Retrieving Examples from Memory for Retrieval Augmented Neural Machine Translation: A Systematic Comparison
2404.02835
0
0

Abstract
Retrieval-Augmented Neural Machine Translation (RAMT) architectures retrieve examples from memory to guide the generation process. While most works in this trend explore new ways to exploit the retrieved examples, the upstream retrieval step is mostly unexplored. In this paper, we study the effect of varying retrieval methods for several translation architectures, to better understand the interplay between these two processes. We conduct experiments in two language pairs in a multi-domain setting and consider several downstream architectures based on a standard autoregressive model, an edit-based model, and a large language model with in-context learning. Our experiments show that the choice of the retrieval technique impacts the translation scores, with variance across architectures. We also discuss the effects of increasing the number and diversity of examples, which are mostly positive across the board.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a systematic comparison of different retrieval techniques for use in retrieval-augmented neural machine translation (NMT) models.
- The researchers explore how different retrieval approaches can be integrated into NMT architectures to improve translation quality.
- They evaluate several retrieval techniques, including dense and sparse retrieval, and examine their impact on translation performance.
- The goal is to provide insights into the most effective ways to leverage retrieval in NMT to enhance overall translation capabilities.
Plain English Explanation
The paper looks at different ways to incorporate information retrieval into neural machine translation (NMT) systems. NMT models are a type of artificial intelligence that can translate text from one language to another. However, these models sometimes struggle to produce high-quality translations, especially for complex or specialized content.
The researchers hypothesized that adding a "retrieval" component to NMT models could help improve translation quality. The idea is that the retrieval component would be able to find relevant information from a database of text, and then use that information to inform and enhance the translation process.
The team tested several different retrieval techniques, including ones that find information based on the meaning of the text (dense retrieval) and ones that find information based on the specific words used (sparse retrieval). They wanted to understand which retrieval approaches work best when integrated into NMT models.
By comparing the performance of NMT models with different retrieval methods, the researchers aimed to provide guidance on the most effective ways to leverage information retrieval to boost the translation capabilities of NMT systems. This could lead to more accurate and reliable machine translation, which has important applications in fields like business, research, and communication.
Technical Explanation
The paper examines the integration of retrieval techniques into neural machine translation (NMT) architectures. NMT models use deep learning to translate text from one language to another, but they can struggle with producing high-quality translations, particularly for specialized or complex content.
The researchers hypothesized that incorporating retrieval components into NMT models could enhance translation performance. The retrieval component would be able to access a database of relevant information and incorporate that knowledge into the translation process.
The paper explores several retrieval approaches that could be used in this context:
- Dense retrieval: Finds relevant information based on the semantic meaning of the text, using dense vector representations.
- Sparse retrieval: Finds relevant information based on the specific words and phrases used in the text, using sparse term-based representations.
The team implemented these retrieval techniques within different NMT model architectures and evaluated their impact on translation quality across a range of benchmark datasets. They analyzed factors such as the retrieval method, the size of the retrieval database, and the integration of the retrieval component into the NMT model.
The results provide insights into the most effective ways to leverage retrieval in NMT systems. The findings can guide the development of more robust and capable machine translation models that leverage external knowledge sources to improve their translation performance.
Critical Analysis
The paper presents a thorough and rigorous evaluation of different retrieval techniques for integration into NMT architectures. The researchers carefully designed their experiments to systematically compare a range of retrieval approaches and analyze their impact on translation quality.
One potential limitation is that the study was conducted on a limited set of language pairs and translation tasks. While the researchers used standard benchmark datasets, it would be valuable to see how the results generalize to a wider range of real-world translation scenarios, including low-resource language pairs and specialized domains.
Additionally, the paper does not deeply explore the reasons why certain retrieval techniques may be more effective than others in the context of NMT. Further analysis of the strengths and weaknesses of the different retrieval methods, and how they interact with the NMT model architecture, could provide additional insights.
Another area for potential improvement is the integration of the retrieval component into the NMT model. The paper primarily focuses on different retrieval approaches, but more research could be done on optimal ways to fuse the retrieved information with the NMT model's own processing and decision-making.
Overall, the paper makes a valuable contribution by systematically examining the use of retrieval techniques in NMT and providing empirical evidence to guide future research and development in this area. Continued work in this direction has the potential to lead to significant advances in machine translation capabilities.
Conclusion
This paper presents a comprehensive evaluation of different retrieval techniques for integration into neural machine translation (NMT) models. The researchers explored the use of both dense and sparse retrieval approaches, examining their impact on translation quality across a range of benchmark datasets.
The findings provide important insights into the most effective ways to leverage retrieval in NMT systems. By combining the strengths of retrieval-based and neural-based approaches, the resulting "retrieval-augmented" NMT models have the potential to produce more accurate and reliable translations, particularly for complex or specialized content.
The systematic analysis and empirical results reported in this paper can help guide future research and development in this area, ultimately leading to more advanced and capable machine translation technologies. As these technologies continue to improve, they can have significant real-world applications in fields such as international business, scientific communication, and cross-cultural understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
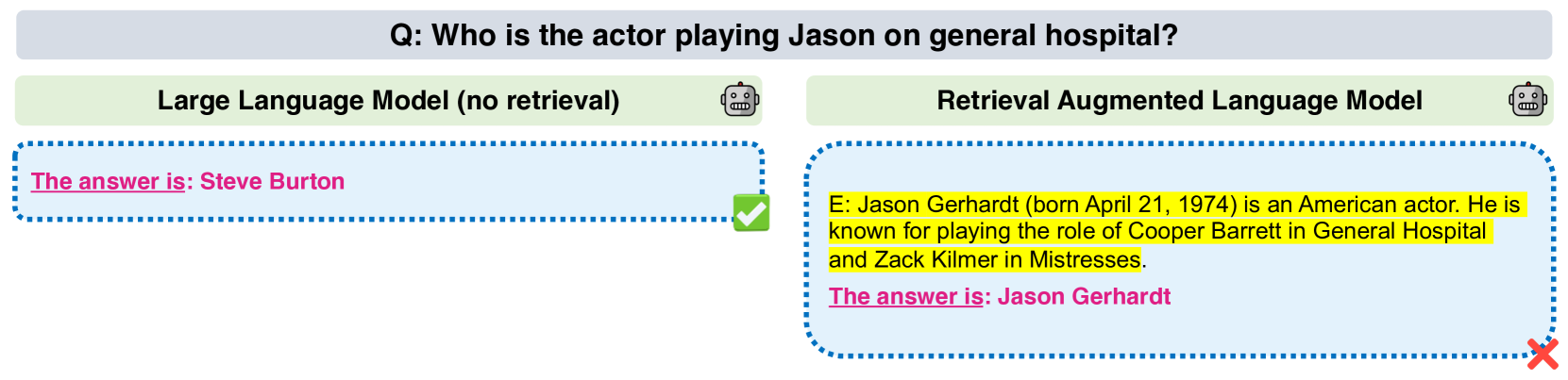
Making Retrieval-Augmented Language Models Robust to Irrelevant Context
Ori Yoran, Tomer Wolfson, Ori Ram, Jonathan Berant
0
0
Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
5/7/2024
🤔
Understanding Retrieval-Augmented Task Adaptation for Vision-Language Models
Yifei Ming, Yixuan Li
0
0
Pre-trained contrastive vision-language models have demonstrated remarkable performance across a wide range of tasks. However, they often struggle on fine-trained datasets with categories not adequately represented during pre-training, which makes adaptation necessary. Recent works have shown promising results by utilizing samples from web-scale databases for retrieval-augmented adaptation, especially in low-data regimes. Despite the empirical success, understanding how retrieval impacts the adaptation of vision-language models remains an open research question. In this work, we adopt a reflective perspective by presenting a systematic study to understand the roles of key components in retrieval-augmented adaptation. We unveil new insights on uni-modal and cross-modal retrieval and highlight the critical role of logit ensemble for effective adaptation. We further present theoretical underpinnings that directly support our empirical observations.
5/3/2024
🏷️
RA-DIT: Retrieval-Augmented Dual Instruction Tuning
Xi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Rich James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, Luke Zettlemoyer, Scott Yih
0
0
Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
5/7/2024
💬
RAG and RAU: A Survey on Retrieval-Augmented Language Model in Natural Language Processing
Yucheng Hu, Yuxing Lu
0
0
Large Language Models (LLMs) have catalyzed significant advancements in Natural Language Processing (NLP), yet they encounter challenges such as hallucination and the need for domain-specific knowledge. To mitigate these, recent methodologies have integrated information retrieved from external resources with LLMs, substantially enhancing their performance across NLP tasks. This survey paper addresses the absence of a comprehensive overview on Retrieval-Augmented Language Models (RALMs), both Retrieval-Augmented Generation (RAG) and Retrieval-Augmented Understanding (RAU), providing an in-depth examination of their paradigm, evolution, taxonomy, and applications. The paper discusses the essential components of RALMs, including Retrievers, Language Models, and Augmentations, and how their interactions lead to diverse model structures and applications. RALMs demonstrate utility in a spectrum of tasks, from translation and dialogue systems to knowledge-intensive applications. The survey includes several evaluation methods of RALMs, emphasizing the importance of robustness, accuracy, and relevance in their assessment. It also acknowledges the limitations of RALMs, particularly in retrieval quality and computational efficiency, offering directions for future research. In conclusion, this survey aims to offer a structured insight into RALMs, their potential, and the avenues for their future development in NLP. The paper is supplemented with a Github Repository containing the surveyed works and resources for further study: https://github.com/2471023025/RALM_Survey.
5/1/2024