Retrieve, Annotate, Evaluate, Repeat: Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation

0

Sign in to get full access
Overview
- The paper explores leveraging multimodal large language models (LLMs) for large-scale product retrieval evaluation.
- It proposes a novel approach called "Retrieve, Annotate, Evaluate, Repeat" (RAER) that uses LLMs to assess the relevance of product search results.
- The RAER approach aims to improve the efficiency and scalability of product retrieval evaluation compared to traditional manual methods.
Plain English Explanation
The paper discusses a new way to evaluate how well search engines return relevant products for a given query. Traditionally, this evaluation is done by having people manually review and rate the search results. However, this can be time-consuming and expensive, especially for large-scale product catalogs.
The researchers propose using multimodal large language models to automate this process. These are AI models that can understand and process both text and images, which is important for evaluating product search results that include product images.
The key idea is to have the language model retrieve relevant products, annotate them with relevance scores, evaluate the quality of the annotations, and then repeat the process to continuously improve the system.
By automating this "Retrieve, Annotate, Evaluate, Repeat" (RAER) cycle, the researchers aim to make product retrieval evaluation faster, cheaper, and more scalable compared to manual methods. This could help e-commerce companies and search engines better understand how to improve their product search capabilities.
Technical Explanation
The paper presents a novel approach called "Retrieve, Annotate, Evaluate, Repeat" (RAER) that leverages multimodal LLMs for large-scale product retrieval evaluation.
The RAER workflow consists of four key steps:
- Retrieve: The LLM is used to retrieve relevant product results for a given query.
- Annotate: The LLM then assigns relevance scores to the retrieved products.
- Evaluate: The quality of the relevance annotations is evaluated, for example by comparing them to human judgments.
- Repeat: The insights from the evaluation are used to refine the retrieval and annotation models, and the cycle repeats.
By automating this process, the researchers aim to improve the efficiency and scalability of product retrieval evaluation compared to traditional manual methods. The use of multimodal LLMs is key, as it allows the system to consider both textual product information and visual product images when assessing relevance.
The paper presents experiments demonstrating the effectiveness of the RAER approach on large-scale product catalogs. The results show that the LLM-based system can achieve relevance judgments that closely match human assessments, while being significantly more efficient.
Critical Analysis
The paper provides a compelling approach to addressing the challenges of large-scale product retrieval evaluation. The RAER workflow leverages the capabilities of multimodal LLMs in a clever way to automate a traditionally manual and time-consuming process.
One potential limitation is the reliance on the quality and accuracy of the LLM models. If the initial retrieval or annotation models have biases or shortcomings, this could be propagated through the iterative RAER process. The authors acknowledge this and highlight the importance of the "Evaluate" step to monitor and improve the system over time.
Additionally, the paper focuses on evaluating the relevance of product search results, but does not address other important aspects of product search quality, such as diversity, serendipity, or user satisfaction. Further research could explore how the RAER approach could be extended to capture a more holistic view of product search performance.
Overall, the paper presents a promising direction for leveraging advanced AI techniques to tackle the challenges of large-scale product retrieval evaluation. The RAER approach could have significant implications for e-commerce companies and search engines looking to improve their product search capabilities.
Conclusion
This paper introduces a novel "Retrieve, Annotate, Evaluate, Repeat" (RAER) approach that uses multimodal LLMs to automate the process of evaluating product retrieval relevance at scale. By embedding the LLM-based evaluation into an iterative workflow, the researchers aim to make product retrieval evaluation more efficient and scalable compared to traditional manual methods.
The key contributions of this work are the RAER framework itself, as well as the demonstration of its effectiveness in large-scale product search scenarios. The findings suggest that LLM-based relevance assessment can closely match human judgments, while being significantly more efficient.
Overall, this research represents an important step forward in leveraging advanced AI techniques to improve the evaluation and optimization of product search systems. As e-commerce and search engine capabilities continue to advance, tools like RAER will become increasingly crucial for ensuring that customers can reliably find the products they need.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Retrieve, Annotate, Evaluate, Repeat: Leveraging Multimodal LLMs for Large-Scale Product Retrieval Evaluation
Kasra Hosseini, Thomas Kober, Josip Krapac, Roland Vollgraf, Weiwei Cheng, Ana Peleteiro Ramallo
Evaluating production-level retrieval systems at scale is a crucial yet challenging task due to the limited availability of a large pool of well-trained human annotators. Large Language Models (LLMs) have the potential to address this scaling issue and offer a viable alternative to humans for the bulk of annotation tasks. In this paper, we propose a framework for assessing the product search engines in a large-scale e-commerce setting, leveraging Multimodal LLMs for (i) generating tailored annotation guidelines for individual queries, and (ii) conducting the subsequent annotation task. Our method, validated through deployment on a large e-commerce platform, demonstrates comparable quality to human annotations, significantly reduces time and cost, facilitates rapid problem discovery, and provides an effective solution for production-level quality control at scale.
Read more9/19/2024
0
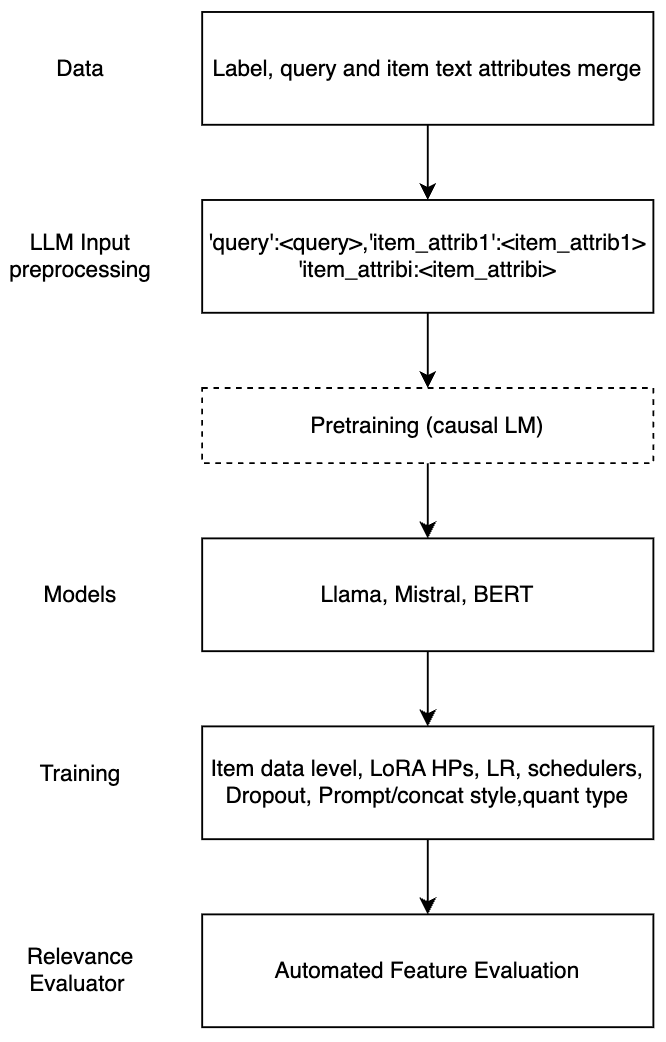
Large Language Models for Relevance Judgment in Product Search
Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, Ciya Liao
High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
Read more7/18/2024
0
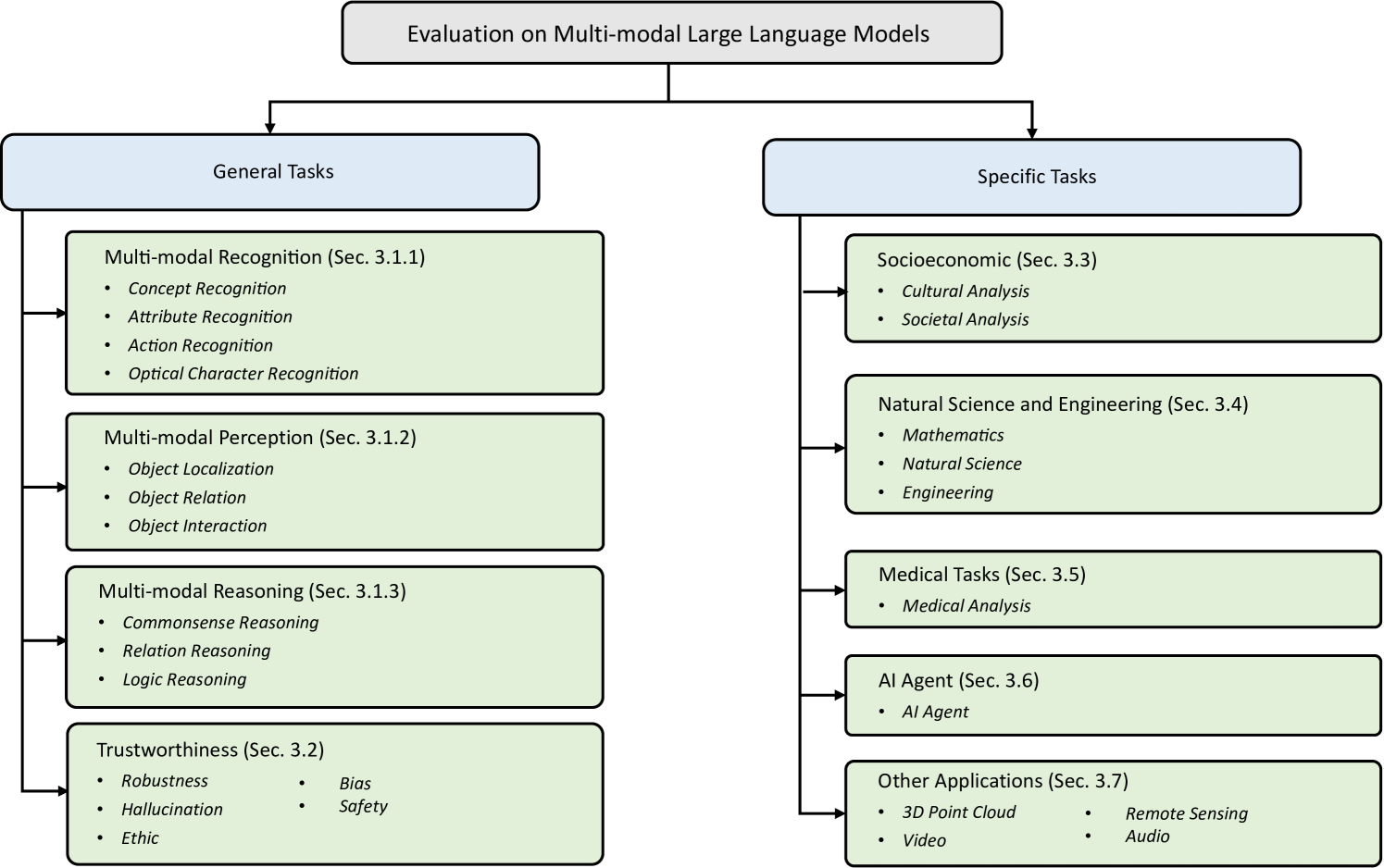
A Survey on Evaluation of Multimodal Large Language Models
Jiaxing Huang, Jingyi Zhang
Multimodal Large Language Models (MLLMs) mimic human perception and reasoning system by integrating powerful Large Language Models (LLMs) with various modality encoders (e.g., vision, audio), positioning LLMs as the brain and various modality encoders as sensory organs. This framework endows MLLMs with human-like capabilities, and suggests a potential pathway towards achieving artificial general intelligence (AGI). With the emergence of all-round MLLMs like GPT-4V and Gemini, a multitude of evaluation methods have been developed to assess their capabilities across different dimensions. This paper presents a systematic and comprehensive review of MLLM evaluation methods, covering the following key aspects: (1) the background of MLLMs and their evaluation; (2) what to evaluate that reviews and categorizes existing MLLM evaluation tasks based on the capabilities assessed, including general multimodal recognition, perception, reasoning and trustworthiness, and domain-specific applications such as socioeconomic, natural sciences and engineering, medical usage, AI agent, remote sensing, video and audio processing, 3D point cloud analysis, and others; (3) where to evaluate that summarizes MLLM evaluation benchmarks into general and specific benchmarks; (4) how to evaluate that reviews and illustrates MLLM evaluation steps and metrics; Our overarching goal is to provide valuable insights for researchers in the field of MLLM evaluation, thereby facilitating the development of more capable and reliable MLLMs. We emphasize that evaluation should be regarded as a critical discipline, essential for advancing the field of MLLMs.
Read more8/29/2024
👀
0
Investigating LLM Applications in E-Commerce
Chester Palen-Michel, Ruixiang Wang, Yipeng Zhang, David Yu, Canran Xu, Zhe Wu
The emergence of Large Language Models (LLMs) has revolutionized natural language processing in various applications especially in e-commerce. One crucial step before the application of such LLMs in these fields is to understand and compare the performance in different use cases in such tasks. This paper explored the efficacy of LLMs in the e-commerce domain, focusing on instruction-tuning an open source LLM model with public e-commerce datasets of varying sizes and comparing the performance with the conventional models prevalent in industrial applications. We conducted a comprehensive comparison between LLMs and traditional pre-trained language models across specific tasks intrinsic to the e-commerce domain, namely classification, generation, summarization, and named entity recognition (NER). Furthermore, we examined the effectiveness of the current niche industrial application of very large LLM, using in-context learning, in e-commerce specific tasks. Our findings indicate that few-shot inference with very large LLMs often does not outperform fine-tuning smaller pre-trained models, underscoring the importance of task-specific model optimization.Additionally, we investigated different training methodologies such as single-task training, mixed-task training, and LoRA merging both within domain/tasks and between different tasks. Through rigorous experimentation and analysis, this paper offers valuable insights into the potential effectiveness of LLMs to advance natural language processing capabilities within the e-commerce industry.
Read more8/26/2024