Revisiting Few-Shot Object Detection with Vision-Language Models
2312.14494
0
0

Abstract
The era of vision-language models (VLMs) trained on large web-scale datasets challenges conventional formulations of open-world perception. In this work, we revisit the task of few-shot object detection (FSOD) in the context of recent foundational VLMs. First, we point out that zero-shot VLMs such as GroundingDINO significantly outperform state-of-the-art few-shot detectors (48 vs. 33 AP) on COCO. Despite their strong zero-shot performance, such foundational models may still be sub-optimal. For example, trucks on the web may be defined differently from trucks for a target application such as autonomous vehicle perception. We argue that the task of few-shot recognition can be reformulated as aligning foundation models to target concepts using a few examples. Interestingly, such examples can be multi-modal, using both text and visual cues, mimicking instructions that are often given to human annotators when defining a target concept of interest. Concretely, we propose Foundational FSOD, a new benchmark protocol that evaluates detectors pre-trained on any external datasets and fine-tuned on multi-modal (text and visual) K-shot examples per target class. We repurpose nuImages for Foundational FSOD, benchmark several popular open-source VLMs, and provide an empirical analysis of state-of-the-art methods. Lastly, we discuss our recent CVPR 2024 Foundational FSOD competition and share insights from the community. Notably, the winning team significantly outperforms our baseline by 23.9 mAP!
Create account to get full access
Overview
- This paper explores the use of vision-language models for few-shot object detection (FSOD), a challenging task where models must learn to detect objects from limited training data.
- The authors investigate the strengths and limitations of current FSOD approaches using vision-language models, and propose ways to overcome some of the key challenges.
- The research aims to advance the state-of-the-art in FSOD and provide insights into the effective application of pre-trained vision-language transformers for this task.
Plain English Explanation
Object detection is the computer vision task of identifying and locating objects within an image. Few-shot object detection is a particularly difficult version of this problem, where the model must learn to detect objects from very limited training data - perhaps just one or a few examples.
The authors of this paper explore the use of vision-language models for few-shot object detection. These models are trained on large datasets that combine visual and textual information, giving them a rich understanding of the world that could potentially be leveraged for FSOD.
The paper examines the strengths and limitations of current FSOD approaches using vision-language models. For example, the models may struggle with out-of-domain objects that are very different from their pre-training data. The authors propose ways to overcome these challenges and improve the performance of vision-language models on few-shot object detection.
Overall, the research aims to advance the state-of-the-art in few-shot object detection and provide insights into the effective use of powerful pre-trained vision-language transformers for this task.
Technical Explanation
The paper begins by reviewing the related works in few-shot object detection and the use of vision-language models for various computer vision tasks. The authors then dive into their investigation of FSOD using vision-language models.
They propose a framework that leverages the rich semantic understanding of vision-language models to boost few-shot object detection performance. The key components include:
- Vision-Language Pretraining: The models are first pre-trained on large-scale datasets that combine visual and textual information, giving them a broad knowledge base to draw from.
- Few-Shot Finetuning: The pre-trained models are then fine-tuned on the limited FSOD training data, allowing them to learn the specific object detection task while building on their existing visual and linguistic knowledge.
- Cross-Modal Attention: The framework uses cross-modal attention mechanisms to effectively integrate the visual and textual information, enabling the model to make more informed object detection decisions.
The authors conduct extensive experiments to evaluate their approach on benchmark FSOD datasets. They compare their framework to state-of-the-art FSOD methods and analyze the impacts of different design choices. The results demonstrate the advantages of using vision-language models for few-shot object detection, as well as identify areas for further improvement.
Critical Analysis
The paper presents a well-designed study that makes a compelling case for the use of vision-language models in few-shot object detection. The authors acknowledge several limitations and areas for future work, including:
- Out-of-Distribution Generalization: The models may still struggle with objects that are very different from their pre-training data, limiting their ability to generalize to novel scenarios.
- Sample Efficiency: While the vision-language approach improves upon existing FSOD methods, the models still require a significant amount of fine-tuning data compared to the truly few-shot setting.
- Interpretability: As with many deep learning models, the internal workings of the vision-language framework can be difficult to interpret, which may hinder its practical deployment.
Additionally, one could question whether the benefits of vision-language models outweigh the increased complexity and computational cost compared to more specialized FSOD architectures. Further research is needed to fully understand the tradeoffs and identify the most suitable applications for this approach.
Conclusion
This paper offers a promising direction for few-shot object detection by leveraging the rich semantic understanding of vision-language models. The authors demonstrate how these powerful pre-trained models can be effectively fine-tuned for FSOD, outperforming state-of-the-art methods.
While the research highlights the strengths of this approach, it also identifies critical limitations that warrant further investigation. Addressing challenges like out-of-distribution generalization and sample efficiency will be key to unlocking the full potential of vision-language models for few-shot object detection.
Overall, this work contributes valuable insights and lays the groundwork for improving zero-shot classification and novel benchmarking in the emerging field of few-shot computer vision tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
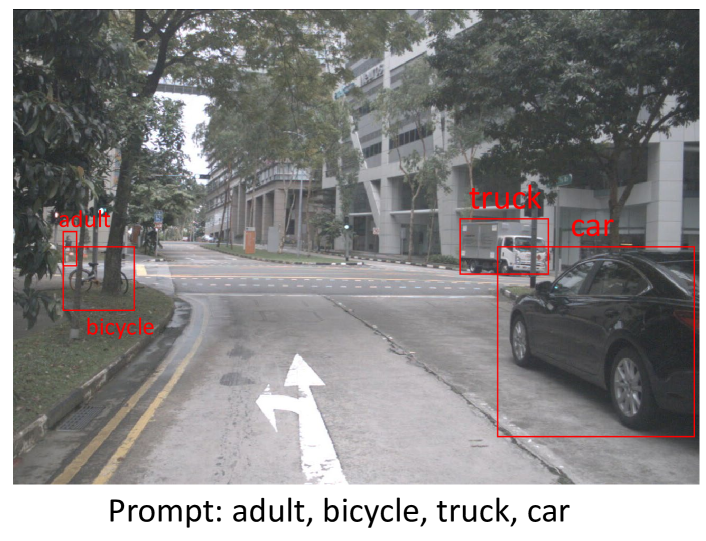
The Solution for CVPR2024 Foundational Few-Shot Object Detection Challenge
Hongpeng Pan, Shifeng Yi, Shouwei Yang, Lei Qi, Bing Hu, Yi Xu, Yang Yang
0
0
This report introduces an enhanced method for the Foundational Few-Shot Object Detection (FSOD) task, leveraging the vision-language model (VLM) for object detection. However, on specific datasets, VLM may encounter the problem where the detected targets are misaligned with the target concepts of interest. This misalignment hinders the zero-shot performance of VLM and the application of fine-tuning methods based on pseudo-labels. To address this issue, we propose the VLM+ framework, which integrates the multimodal large language model (MM-LLM). Specifically, we use MM-LLM to generate a series of referential expressions for each category. Based on the VLM predictions and the given annotations, we select the best referential expression for each category by matching the maximum IoU. Subsequently, we use these referential expressions to generate pseudo-labels for all images in the training set and then combine them with the original labeled data to fine-tune the VLM. Additionally, we employ iterative pseudo-label generation and optimization to further enhance the performance of the VLM. Our approach achieve 32.56 mAP in the final test.
6/19/2024

Semantic Enhanced Few-shot Object Detection
Zheng Wang, Yingjie Gao, Qingjie Liu, Yunhong Wang
0
0
Few-shot object detection~(FSOD), which aims to detect novel objects with limited annotated instances, has made significant progress in recent years. However, existing methods still suffer from biased representations, especially for novel classes in extremely low-shot scenarios. During fine-tuning, a novel class may exploit knowledge from similar base classes to construct its own feature distribution, leading to classification confusion and performance degradation. To address these challenges, we propose a fine-tuning based FSOD framework that utilizes semantic embeddings for better detection. In our proposed method, we align the visual features with class name embeddings and replace the linear classifier with our semantic similarity classifier. Our method trains each region proposal to converge to the corresponding class embedding. Furthermore, we introduce a multimodal feature fusion to augment the vision-language communication, enabling a novel class to draw support explicitly from well-trained similar base classes. To prevent class confusion, we propose a semantic-aware max-margin loss, which adaptively applies a margin beyond similar classes. As a result, our method allows each novel class to construct a compact feature space without being confused with similar base classes. Extensive experiments on Pascal VOC and MS COCO demonstrate the superiority of our method.
6/21/2024
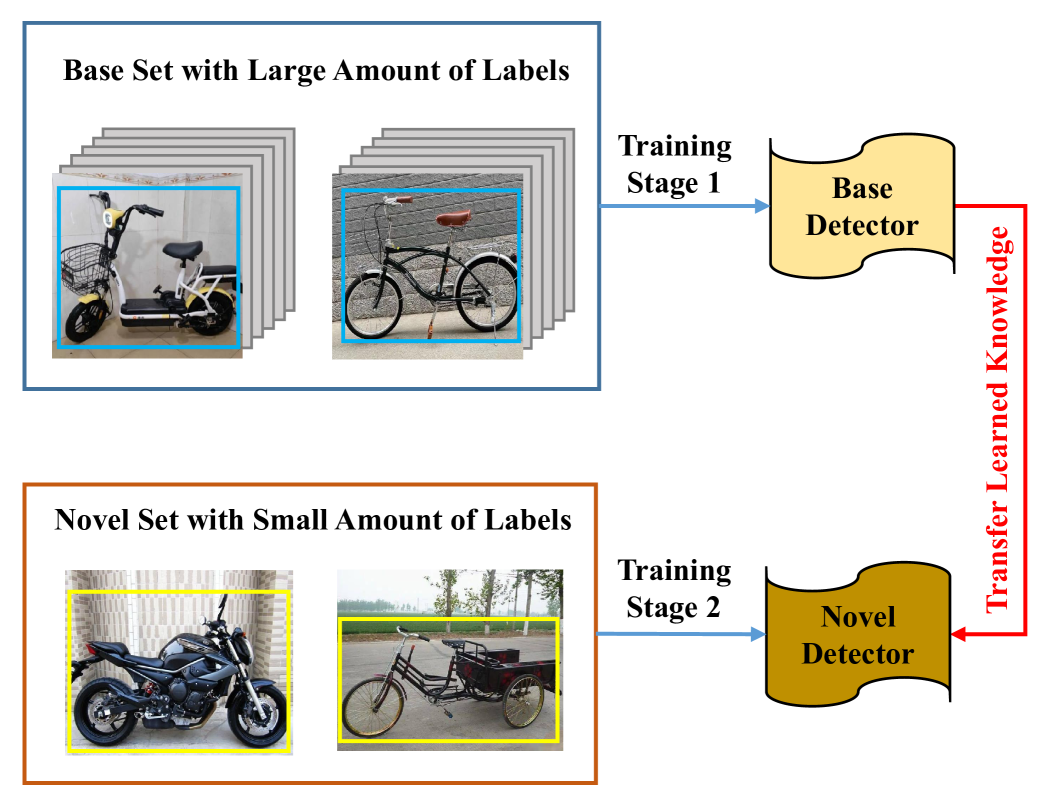
Few-Shot Object Detection: Research Advances and Challenges
Zhimeng Xin, Shiming Chen, Tianxu Wu, Yuanjie Shao, Weiping Ding, Xinge You
0
0
Object detection as a subfield within computer vision has achieved remarkable progress, which aims to accurately identify and locate a specific object from images or videos. Such methods rely on large-scale labeled training samples for each object category to ensure accurate detection, but obtaining extensive annotated data is a labor-intensive and expensive process in many real-world scenarios. To tackle this challenge, researchers have explored few-shot object detection (FSOD) that combines few-shot learning and object detection techniques to rapidly adapt to novel objects with limited annotated samples. This paper presents a comprehensive survey to review the significant advancements in the field of FSOD in recent years and summarize the existing challenges and solutions. Specifically, we first introduce the background and definition of FSOD to emphasize potential value in advancing the field of computer vision. We then propose a novel FSOD taxonomy method and survey the plentifully remarkable FSOD algorithms based on this fact to report a comprehensive overview that facilitates a deeper understanding of the FSOD problem and the development of innovative solutions. Finally, we discuss the advantages and limitations of these algorithms to summarize the challenges, potential research direction, and development trend of object detection in the data scarcity scenario.
4/9/2024
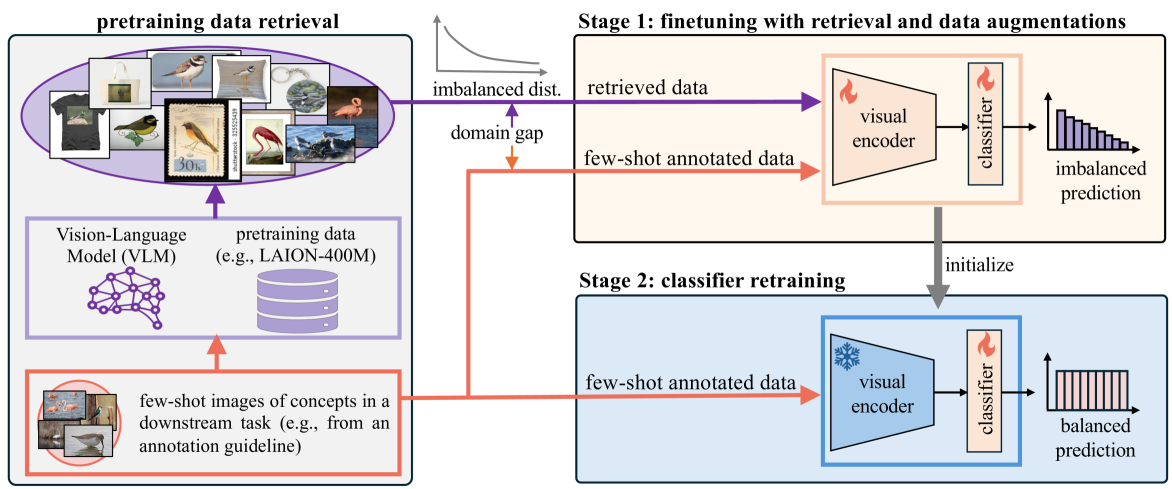
Few-Shot Recognition via Stage-Wise Augmented Finetuning
Tian Liu, Huixin Zhang, Shubham Parashar, Shu Kong
0
0
Few-shot recognition aims to train a classification model with only a few labeled examples of pre-defined concepts, where annotation can be costly in a downstream task. In another related research area, zero-shot recognition, which assumes no access to any downstream-task data, has been greatly advanced by using pretrained Vision-Language Models (VLMs). In this area, retrieval-augmented learning (RAL) effectively boosts zero-shot accuracy by retrieving and learning from external data relevant to downstream concepts. Motivated by these advancements, our work explores RAL for few-shot recognition. While seemingly straightforward despite being under-explored in the literature (till now!), we present novel challenges and opportunities for applying RAL for few-shot recognition. First, perhaps surprisingly, simply finetuning the VLM on a large amount of retrieved data barely surpasses state-of-the-art zero-shot methods due to the imbalanced distribution of retrieved data and its domain gaps compared to few-shot annotated data. Second, finetuning a VLM on few-shot examples alone significantly outperforms prior methods, and finetuning on the mix of retrieved and few-shot data yields even better results. Third, to mitigate the imbalanced distribution and domain gap issue, we propose Stage-Wise Augmented fineTuning (SWAT) method, which involves end-to-end finetuning on mixed data for the first stage and retraining the classifier solely on the few-shot data in the second stage. Extensive experiments show that SWAT achieves the best performance on standard benchmark datasets, resoundingly outperforming prior works by ~10% in accuracy. Code is available at https://github.com/tian1327/SWAT.
6/18/2024