Making Retrieval-Augmented Language Models Robust to Irrelevant Context
2310.01558
0
0
Abstract
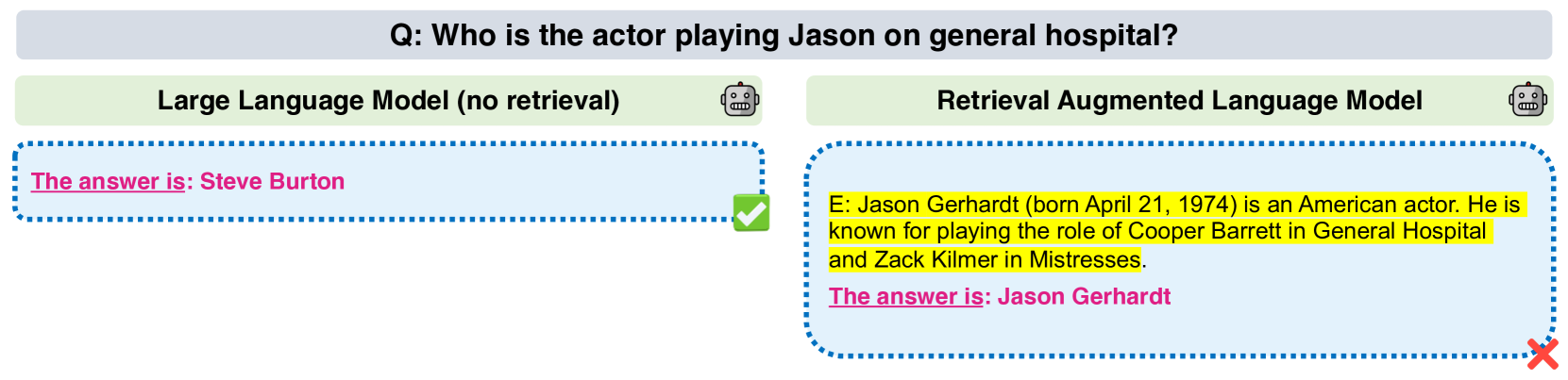
Retrieval-augmented language models (RALMs) hold promise to produce language understanding systems that are are factual, efficient, and up-to-date. An important desideratum of RALMs, is that retrieved information helps model performance when it is relevant, and does not harm performance when it is not. This is particularly important in multi-hop reasoning scenarios, where misuse of irrelevant evidence can lead to cascading errors. However, recent work has shown that retrieval augmentation can sometimes have a negative effect on performance. In this work, we present a thorough analysis on five open-domain question answering benchmarks, characterizing cases when retrieval reduces accuracy. We then propose two methods to mitigate this issue. First, a simple baseline that filters out retrieved passages that do not entail question-answer pairs according to a natural language inference (NLI) model. This is effective in preventing performance reduction, but at a cost of also discarding relevant passages. Thus, we propose a method for automatically generating data to fine-tune the language model to properly leverage retrieved passages, using a mix of relevant and irrelevant contexts at training time. We empirically show that even 1,000 examples suffice to train the model to be robust to irrelevant contexts while maintaining high performance on examples with relevant ones.
Create account to get full access
Overview
- The paper explores how to make retrieval-augmented language models (RALMs) robust to irrelevant context.
- RALMs are a type of language model that can retrieve and incorporate relevant information from a knowledge base to improve their performance on tasks like question answering.
- However, the retrieved information may sometimes be irrelevant to the task at hand, which can degrade the model's performance.
- The paper proposes several techniques to mitigate this issue and make RALMs more robust to irrelevant context.
Plain English Explanation
Retrieval-augmented language models (RALMs) are a type of AI system that can not only generate text, but also retrieve relevant information from a database to help with their task. For example, if you ask a RALM a question, it can search its database, find related information, and use that to provide a better answer.
However, the information the RALM retrieves isn't always relevant to the specific question being asked. This "irrelevant context" can actually make the RALM's response worse. The paper looks at ways to fix this problem and make RALMs more robust, so they can focus on the truly relevant information and avoid being distracted by irrelevant details.
Some of the key ideas the paper explores include:
- Improving Retrieval-Augmented Question Answering Models: Techniques to help RALMs better distinguish relevant from irrelevant retrieved information.
- When to Retrieve: Figuring out the right situations when a RALM should retrieve additional information, versus when it's better to rely on its own internal knowledge.
- Spiral Silences: Understanding how a RALM's behavior can be influenced by the irrelevant information it retrieves, and finding ways to counteract that.
The goal is to make RALMs smarter about when and how to use the information they retrieve, so they can provide more reliable and helpful responses, even when faced with irrelevant context.
Technical Explanation
The paper proposes several techniques to make retrieval-augmented language models (RALMs) more robust to irrelevant context:
-
In-context RALMs: The authors explore ways to improve the RALM's ability to discern relevant from irrelevant retrieved information within the current context. This includes using retrieval quality scores to filter out low-quality retrievals, and incorporating the retrieval quality directly into the RALM's training Improving Retrieval-Augmented Question Answering Models.
-
Retrieval-Guided Prompting: The RALM is trained to decide when to retrieve additional information, rather than always doing so. This allows the model to selectively retrieve relevant information when needed, rather than being distracted by irrelevant context When to Retrieve.
-
Retrieval Quality Reflection: The RALM is trained to reflect on the quality of its own retrieval process, and use that self-assessment to modulate its reliance on the retrieved information. This helps the model avoid being overly influenced by low-quality retrievals Spiral Silences.
-
Retrieval Augmented Continual Learning: The RALM is trained to continually learn and update its retrieval capabilities, allowing it to become more robust to irrelevant context over time.
Through a series of experiments, the authors demonstrate that these techniques can significantly improve the RALM's performance and robustness on a range of tasks, including question answering and dialogue.
Critical Analysis
The paper presents a comprehensive set of techniques to address the important challenge of making retrieval-augmented language models more robust to irrelevant context. The authors' focus on improving the RALM's ability to discern relevant from irrelevant retrieved information is a crucial step in making these models more reliable and trustworthy.
One potential limitation is that the proposed methods may add additional complexity to the RALM architecture and training process. The authors acknowledge this and suggest that further research is needed to strike the right balance between robustness and efficiency.
Additionally, the paper does not delve deeply into the broader societal implications of these more robust RALMs. As these models become more widely deployed, it will be important to consider how their improved ability to handle irrelevant context could impact areas like fact-checking, knowledge curation, and ethical decision-making.
Overall, the paper makes a valuable contribution to the field of retrieval-augmented language models and sets the stage for further research and development in this important area.
Conclusion
This paper presents a range of techniques to make retrieval-augmented language models (RALMs) more robust to irrelevant context. By improving the RALM's ability to discern relevant from irrelevant retrieved information, the authors demonstrate significant performance gains on tasks like question answering and dialogue.
The proposed methods, including in-context RALMs, retrieval-guided prompting, and retrieval quality reflection, offer a promising path forward for making these powerful language models more reliable and trustworthy. As RALMs become more widely deployed, it will be crucial to continue refining their robustness to ensure they can be safely and effectively integrated into real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Assessing Implicit Retrieval Robustness of Large Language Models
Xiaoyu Shen, Rexhina Blloshmi, Dawei Zhu, Jiahuan Pei, Wei Zhang
0
0
Retrieval-augmented generation has gained popularity as a framework to enhance large language models with external knowledge. However, its effectiveness hinges on the retrieval robustness of the model. If the model lacks retrieval robustness, its performance is constrained by the accuracy of the retriever, resulting in significant compromises when the retrieved context is irrelevant. In this paper, we evaluate the implicit retrieval robustness of various large language models, instructing them to directly output the final answer without explicitly judging the relevance of the retrieved context. Our findings reveal that fine-tuning on a mix of gold and distracting context significantly enhances the model's robustness to retrieval inaccuracies, while still maintaining its ability to extract correct answers when retrieval is accurate. This suggests that large language models can implicitly handle relevant or irrelevant retrieved context by learning solely from the supervision of the final answer in an end-to-end manner. Introducing an additional process for explicit relevance judgment can be unnecessary and disrupts the end-to-end approach.
6/27/2024
💬
RAG and RAU: A Survey on Retrieval-Augmented Language Model in Natural Language Processing
Yucheng Hu, Yuxing Lu
0
0
Large Language Models (LLMs) have catalyzed significant advancements in Natural Language Processing (NLP), yet they encounter challenges such as hallucination and the need for domain-specific knowledge. To mitigate these, recent methodologies have integrated information retrieved from external resources with LLMs, substantially enhancing their performance across NLP tasks. This survey paper addresses the absence of a comprehensive overview on Retrieval-Augmented Language Models (RALMs), both Retrieval-Augmented Generation (RAG) and Retrieval-Augmented Understanding (RAU), providing an in-depth examination of their paradigm, evolution, taxonomy, and applications. The paper discusses the essential components of RALMs, including Retrievers, Language Models, and Augmentations, and how their interactions lead to diverse model structures and applications. RALMs demonstrate utility in a spectrum of tasks, from translation and dialogue systems to knowledge-intensive applications. The survey includes several evaluation methods of RALMs, emphasizing the importance of robustness, accuracy, and relevance in their assessment. It also acknowledges the limitations of RALMs, particularly in retrieval quality and computational efficiency, offering directions for future research. In conclusion, this survey aims to offer a structured insight into RALMs, their potential, and the avenues for their future development in NLP. The paper is supplemented with a Github Repository containing the surveyed works and resources for further study: https://github.com/2471023025/RALM_Survey.
5/1/2024
Benchmarking Retrieval-Augmented Large Language Models in Biomedical NLP: Application, Robustness, and Self-Awareness
Mingchen Li, Zaifu Zhan, Han Yang, Yongkang Xiao, Jiatan Huang, Rui Zhang
0
0
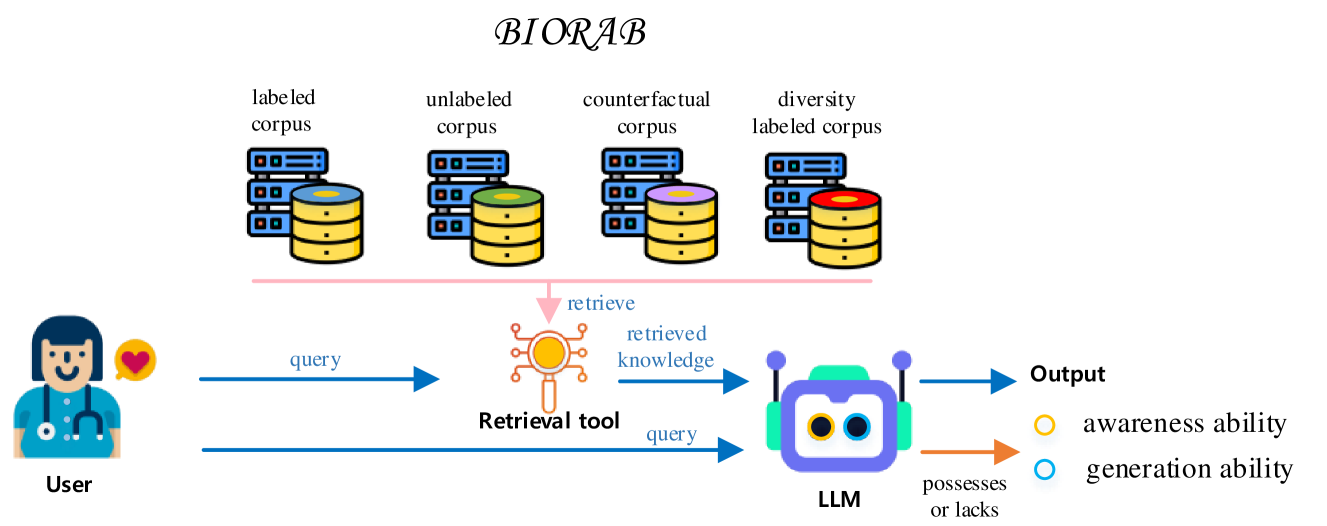
Large language models (LLM) have demonstrated remarkable capabilities in various biomedical natural language processing (NLP) tasks, leveraging the demonstration within the input context to adapt to new tasks. However, LLM is sensitive to the selection of demonstrations. To address the hallucination issue inherent in LLM, retrieval-augmented LLM (RAL) offers a solution by retrieving pertinent information from an established database. Nonetheless, existing research work lacks rigorous evaluation of the impact of retrieval-augmented large language models on different biomedical NLP tasks. This deficiency makes it challenging to ascertain the capabilities of RAL within the biomedical domain. Moreover, the outputs from RAL are affected by retrieving the unlabeled, counterfactual, or diverse knowledge that is not well studied in the biomedical domain. However, such knowledge is common in the real world. Finally, exploring the self-awareness ability is also crucial for the RAL system. So, in this paper, we systematically investigate the impact of RALs on 5 different biomedical tasks (triple extraction, link prediction, classification, question answering, and natural language inference). We analyze the performance of RALs in four fundamental abilities, including unlabeled robustness, counterfactual robustness, diverse robustness, and negative awareness. To this end, we proposed an evaluation framework to assess the RALs' performance on different biomedical NLP tasks and establish four different testbeds based on the aforementioned fundamental abilities. Then, we evaluate 3 representative LLMs with 3 different retrievers on 5 tasks over 9 datasets.
5/17/2024

Unraveling and Mitigating Retriever Inconsistencies in Retrieval-Augmented Large Language Models
Mingda Li, Xinyu Li, Yifan Chen, Wenfeng Xuan, Weinan Zhang
0
0
Although Retrieval-Augmented Large Language Models (RALMs) demonstrate their superiority in terms of factuality, they do not consistently outperform the original retrieval-free Language Models (LMs). Our experiments reveal that this example-level performance inconsistency exists not only between retrieval-augmented and retrieval-free LM but also among different retrievers. To understand this phenomenon, we investigate the degeneration behavior of RALMs and theoretically decompose it into four categories. Further analysis based on our decomposition reveals that the innate difference in knowledge sources and the unpredictable degeneration of the reader model contribute most to the inconsistency. Drawing from our analysis, we introduce Ensemble of Retrievers (EoR), a trainable framework that can adaptively retrieve from different knowledge sources and effectively decrease unpredictable reader errors. Our experiments on Open Domain Question Answering show that EoR substantially improves performance over the RALM with a single retriever by considerably reducing inconsistent behaviors.
6/5/2024