Unsupervised Image Prior via Prompt Learning and CLIP Semantic Guidance for Low-Light Image Enhancement
2405.11478
0
0

Abstract
Currently, low-light conditions present a significant challenge for machine cognition. In this paper, rather than optimizing models by assuming that human and machine cognition are correlated, we use zero-reference low-light enhancement to improve the performance of downstream task models. We propose to improve the zero-reference low-light enhancement method by leveraging the rich visual-linguistic CLIP prior without any need for paired or unpaired normal-light data, which is laborious and difficult to collect. We propose a simple but effective strategy to learn prompts that help guide the enhancement method and experimentally show that the prompts learned without any need for normal-light data improve image contrast, reduce over-enhancement, and reduce noise over-amplification. Next, we propose to reuse the CLIP model for semantic guidance via zero-shot open vocabulary classification to optimize low-light enhancement for task-based performance rather than human visual perception. We conduct extensive experimental results showing that the proposed method leads to consistent improvements across various datasets regarding task-based performance and compare our method against state-of-the-art methods, showing favorable results across various low-light datasets.
Create account to get full access
Overview
- This paper presents an unsupervised image enhancement method that uses prompt learning and CLIP semantic guidance to improve low-light image quality.
- The proposed approach does not require any paired training data, making it more accessible than supervised methods.
- Key innovations include using prompt learning to generate an image prior and CLIP to provide semantic guidance for the enhancement process.
Plain English Explanation
The researchers developed a new way to make low-light images look better without needing special training data. Most existing methods require having lots of examples of good and bad images, which can be hard to get. Instead, this approach uses a technique called "prompt learning" to generate an initial image prior, and then refines that prior using guidance from a powerful image understanding model called CLIP.
The prompt learning part means they train a model to generate an initial enhanced image just from a short textual description, or "prompt," of what the desired output should look like. This acts as a starting point for the enhancement. Then, the CLIP model is used to analyze the image and provide semantic guidance, helping the system understand things like the content, objects, and overall scene. This allows the final enhanced image to better match the intended look and feel.
By combining these two key ideas - prompt learning and CLIP guidance - the researchers were able to create an unsupervised image enhancement system that works well without needing large datasets of example images. This makes the method more accessible and applicable in real-world scenarios where obtaining high-quality training data can be challenging.
Technical Explanation
The paper proposes an unsupervised image enhancement method that leverages prompt learning and CLIP semantic guidance to improve the quality of low-light images.
The core innovation is using prompt learning to generate an initial image prior, which is then refined through an optimization process guided by CLIP. Specifically, the system first trains a prompt-based generator to produce an enhanced image from a textual description. This provides a starting point for the enhancement.
Next, the low-light input image and the prompt-generated image are passed through a pre-trained CLIP model. CLIP extracts semantic features that capture the content, objects, and overall scene information. These CLIP features are used to define a perceptual loss that encourages the final enhanced output to better match the desired semantics.
The enhancement process then iteratively optimizes the input image to minimize this perceptual loss, effectively using the CLIP guidance to refine the initial prompt-generated prior. This allows the method to produce high-quality enhanced images without requiring any paired training data.
The authors demonstrate the effectiveness of their approach through experiments on various low-light image datasets, showing significant improvements over prior unsupervised and supervised methods.
Critical Analysis
The paper presents a clever and well-designed unsupervised image enhancement technique that leverages recent advancements in CLIP-based semantic guidance and prompt learning.
One limitation is that the method relies on the quality and capabilities of the pre-trained CLIP model, which may not capture all the relevant semantic information needed for optimal enhancement. Additionally, the prompt-based prior generation could be sensitive to the specific prompts used, and may not work as well for some types of low-light images.
Further research could explore ways to make the prompt learning more robust, potentially by incorporating techniques like RAVE to better isolate content and style. Investigating methods to adapt or fine-tune the CLIP model for the specific low-light enhancement task could also be valuable.
Overall, this paper presents an intriguing unsupervised approach that makes progress on an important problem in computer vision. The combination of prompt learning and CLIP guidance is a clever idea that could inspire further research in this direction.
Conclusion
This paper introduces an unsupervised image enhancement method that uses prompt learning and CLIP semantic guidance to improve the quality of low-light images. By generating an initial image prior through prompt learning and then refining it using CLIP-based perceptual losses, the system is able to produce high-quality enhanced outputs without requiring any paired training data.
The key innovations - leveraging prompt learning and CLIP semantic guidance - make this approach more accessible than supervised methods that need large datasets of example images. This could enable more widespread application of image enhancement techniques, especially in scenarios where obtaining high-quality training data is challenging.
While the method has some limitations, the overall concept and results demonstrate the potential of combining recent advancements in language models, vision-language models, and unsupervised optimization for image enhancement tasks. Further research in this direction could lead to even more powerful and widely applicable low-light image enhancement solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Rethinking Prior Information Generation with CLIP for Few-Shot Segmentation
Jin Wang, Bingfeng Zhang, Jian Pang, Honglong Chen, Weifeng Liu
0
0
Few-shot segmentation remains challenging due to the limitations of its labeling information for unseen classes. Most previous approaches rely on extracting high-level feature maps from the frozen visual encoder to compute the pixel-wise similarity as a key prior guidance for the decoder. However, such a prior representation suffers from coarse granularity and poor generalization to new classes since these high-level feature maps have obvious category bias. In this work, we propose to replace the visual prior representation with the visual-text alignment capacity to capture more reliable guidance and enhance the model generalization. Specifically, we design two kinds of training-free prior information generation strategy that attempts to utilize the semantic alignment capability of the Contrastive Language-Image Pre-training model (CLIP) to locate the target class. Besides, to acquire more accurate prior guidance, we build a high-order relationship of attention maps and utilize it to refine the initial prior information. Experiments on both the PASCAL-5{i} and COCO-20{i} datasets show that our method obtains a clearly substantial improvement and reaches the new state-of-the-art performance.
5/15/2024
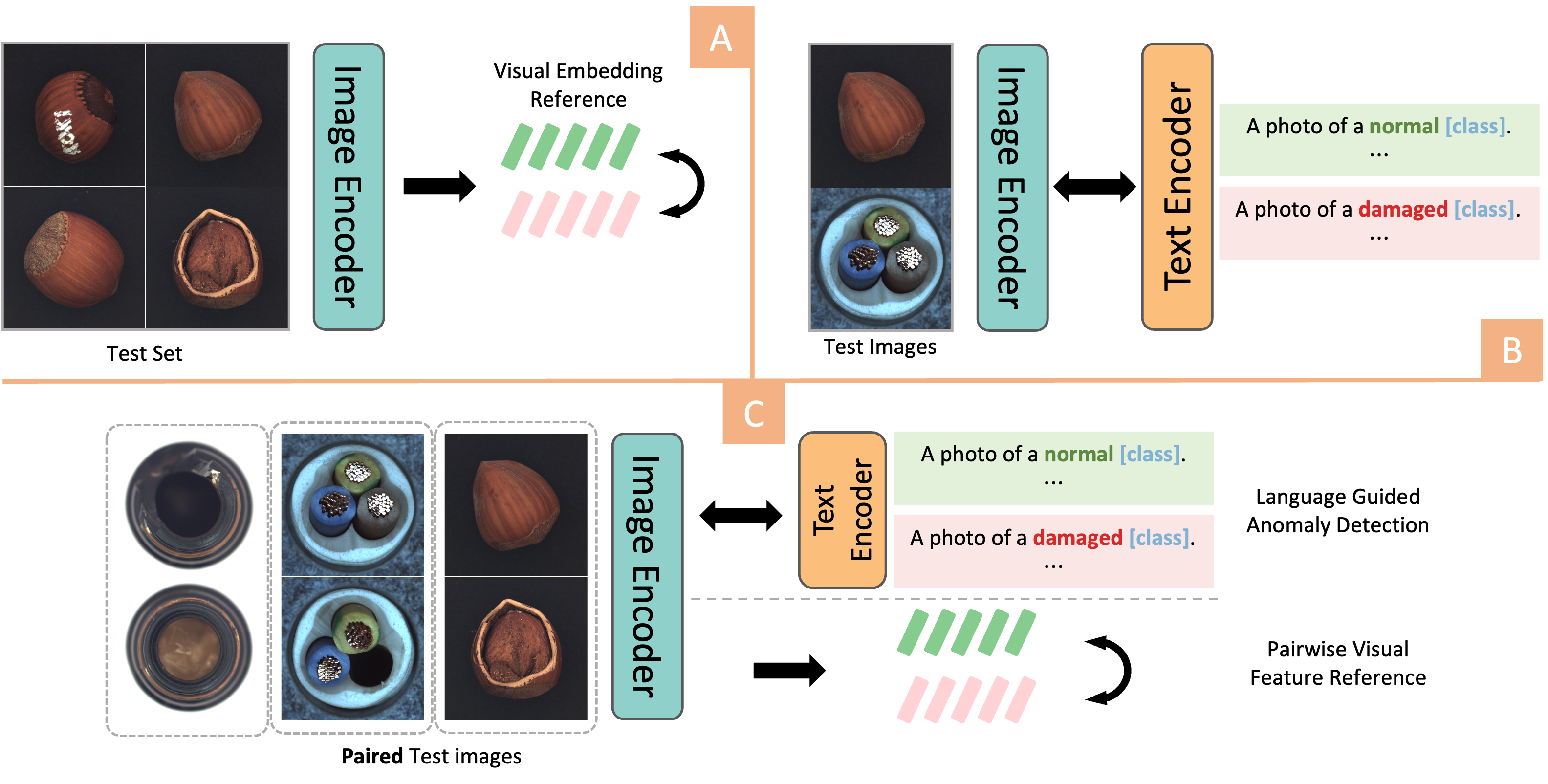
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
Zhaoxiang Zhang, Hanqiu Deng, Jinan Bao, Xingyu Li
0
0
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
5/9/2024
🏷️
Retrieval-Enhanced Visual Prompt Learning for Few-shot Classification
Jintao Rong, Hao Chen, Tianxiao Chen, Linlin Ou, Xinyi Yu, Yifan Liu
0
0
Prompt learning has become a popular approach for adapting large vision-language models, such as CLIP, to downstream tasks. Typically, prompt learning relies on a fixed prompt token or an input-conditional token to fit a small amount of data under full supervision. While this paradigm can generalize to a certain range of unseen classes, it may struggle when domain gap increases, such as in fine-grained classification and satellite image segmentation. To address this limitation, we propose Retrieval-enhanced Prompt learning (RePrompt), which introduces retrieval mechanisms to cache the knowledge representations from downstream tasks. we first construct a retrieval database from training examples, or from external examples when available. We then integrate this retrieval-enhanced mechanism into various stages of a simple prompt learning baseline. By referencing similar samples in the training set, the enhanced model is better able to adapt to new tasks with few samples. Our extensive experiments over 15 vision datasets, including 11 downstream tasks with few-shot setting and 4 domain generalization benchmarks, demonstrate that RePrompt achieves considerably improved performance. Our proposed approach provides a promising solution to the challenges faced by prompt learning when domain gap increases. The code and models will be available.
6/19/2024
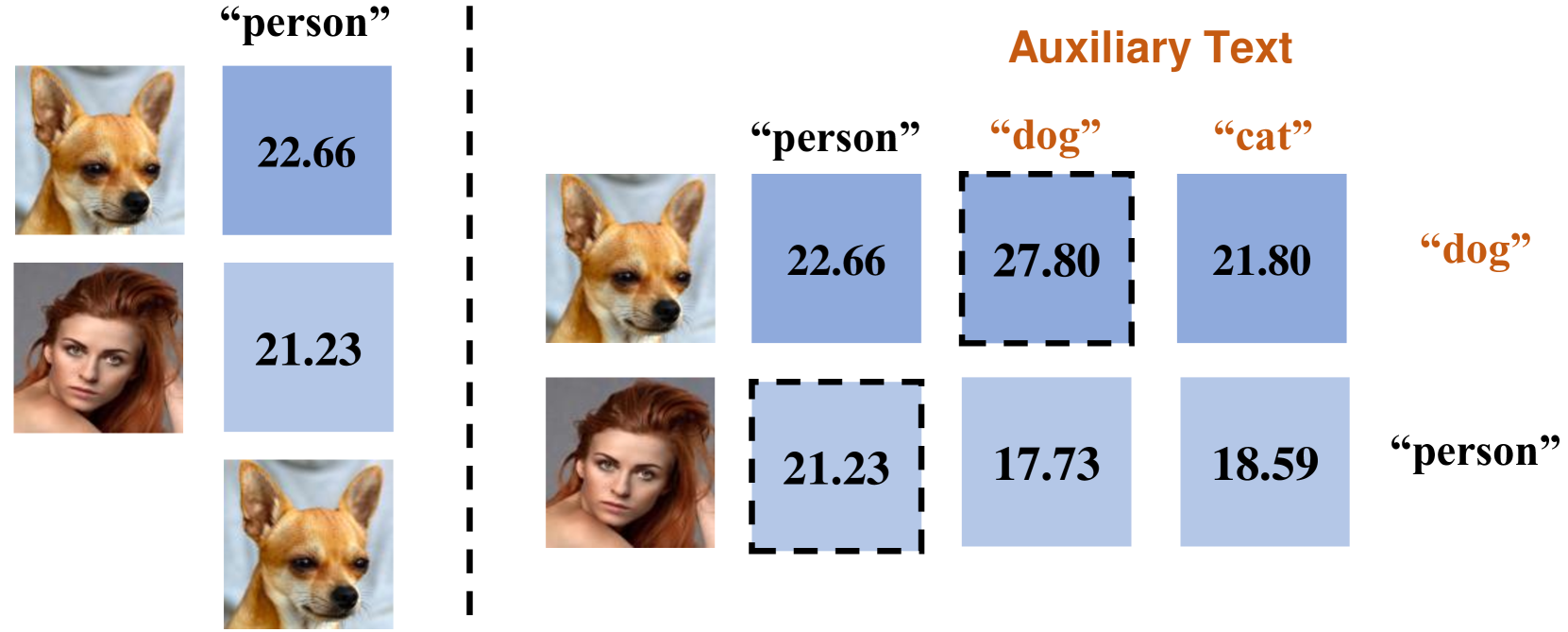
New!Towards Alleviating Text-to-Image Retrieval Hallucination for CLIP in Zero-shot Learning
Hanyao Wang, Yibing Zhan, Liu Liu, Liang Ding, Yan Yang, Jun Yu
0
0
Pretrained cross-modal models, for instance, the most representative CLIP, have recently led to a boom in using pre-trained models for cross-modal zero-shot tasks, considering the generalization properties. However, we analytically discover that CLIP suffers from the text-to-image retrieval hallucination, adversely limiting its capabilities under zero-shot learning: CLIP would select the image with the highest score when asked to figure out which image perfectly matches one given query text among several candidate images even though CLIP knows contents in the image. Accordingly, we propose a Balanced Score with Auxiliary Prompts (BSAP) to mitigate the CLIP's text-to-image retrieval hallucination under zero-shot learning. Specifically, we first design auxiliary prompts to provide multiple reference outcomes for every single image retrieval, then the outcomes derived from each retrieved image in conjunction with the target text are normalized to obtain the final similarity, which alleviates hallucinations in the model. Additionally, we can merge CLIP's original results and BSAP to obtain a more robust hybrid outcome (BSAP-H). Extensive experiments on two typical zero-shot learning tasks, i.e., Referring Expression Comprehension (REC) and Referring Image Segmentation (RIS), are conducted to demonstrate the effectiveness of our BSAP. Specifically, when evaluated on the validation dataset of RefCOCO in REC, BSAP increases CLIP's performance by 20.6%. Further, we validate that our strategy could be applied in other types of pretrained cross-modal models, such as ALBEF and BLIP.
6/28/2024