Return of EM: Entity-driven Answer Set Expansion for QA Evaluation
2404.15650
0
0

Abstract
Recently, directly using large language models (LLMs) has been shown to be the most reliable method to evaluate QA models. However, it suffers from limited interpretability, high cost, and environmental harm. To address these, we propose to use soft EM with entity-driven answer set expansion. Our approach expands the gold answer set to include diverse surface forms, based on the observation that the surface forms often follow particular patterns depending on the entity type. The experimental results show that our method outperforms traditional evaluation methods by a large margin. Moreover, the reliability of our evaluation method is comparable to that of LLM-based ones, while offering the benefits of high interpretability and reduced environmental harm.
Create account to get full access
Overview
- The paper proposes a new approach for evaluating question answering (QA) systems called "Entity-driven Answer Set Expansion" (EASE).
- EASE aims to address limitations of traditional QA evaluation metrics by expanding the set of acceptable answers beyond the ground truth.
- The key idea is to leverage entity-level information to identify semantically similar answers that should be considered correct.
Plain English Explanation
The paper introduces a new way to evaluate how well question answering (QA) systems perform. Traditionally, QA evaluation has relied on comparing the system's answers to a predetermined "correct" answer. However, this can be limiting, as there may be multiple valid ways to answer a question.
The researchers' approach, called EASE, tries to address this by expanding the set of acceptable answers. Instead of just checking if the system's answer matches the ground truth, EASE uses information about the entities (people, places, things) mentioned in the question and answer to identify semantically similar answers that should also be considered correct.
This allows for more nuanced and accurate QA evaluation, capturing the true capabilities of the QA system. It could also help improve QA systems by providing more meaningful feedback during training and development.
Technical Explanation
The key innovation of the EASE approach is the use of entity-level information to expand the set of acceptable answers for QA evaluation. Rather than just checking if the system's answer exactly matches the ground truth, EASE looks at the entities mentioned in both the question and the answer.
By leveraging large language models and entity matching techniques, EASE can identify answers that are semantically similar to the ground truth, even if they don't use the exact same wording. This allows the evaluation to be more nuanced and accurate, capturing the true capabilities of the QA system.
The researchers evaluate EASE on several QA datasets and show that it outperforms traditional evaluation metrics in terms of better aligning with human judgments of answer quality. They also demonstrate how EASE can be used to enhance QA systems by providing more meaningful feedback during training and development.
Critical Analysis
The EASE approach represents a promising advance in QA evaluation, but it does have some limitations and areas for further research. One potential concern is that the entity-matching process may not always accurately capture semantic similarity, leading to false positives or negatives in the expanded answer set.
Additionally, the paper does not address how EASE might perform on more complex, multi-answer questions or in specialized domains like biomedicine. Further research would be needed to understand the broader applicability and robustness of the EASE method.
Overall, the EASE approach is a valuable contribution to the field of QA evaluation, offering a more nuanced and accurate way to assess system performance. However, as with any research, there are opportunities for continued refinement and exploration of the method's capabilities and limitations.
Conclusion
The "Return of EM" paper presents a novel approach called EASE for evaluating question answering systems. By leveraging entity-level information to expand the set of acceptable answers, EASE aims to provide a more nuanced and accurate assessment of QA performance.
The key innovation of EASE is its ability to identify semantically similar answers that should be considered correct, even if they don't exactly match the ground truth. This could lead to significant improvements in how we evaluate and develop QA systems, ultimately leading to more capable and useful AI assistants.
While the EASE approach has some limitations that warrant further research, it represents an important step forward in the field of QA evaluation. By rethinking traditional metrics and embracing a more flexible, entity-driven approach, the researchers have opened up new avenues for advancing the state of the art in question answering.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Leveraging Large Language Models for Entity Matching
Qianyu Huang, Tongfang Zhao
0
0
Entity matching (EM) is a critical task in data integration, aiming to identify records across different datasets that refer to the same real-world entities. Traditional methods often rely on manually engineered features and rule-based systems, which struggle with diverse and unstructured data. The emergence of Large Language Models (LLMs) such as GPT-4 offers transformative potential for EM, leveraging their advanced semantic understanding and contextual capabilities. This vision paper explores the application of LLMs to EM, discussing their advantages, challenges, and future research directions. Additionally, we review related work on applying weak supervision and unsupervised approaches to EM, highlighting how LLMs can enhance these methods.
6/3/2024

Embodied Question Answering via Multi-LLM Systems
Bhrij Patel, Vishnu Sashank Dorbala, Dinesh Manocha, Amrit Singh Bedi
0
0
Embodied Question Answering (EQA) is an important problem, which involves an agent exploring the environment to answer user queries. In the existing literature, EQA has exclusively been studied in single-agent scenarios, where exploration can be time-consuming and costly. In this work, we consider EQA in a multi-agent framework involving multiple large language models (LLM) based agents independently answering queries about a household environment. To generate one answer for each query, we use the individual responses to train a Central Answer Model (CAM) that aggregates responses for a robust answer. Using CAM, we observe a $50%$ higher EQA accuracy when compared against aggregation methods for ensemble LLM, such as voting schemes and debates. CAM does not require any form of agent communication, alleviating it from the associated costs. We ablate CAM with various nonlinear (neural network, random forest, decision tree, XGBoost) and linear (logistic regression classifier, SVM) algorithms. Finally, we present a feature importance analysis for CAM via permutation feature importance (PFI), quantifying CAMs reliance on each independent agent and query context.
6/19/2024

Accurate and Nuanced Open-QA Evaluation Through Textual Entailment
Peiran Yao, Denilson Barbosa
0
0
Open-domain question answering (Open-QA) is a common task for evaluating large language models (LLMs). However, current Open-QA evaluations are criticized for the ambiguity in questions and the lack of semantic understanding in evaluators. Complex evaluators, powered by foundation models or LLMs and pertaining to semantic equivalence, still deviate from human judgments by a large margin. We propose to study the entailment relations of answers to identify more informative and more general system answers, offering a much closer evaluation to human judgment on both NaturalQuestions and TriviaQA while being learning-free. The entailment-based evaluation we propose allows the assignment of bonus or partial marks by quantifying the inference gap between answers, enabling a nuanced ranking of answer correctness that has higher AUC than current methods.
5/28/2024
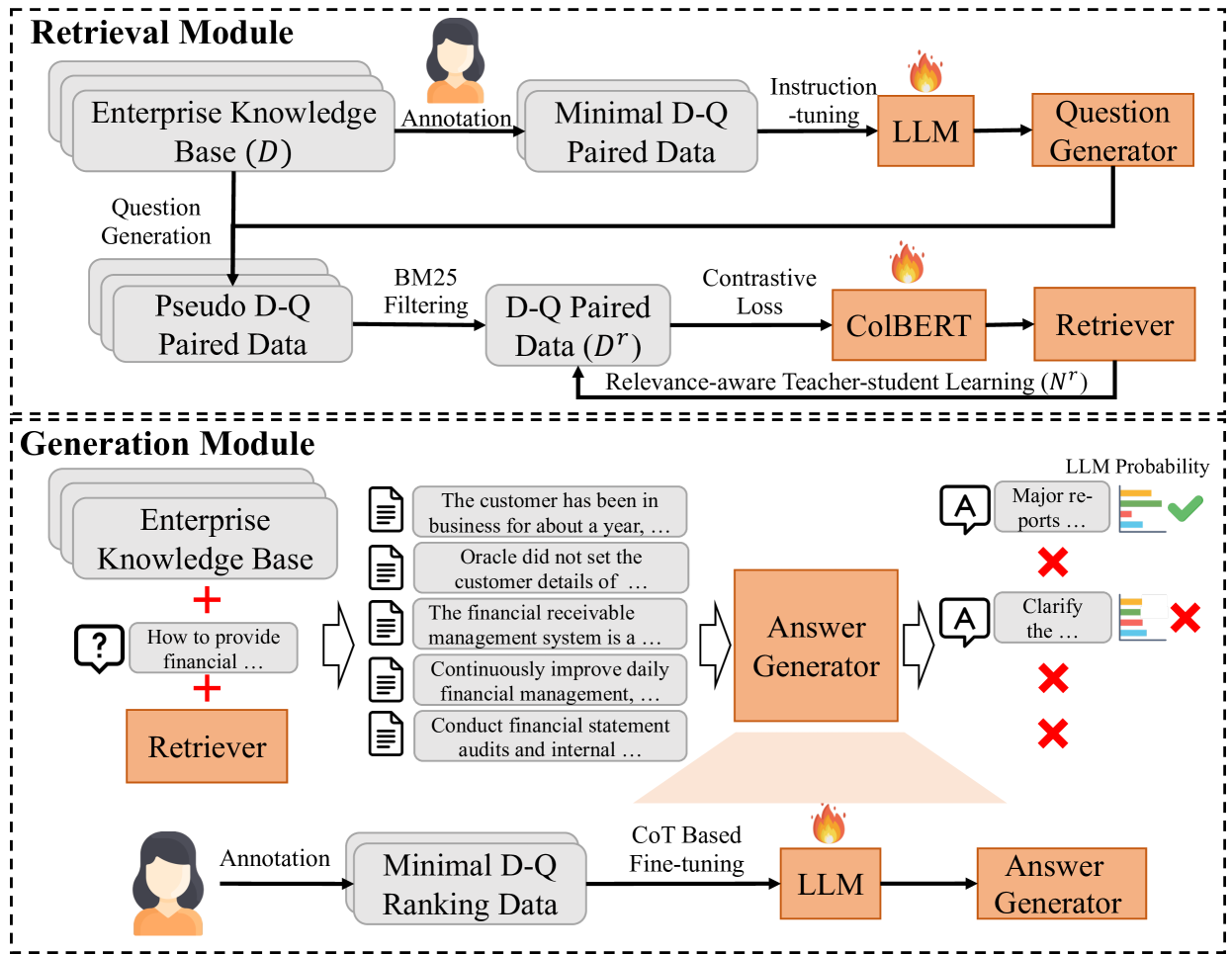
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
0
0
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
4/23/2024