Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
2401.02460
0
0
Abstract
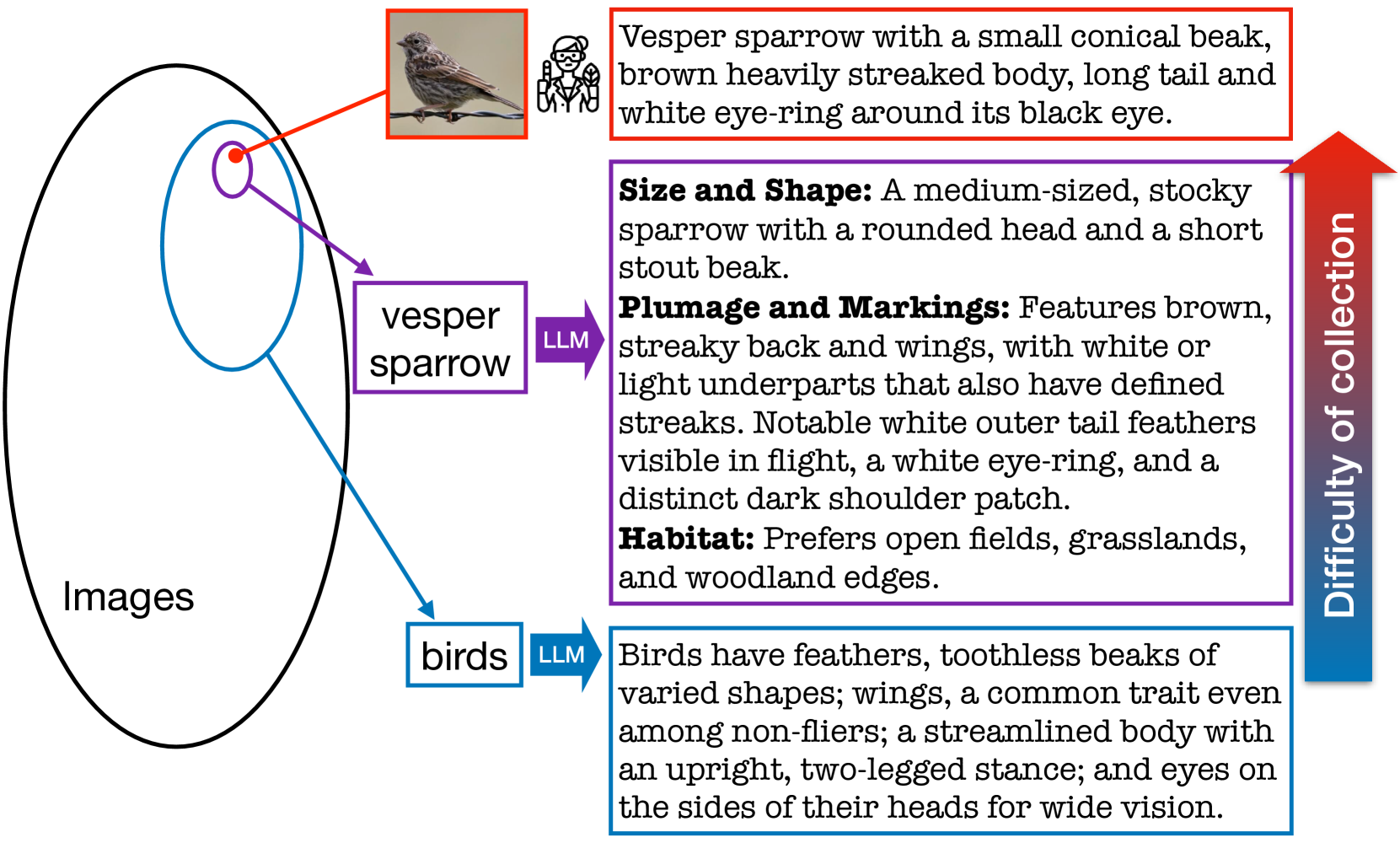
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this bag-level image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We release the benchmark, consisting of 14 datasets at https://github.com/cvl-umass/AdaptCLIPZS , which will contribute to future research in zero-shot recognition.
Create account to get full access
Overview
- This paper explores a technique for improving zero-shot classification performance by adapting vision-language models (VLMs) using text descriptions.
- The authors propose a method to fine-tune VLMs on text descriptions of classes, allowing the models to better understand and classify unseen classes during zero-shot evaluation.
- The paper presents experiments on several benchmark datasets, demonstrating improvements in zero-shot classification compared to standard VLM approaches.
Plain English Explanation
Vision-language models (VLMs) are a type of AI system that can understand and process both visual and text data. They have become increasingly powerful at tasks like image classification, where the model can identify the contents of an image.
One challenging scenario for VLMs is "zero-shot" classification, where the model needs to classify images of objects or concepts it has never seen before. This is difficult because the model has not been trained on those specific classes.
This paper proposes a way to improve zero-shot classification by adapting VLMs with text descriptions. The key idea is to fine-tune the VLM on text descriptions of the classes, even the ones it hasn't seen before. This helps the model build a more nuanced understanding of those concepts, allowing it to better recognize them in images during zero-shot evaluation.
The authors test this approach on several standard benchmarks for zero-shot classification. They show that fine-tuning the VLM on text descriptions leads to substantial improvements in the model's ability to correctly classify images of novel classes it hasn't seen before. This suggests that leveraging text data can be a powerful way to enhance the capabilities of vision-language models.
Technical Explanation
The paper proposes a method to improve zero-shot classification performance by adapting vision-language models (VLMs) using text descriptions of classes. The authors hypothesize that fine-tuning VLMs on text descriptions can help the models better understand and recognize unseen classes during zero-shot evaluation.
The proposed approach consists of two main steps:
-
Retrieval: Given a set of class labels, the method retrieves the most relevant text descriptions for each class from a large text corpus. This provides a textual representation of the classes.
-
Fine-tuning: The VLM is then fine-tuned on the retrieved text descriptions, allowing the model to learn associations between the visual features and the semantic information encoded in the text.
The authors evaluate this approach on several zero-shot classification benchmarks, including ImageNet-LT, Places-LT, and CLIP-Ow. They demonstrate that fine-tuning the VLM on text descriptions leads to significant improvements in zero-shot classification performance compared to standard VLM baselines.
The key insight is that the additional text-based fine-tuning helps the VLM develop a more comprehensive understanding of the class concepts, which translates to better recognition of unseen classes during evaluation.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed approach, with experiments across multiple benchmark datasets. The results convincingly demonstrate the benefits of fine-tuning VLMs on text descriptions for improving zero-shot classification.
However, the paper does not discuss potential limitations or caveats of the approach. For example, the effectiveness of the method may depend on the quality and relevance of the retrieved text descriptions. If the descriptions do not accurately capture the essential characteristics of the classes, the fine-tuning process may not be as effective.
Additionally, the paper does not explore the scalability of the approach as the number of classes grows. Retrieving and fine-tuning on text descriptions for a large number of classes could become computationally expensive and may require further optimization.
It would also be valuable to understand the generalization capabilities of the fine-tuned VLMs. The paper focuses on zero-shot classification, but it is unclear how the models would perform on more traditional, fully-supervised classification tasks.
Conclusion
This paper presents a novel technique for improving zero-shot classification performance by adapting vision-language models (VLMs) using text descriptions of classes. The key idea is to fine-tune the VLM on the retrieved text descriptions, helping the model develop a more nuanced understanding of the class concepts.
The experimental results demonstrate significant improvements in zero-shot classification across several benchmark datasets, suggesting that leveraging text data can be a powerful way to enhance the capabilities of VLMs. This work highlights the potential of combining visual and textual information to tackle challenging problems in computer vision and AI.
Overall, this paper contributes a valuable technique for improving zero-shot classification and expands our understanding of how text-based fine-tuning can benefit vision-language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
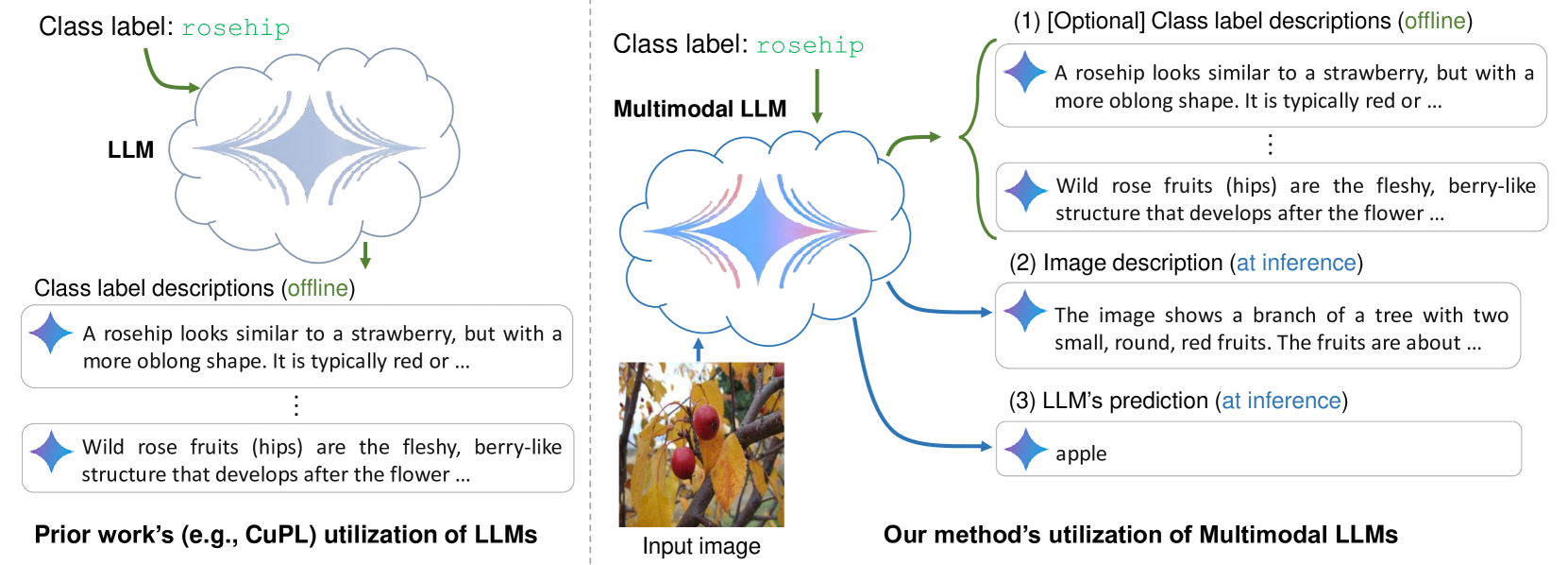
What Do You See? Enhancing Zero-Shot Image Classification with Multimodal Large Language Models
Abdelrahman Abdelhamed, Mahmoud Afifi, Alec Go
0
0
Large language models (LLMs) has been effectively used for many computer vision tasks, including image classification. In this paper, we present a simple yet effective approach for zero-shot image classification using multimodal LLMs. By employing multimodal LLMs, we generate comprehensive textual representations from input images. These textual representations are then utilized to generate fixed-dimensional features in a cross-modal embedding space. Subsequently, these features are fused together to perform zero-shot classification using a linear classifier. Our method does not require prompt engineering for each dataset; instead, we use a single, straightforward, set of prompts across all datasets. We evaluated our method on several datasets, and our results demonstrate its remarkable effectiveness, surpassing benchmark accuracy on multiple datasets. On average over ten benchmarks, our method achieved an accuracy gain of 4.1 percentage points, with an increase of 6.8 percentage points on the ImageNet dataset, compared to prior methods. Our findings highlight the potential of multimodal LLMs to enhance computer vision tasks such as zero-shot image classification, offering a significant improvement over traditional methods.
5/27/2024

The Neglected Tails in Vision-Language Models
Shubham Parashar, Zhiqiu Lin, Tian Liu, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, Shu Kong
0
0
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
5/24/2024
🏷️
LLM meets Vision-Language Models for Zero-Shot One-Class Classification
Yassir Bendou, Giulia Lioi, Bastien Pasdeloup, Lukas Mauch, Ghouthi Boukli Hacene, Fabien Cardinaux, Vincent Gripon
0
0
We consider the problem of zero-shot one-class visual classification, extending traditional one-class classification to scenarios where only the label of the target class is available. This method aims to discriminate between positive and negative query samples without requiring examples from the target class. We propose a two-step solution that first queries large language models for visually confusing objects and then relies on vision-language pre-trained models (e.g., CLIP) to perform classification. By adapting large-scale vision benchmarks, we demonstrate the ability of the proposed method to outperform adapted off-the-shelf alternatives in this setting. Namely, we propose a realistic benchmark where negative query samples are drawn from the same original dataset as positive ones, including a granularity-controlled version of iNaturalist, where negative samples are at a fixed distance in the taxonomy tree from the positive ones. To our knowledge, we are the first to demonstrate the ability to discriminate a single category from other semantically related ones using only its label.
5/28/2024

Exploring the Zero-Shot Capabilities of Vision-Language Models for Improving Gaze Following
Anshul Gupta, Pierre Vuillecard, Arya Farkhondeh, Jean-Marc Odobez
0
0
Contextual cues related to a person's pose and interactions with objects and other people in the scene can provide valuable information for gaze following. While existing methods have focused on dedicated cue extraction methods, in this work we investigate the zero-shot capabilities of Vision-Language Models (VLMs) for extracting a wide array of contextual cues to improve gaze following performance. We first evaluate various VLMs, prompting strategies, and in-context learning (ICL) techniques for zero-shot cue recognition performance. We then use these insights to extract contextual cues for gaze following, and investigate their impact when incorporated into a state of the art model for the task. Our analysis indicates that BLIP-2 is the overall top performing VLM and that ICL can improve performance. We also observe that VLMs are sensitive to the choice of the text prompt although ensembling over multiple text prompts can provide more robust performance. Additionally, we discover that using the entire image along with an ellipse drawn around the target person is the most effective strategy for visual prompting. For gaze following, incorporating the extracted cues results in better generalization performance, especially when considering a larger set of cues, highlighting the potential of this approach.
6/7/2024