Retrieval Meets Reasoning: Dynamic In-Context Editing for Long-Text Understanding
2406.12331
0
0

Abstract
Current Large Language Models (LLMs) face inherent limitations due to their pre-defined context lengths, which impede their capacity for multi-hop reasoning within extensive textual contexts. While existing techniques like Retrieval-Augmented Generation (RAG) have attempted to bridge this gap by sourcing external information, they fall short when direct answers are not readily available. We introduce a novel approach that re-imagines information retrieval through dynamic in-context editing, inspired by recent breakthroughs in knowledge editing. By treating lengthy contexts as malleable external knowledge, our method interactively gathers and integrates relevant information, thereby enabling LLMs to perform sophisticated reasoning steps. Experimental results demonstrate that our method effectively empowers context-limited LLMs, such as Llama2, to engage in multi-hop reasoning with improved performance, which outperforms state-of-the-art context window extrapolation methods and even compares favorably to more advanced commercial long-context models. Our interactive method not only enhances reasoning capabilities but also mitigates the associated training and computational costs, making it a pragmatic solution for enhancing LLMs' reasoning within expansive contexts.
Create account to get full access
Overview
- This paper presents a novel approach called "Retrieval Meets Reasoning" (RMR) for improving long-text understanding using dynamic in-context editing.
- The key idea is to combine the strengths of retrieval-based and reasoning-based language models to address the challenges of long-text understanding.
- The RMR approach involves retrieving relevant information from a large knowledge base and then using that information to enhance the language model's reasoning abilities.
Plain English Explanation
The paper discusses a new technique called "Retrieval Meets Reasoning" (RMR) that aims to improve how language models (LMs) can understand and reason about long texts. Long texts, such as research papers or novels, can be difficult for LMs to fully comprehend because they require the ability to retrieve relevant information and then use reasoning to make sense of the broader context.
The RMR approach tries to address this by combining two key capabilities: retrieval and reasoning. First, the model retrieves relevant information from a large knowledge base to supplement the input text. Then, it uses that additional information to enhance its reasoning abilities and better understand the overall meaning and context of the long text.
This approach is motivated by the idea that language models, on their own, may struggle to fully understand complex, long-form content. By bringing in relevant external knowledge and using it to inform the model's reasoning process, the RMR method can potentially lead to improved performance on tasks like summarization, question answering, and other long-text understanding challenges.
Technical Explanation
The paper introduces the "Retrieval Meets Reasoning" (RMR) framework, which aims to enhance language models' ability to understand and reason about long-form text. The key insight is that by combining retrieval-based and reasoning-based approaches, the model can leverage both external knowledge and its own internal reasoning capabilities to better comprehend complex, long-text inputs.
The RMR framework consists of three main components:
- Retriever: This module is responsible for retrieving relevant information from a large knowledge base to supplement the input text.
- Reasoner: The reasoner component takes the input text and the retrieved knowledge to generate a refined representation that captures the broader context and meaning.
- Editor: The editor module dynamically updates the input text based on the refined representation, effectively "editing" the text to improve the language model's understanding.
The authors evaluate the RMR approach on several long-text understanding tasks, including summarization, question answering, and text generation. The results show that the RMR framework outperforms traditional language models, demonstrating the benefits of combining retrieval and reasoning capabilities for tackling long-text challenges.
Critical Analysis
The RMR approach presents a promising direction for improving long-text understanding, but it also has some potential limitations and areas for further research.
One concern is the reliance on a large, high-quality knowledge base to provide the necessary supplementary information. The performance of the retriever module is crucial, and the quality and coverage of the knowledge base could significantly impact the overall effectiveness of the RMR framework.
Additionally, the authors do not provide a detailed analysis of the computational and memory requirements of the RMR system, which could be an important consideration for real-world deployment, especially when dealing with long-form texts.
Further research could explore ways to make the RMR framework more efficient and scalable, perhaps by incorporating techniques like information re-organization or context-aware retrieval. Investigating the integration of the RMR approach with other long-text understanding methods, such as conversational agents or AMR-based compression, could also be a fruitful avenue for future work.
Conclusion
The "Retrieval Meets Reasoning" (RMR) framework presented in this paper offers a novel approach to addressing the challenges of long-text understanding. By combining retrieval-based and reasoning-based techniques, the RMR method can leverage both external knowledge and internal reasoning to better comprehend complex, long-form content.
The promising results demonstrated in the paper suggest that the RMR approach could have significant implications for a wide range of applications, from summarization and question answering to text generation and beyond. As the field of natural language processing continues to evolve, techniques like RMR that can enhance the understanding of long-text inputs will likely become increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs
Ziyan Jiang, Xueguang Ma, Wenhu Chen
0
0
In traditional RAG framework, the basic retrieval units are normally short. The common retrievers like DPR normally work with 100-word Wikipedia paragraphs. Such a design forces the retriever to search over a large corpus to find the `needle' unit. In contrast, the readers only need to extract answers from the short retrieved units. Such an imbalanced `heavy' retriever and `light' reader design can lead to sub-optimal performance. In order to alleviate the imbalance, we propose a new framework LongRAG, consisting of a `long retriever' and a `long reader'. LongRAG processes the entire Wikipedia into 4K-token units, which is 30x longer than before. By increasing the unit size, we significantly reduce the total units from 22M to 700K. This significantly lowers the burden of retriever, which leads to a remarkable retrieval score: answer recall@1=71% on NQ (previously 52%) and answer recall@2=72% (previously 47%) on HotpotQA (full-wiki). Then we feed the top-k retrieved units ($approx$ 30K tokens) to an existing long-context LLM to perform zero-shot answer extraction. Without requiring any training, LongRAG achieves an EM of 62.7% on NQ, which is the best known result. LongRAG also achieves 64.3% on HotpotQA (full-wiki), which is on par of the SoTA model. Our study offers insights into the future roadmap for combining RAG with long-context LLMs.
7/2/2024

Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jinhyuk Lee, Anthony Chen, Zhuyun Dai, Dheeru Dua, Devendra Singh Sachan, Michael Boratko, Yi Luan, S'ebastien M. R. Arnold, Vincent Perot, Siddharth Dalmia, Hexiang Hu, Xudong Lin, Panupong Pasupat, Aida Amini, Jeremy R. Cole, Sebastian Riedel, Iftekhar Naim, Ming-Wei Chang, Kelvin Guu
0
0
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
6/21/2024
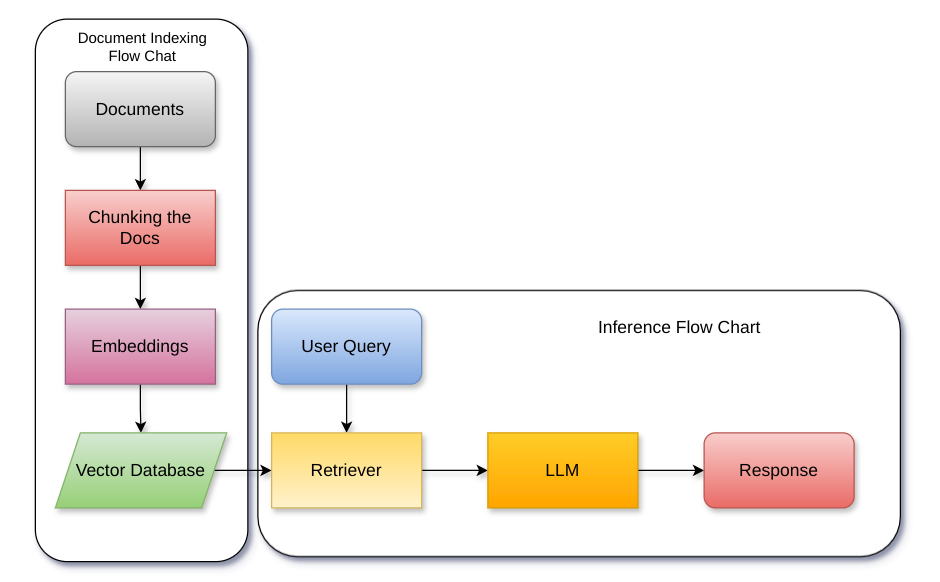
Context-augmented Retrieval: A Novel Framework for Fast Information Retrieval based Response Generation using Large Language Model
Sai Ganesh, Anupam Purwar, Gautam B
0
0
Generating high-quality answers consistently by providing contextual information embedded in the prompt passed to the Large Language Model (LLM) is dependent on the quality of information retrieval. As the corpus of contextual information grows, the answer/inference quality of Retrieval Augmented Generation (RAG) based Question Answering (QA) systems declines. This work solves this problem by combining classical text classification with the Large Language Model (LLM) to enable quick information retrieval from the vector store and ensure the relevancy of retrieved information. For the same, this work proposes a new approach Context Augmented retrieval (CAR), where partitioning of vector database by real-time classification of information flowing into the corpus is done. CAR demonstrates good quality answer generation along with significant reduction in information retrieval and answer generation time.
6/26/2024

BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack
Yuri Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Sorokin, Artyom Sorokin, Mikhail Burtsev
0
0
In recent years, the input context sizes of large language models (LLMs) have increased dramatically. However, existing evaluation methods have not kept pace, failing to comprehensively assess the efficiency of models in handling long contexts. To bridge this gap, we introduce the BABILong benchmark, designed to test language models' ability to reason across facts distributed in extremely long documents. BABILong includes a diverse set of 20 reasoning tasks, including fact chaining, simple induction, deduction, counting, and handling lists/sets. These tasks are challenging on their own, and even more demanding when the required facts are scattered across long natural text. Our evaluations show that popular LLMs effectively utilize only 10-20% of the context and their performance declines sharply with increased reasoning complexity. Among alternatives to in-context reasoning, Retrieval-Augmented Generation methods achieve a modest 60% accuracy on single-fact question answering, independent of context length. Among context extension methods, the highest performance is demonstrated by recurrent memory transformers, enabling the processing of lengths up to 11 million tokens. The BABILong benchmark is extendable to any length to support the evaluation of new upcoming models with increased capabilities, and we provide splits up to 1 million token lengths.
6/17/2024