Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
2406.13121
0
0

Abstract
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
Create account to get full access
Overview
- Introduces a new long-context language model benchmark called LOFT, with documents up to 1 million tokens long
- Explores whether large language models can handle tasks traditionally handled by specialized systems like information retrieval, question-answering, and SQL databases
- Presents experiments showing that long-context language models can perform well on these tasks, potentially subsuming the need for separate systems
Plain English Explanation
This paper explores whether large language models - AI systems trained on massive amounts of text data - can handle a variety of tasks that have traditionally required specialized systems. The researchers introduce a new benchmark called LOFT, which tests how well these models can work with extremely long documents, up to 1 million tokens (a token is roughly equivalent to a word).
The key idea is that if language models can perform well on tasks like information retrieval, question-answering, and interacting with databases - without needing separate specialized systems - it could lead to more streamlined and powerful AI assistants. Previous research has suggested that long-context language models may struggle with long-form tasks, so this paper tests whether that limitation can be overcome.
Through their experiments, the researchers found that large language models can indeed handle these tasks effectively, potentially making separate retrieval, QA, and database systems unnecessary. This could simplify AI architectures and enable more seamless integration of different capabilities.
Technical Explanation
The paper introduces the LOFT (Long-Form Task) benchmark, which includes documents up to 1 million tokens long across a variety of domains like news, Wikipedia, and web pages. The goal is to test whether language models can perform well on tasks that traditionally required separate components, like information retrieval, question-answering, and interacting with SQL databases.
The researchers trained large language models on the LOFT dataset and evaluated them on these various tasks. For information retrieval, they tested the models' ability to find relevant passages given a query. For question-answering, they assessed how well the models could answer questions based on the long-form content. And for the SQL task, they evaluated the models' ability to generate SQL queries to retrieve specific information from a database.
The results showed that the language models were able to perform competitively with or even outperform specialized systems on these tasks. This suggests that a single long-context language model may be able to subsume the functionality of multiple separate components, potentially leading to more unified and capable AI systems.
Critical Analysis
The paper makes a compelling case that large language models can handle a diverse range of tasks that have traditionally required specialized systems. However, the authors acknowledge some limitations of their approach. For example, the SQL task was relatively simple, and more complex database interactions may still require dedicated components.
Additionally, while the language models performed well on average, there was significant variability in their performance across different samples and tasks. This suggests that further refinements may be needed to make them consistently reliable.
The researchers also note that their experiments focused on the language models' raw capabilities, without considering practical deployment factors like computational cost, model size, and training data requirements. These real-world constraints may affect the feasibility of fully subsuming multiple systems into a single language model.
Overall, the paper provides promising evidence that long-context language models can be highly versatile, but more research is needed to fully assess the tradeoffs and limitations of this approach compared to maintaining separate specialized systems.
Conclusion
This paper introduces a new benchmark called LOFT that tests the ability of large language models to handle tasks traditionally requiring specialized systems. The results suggest that these models can perform competitively on information retrieval, question-answering, and SQL tasks, potentially enabling more unified and capable AI assistants in the future.
While further refinements may be needed, the findings highlight the remarkable flexibility of modern language models and their potential to subsume a wide range of functionalities. As the field of AI continues to evolve, this research points to exciting possibilities for simplifying system architectures and unlocking new levels of integration and performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Retrieval Meets Reasoning: Dynamic In-Context Editing for Long-Text Understanding
Weizhi Fei, Xueyan Niu, Guoqing Xie, Yanhua Zhang, Bo Bai, Lei Deng, Wei Han
0
0
Current Large Language Models (LLMs) face inherent limitations due to their pre-defined context lengths, which impede their capacity for multi-hop reasoning within extensive textual contexts. While existing techniques like Retrieval-Augmented Generation (RAG) have attempted to bridge this gap by sourcing external information, they fall short when direct answers are not readily available. We introduce a novel approach that re-imagines information retrieval through dynamic in-context editing, inspired by recent breakthroughs in knowledge editing. By treating lengthy contexts as malleable external knowledge, our method interactively gathers and integrates relevant information, thereby enabling LLMs to perform sophisticated reasoning steps. Experimental results demonstrate that our method effectively empowers context-limited LLMs, such as Llama2, to engage in multi-hop reasoning with improved performance, which outperforms state-of-the-art context window extrapolation methods and even compares favorably to more advanced commercial long-context models. Our interactive method not only enhances reasoning capabilities but also mitigates the associated training and computational costs, making it a pragmatic solution for enhancing LLMs' reasoning within expansive contexts.
6/19/2024

Are Long-LLMs A Necessity For Long-Context Tasks?
Hongjin Qian, Zheng Liu, Peitian Zhang, Kelong Mao, Yujia Zhou, Xu Chen, Zhicheng Dou
0
0
The learning and deployment of long-LLMs remains a challenging problem despite recent progresses. In this work, we argue that the long-LLMs are not a necessity to solve long-context tasks, as common long-context tasks are short-context solvable, i.e. they can be solved by purely working with oracle short-contexts within the long-context tasks' inputs. On top of this argument, we propose a framework called LC-Boost (Long-Context Bootstrapper), which enables a short-LLM to address the long-context tasks in a bootstrapping manner. In our framework, the short-LLM prompts itself to reason for two critical decisions: 1) how to access to the appropriate part of context within the input, 2) how to make effective use of the accessed context. By adaptively accessing and utilizing the context based on the presented tasks, LC-Boost can serve as a general framework to handle diversified long-context processing problems. We comprehensively evaluate different types of tasks from popular long-context benchmarks, where LC-Boost is able to achieve a substantially improved performance with a much smaller consumption of resource.
5/27/2024

LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs
Ziyan Jiang, Xueguang Ma, Wenhu Chen
0
0
In traditional RAG framework, the basic retrieval units are normally short. The common retrievers like DPR normally work with 100-word Wikipedia paragraphs. Such a design forces the retriever to search over a large corpus to find the `needle' unit. In contrast, the readers only need to extract answers from the short retrieved units. Such an imbalanced `heavy' retriever and `light' reader design can lead to sub-optimal performance. In order to alleviate the imbalance, we propose a new framework LongRAG, consisting of a `long retriever' and a `long reader'. LongRAG processes the entire Wikipedia into 4K-token units, which is 30x longer than before. By increasing the unit size, we significantly reduce the total units from 22M to 700K. This significantly lowers the burden of retriever, which leads to a remarkable retrieval score: answer recall@1=71% on NQ (previously 52%) and answer recall@2=72% (previously 47%) on HotpotQA (full-wiki). Then we feed the top-k retrieved units ($approx$ 30K tokens) to an existing long-context LLM to perform zero-shot answer extraction. Without requiring any training, LongRAG achieves an EM of 62.7% on NQ, which is the best known result. LongRAG also achieves 64.3% on HotpotQA (full-wiki), which is on par of the SoTA model. Our study offers insights into the future roadmap for combining RAG with long-context LLMs.
7/2/2024
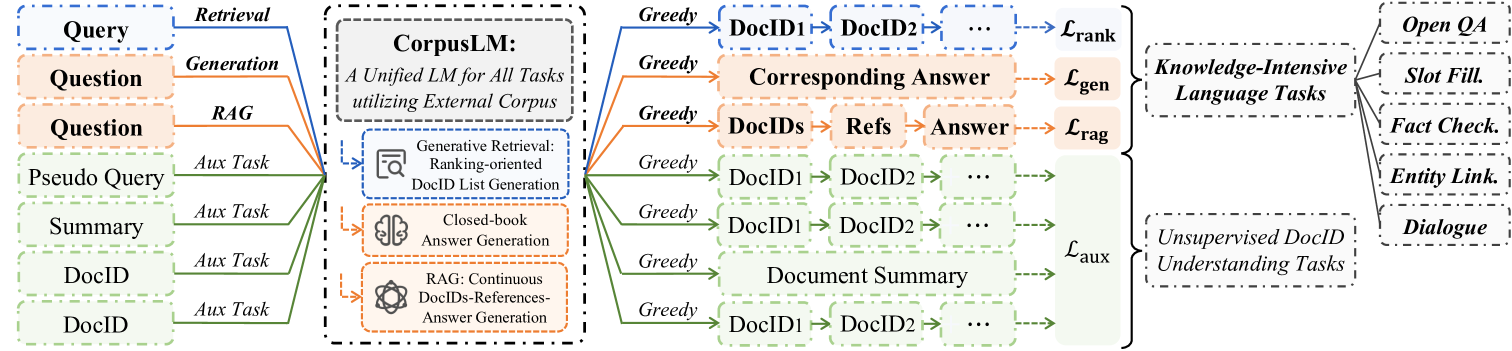
CorpusLM: Towards a Unified Language Model on Corpus for Knowledge-Intensive Tasks
Xiaoxi Li, Zhicheng Dou, Yujia Zhou, Fangchao Liu
0
0
Large language models (LLMs) have gained significant attention in various fields but prone to hallucination, especially in knowledge-intensive (KI) tasks. To address this, retrieval-augmented generation (RAG) has emerged as a popular solution to enhance factual accuracy. However, traditional retrieval modules often rely on large document index and disconnect with generative tasks. With the advent of generative retrieval (GR), language models can retrieve by directly generating document identifiers (DocIDs), offering superior performance in retrieval tasks. However, the potential relationship between GR and downstream tasks remains unexplored. In this paper, we propose textbf{CorpusLM}, a unified language model that leverages external corpus to tackle various knowledge-intensive tasks by integrating generative retrieval, closed-book generation, and RAG through a unified greedy decoding process. We design the following mechanisms to facilitate effective retrieval and generation, and improve the end-to-end effectiveness of KI tasks: (1) We develop a ranking-oriented DocID list generation strategy, which refines GR by directly learning from a DocID ranking list, to improve retrieval quality. (2) We design a continuous DocIDs-References-Answer generation strategy, which facilitates effective and efficient RAG. (3) We employ well-designed unsupervised DocID understanding tasks, to comprehend DocID semantics and their relevance to downstream tasks. We evaluate our approach on the widely used KILT benchmark with two variants of backbone models, i.e., T5 and Llama2. Experimental results demonstrate the superior performance of our models in both retrieval and downstream tasks.
4/23/2024