary challenges: (i) only utilizing uni-modal information to modeling task-specific knowledge; and (ii) using costly and time-consuming methods to supplement knowledge. To address these issues, we propose a Conditional Prototype Rectification Prompt Learning (CPR) method to correct the bias of base examples and augment limited data in an effective way. Specifically, we alleviate overfitting on base classes from two aspects. First, each input image acquires knowledge from both textual and visual prototypes, and then generates sample-conditional text tokens. Second, we extract utilizable knowledge from unlabeled data to further refine the prototypes. These two strategies mitigate biases stemming from base classes, yielding a more effective classifier. Extensive experiments on 11 benchmark datasets show that our CPR achieves state-of-the-art performance on both few-shot classification and base-to-new generalization tasks. Our code is avaliable at url{https://github.com/chenhaoxing/CPR}.
4/16/2024
🖼️
Pseudo-Prompt Generating in Pre-trained Vision-Language Models for Multi-Label Medical Image Classification
Yaoqin Ye, Junjie Zhang, Hongwei Shi
0
0
The task of medical image recognition is notably complicated by the presence of varied and multiple pathological indications, presenting a unique challenge in multi-label classification with unseen labels. This complexity underlines the need for computer-aided diagnosis methods employing multi-label zero-shot learning. Recent advancements in pre-trained vision-language models (VLMs) have showcased notable zero-shot classification abilities on medical images. However, these methods have limitations on leveraging extensive pre-trained knowledge from broader image datasets, and often depend on manual prompt construction by expert radiologists. By automating the process of prompt tuning, prompt learning techniques have emerged as an efficient way to adapt VLMs to downstream tasks. Yet, existing CoOp-based strategies fall short in performing class-specific prompts on unseen categories, limiting generalizability in fine-grained scenarios. To overcome these constraints, we introduce a novel prompt generation approach inspirited by text generation in natural language processing (NLP). Our method, named Pseudo-Prompt Generating (PsPG), capitalizes on the priori knowledge of multi-modal features. Featuring a RNN-based decoder, PsPG autoregressively generates class-tailored embedding vectors, i.e., pseudo-prompts. Comparative evaluations on various multi-label chest radiograph datasets affirm the superiority of our approach against leading medical vision-language and multi-label prompt learning methods. The source code is available at https://github.com/fallingnight/PsPG
5/13/2024