Revisiting the Impact of Pursuing Modularity for Code Generation

0
Sign in to get full access
Overview
- Examines the impact of pursuing modularity for code generation tasks
- Proposes a quantitative definition of modularity and investigates its effects
- Explores the trade-offs between modularity and other important metrics like performance and code quality
Plain English Explanation
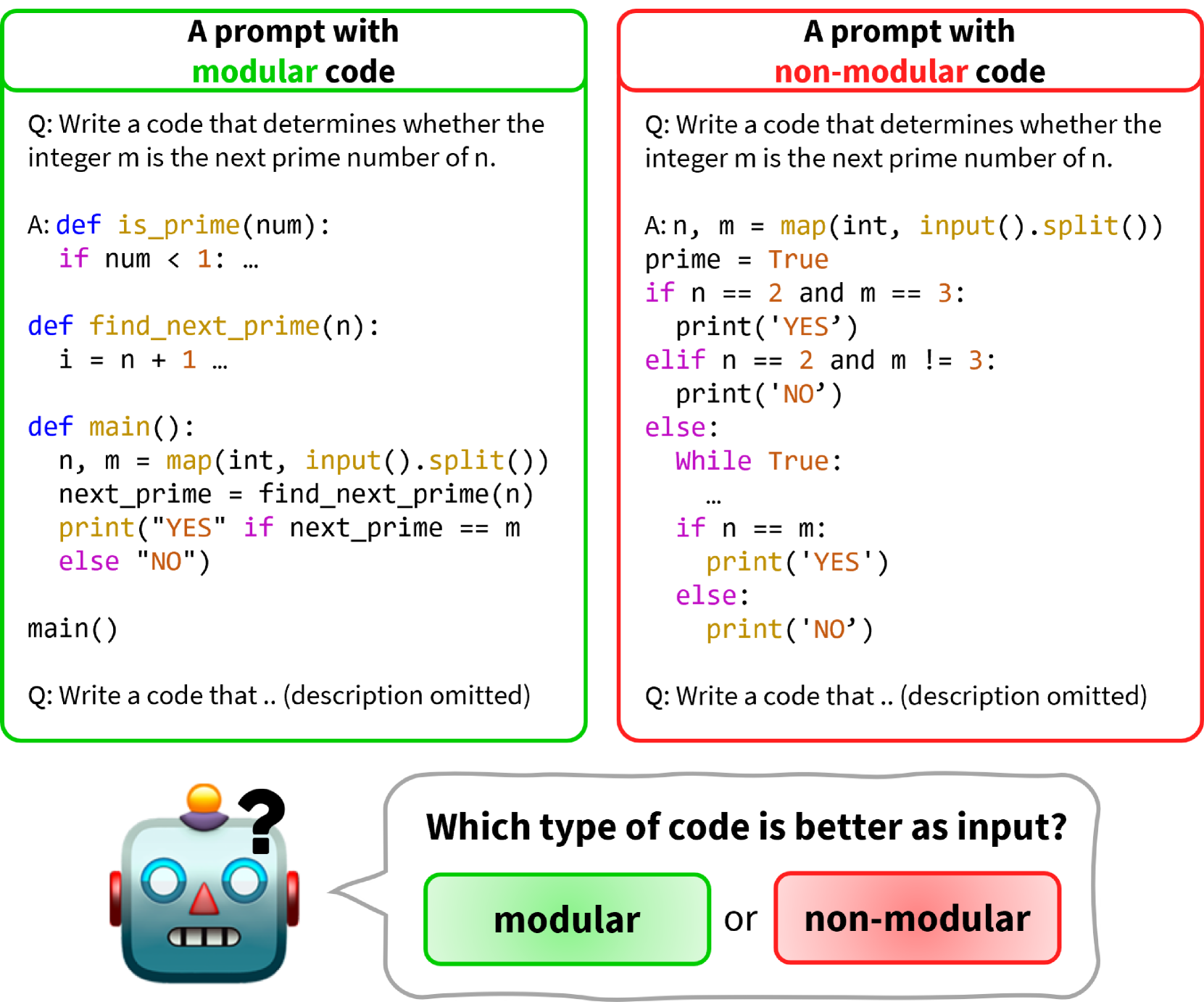
This paper takes a close look at the impact of designing modular code generation systems. Modular systems are those where the different components can be easily swapped out or updated without affecting the rest of the system. The researchers wanted to understand whether pursuing modularity has benefits, such as making the system more flexible and maintainable, or if it comes at the cost of other important factors like speed and code quality.
To study this, the researchers developed a quantitative way to measure the modularity of a code generation system. They then applied this measure to several different code generation models and compared the modular versions to more tightly integrated ones. The goal was to see how modularity impacts things like the model's prediction accuracy, the quality of the generated code, and the overall system performance.
The findings provide a nuanced perspective on the trade-offs involved. While increased modularity did offer some benefits in terms of flexibility and maintainability, it also led to reductions in the other metrics. The researchers conclude that there is no one-size-fits-all answer - the optimal level of modularity will depend on the specific needs and priorities of the code generation application.
Technical Explanation
The paper first proposes a quantitative definition of modularity for code generation systems. This is based on the concept of information hiding - the idea that different components of the system should have well-defined interfaces and encapsulate their internal implementation details. The researchers develop mathematical formulas to measure the degree of information hiding across the different modules of a code generation model.
They then apply this modularity measure to several state-of-the-art code generation architectures, including GPT-based and transformer-based models. For each architecture, they create both a modular and a more tightly integrated version, and compare the performance on metrics like prediction accuracy, code quality, and inference speed.
The results show that increasing modularity does come at a cost. The modular versions generally exhibited lower prediction accuracy and generated code of lower quality compared to their more integrated counterparts. There were also significant decreases in inference speed. However, the modular models did demonstrate greater flexibility and easier maintainability, as the researchers had hypothesized.
Critical Analysis
The paper provides a thoughtful and nuanced exploration of the trade-offs involved in designing modular code generation systems. By developing a quantitative measure of modularity, the researchers were able to systematically investigate its impact, which is valuable.
That said, the study is limited to a relatively small set of model architectures and datasets. It would be helpful to see the analysis expanded to a wider range of code generation tasks and model types to validate the generalizability of the findings. Additionally, the paper does not delve deeply into the specific mechanisms by which modularity affects performance, which would provide more insight.
Another potential area for further research is examining whether there are ways to maintain the benefits of modularity (e.g. flexibility, maintainability) without incurring as steep of a cost in other areas. Perhaps there are architectural designs or training techniques that can strike a better balance between modularity and other important metrics.
Overall, this is a well-executed study that raises important considerations for developers and researchers working on code generation systems. The insights around the modularity trade-offs are valuable, and the paper encourages critical thinking about optimizing system design for the specific needs of the application.
Conclusion
This paper takes an in-depth look at the impact of pursuing modularity in code generation systems. By developing a quantitative measure of modularity and applying it to various model architectures, the researchers were able to uncover the trade-offs involved.
The key finding is that increased modularity does come at a cost - it tends to reduce prediction accuracy, code quality, and inference speed compared to more tightly integrated designs. However, modular systems also offer benefits in terms of flexibility and maintainability.
The paper concludes that there is no one-size-fits-all answer when it comes to modularity. The optimal level will depend on the specific priorities and requirements of the code generation application. Developers and researchers must carefully weigh the pros and cons to strike the right balance.
Overall, this work provides valuable insights that can help guide the design of more effective and efficient code generation systems. It encourages a nuanced, evidence-based approach to addressing the complex challenges in this important field of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Revisiting the Impact of Pursuing Modularity for Code Generation
Deokyeong Kang, Ki Jung Seo, Taeuk Kim
Modular programming, which aims to construct the final program by integrating smaller, independent building blocks, has been regarded as a desirable practice in software development. However, with the rise of recent code generation agents built upon large language models (LLMs), a question emerges: is this traditional practice equally effective for these new tools? In this work, we assess the impact of modularity in code generation by introducing a novel metric for its quantitative measurement. Surprisingly, unlike conventional wisdom on the topic, we find that modularity is not a core factor for improving the performance of code generation models. We also explore potential explanations for why LLMs do not exhibit a preference for modular code compared to non-modular code.
Read more7/17/2024

0
A Survey on Large Language Models for Code Generation
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, Sunghun Kim
Large Language Models (LLMs) have garnered remarkable advancements across diverse code-related tasks, known as Code LLMs, particularly in code generation that generates source code with LLM from natural language descriptions. This burgeoning field has captured significant interest from both academic researchers and industry professionals due to its practical significance in software development, e.g., GitHub Copilot. Despite the active exploration of LLMs for a variety of code tasks, either from the perspective of natural language processing (NLP) or software engineering (SE) or both, there is a noticeable absence of a comprehensive and up-to-date literature review dedicated to LLM for code generation. In this survey, we aim to bridge this gap by providing a systematic literature review that serves as a valuable reference for researchers investigating the cutting-edge progress in LLMs for code generation. We introduce a taxonomy to categorize and discuss the recent developments in LLMs for code generation, covering aspects such as data curation, latest advances, performance evaluation, and real-world applications. In addition, we present a historical overview of the evolution of LLMs for code generation and offer an empirical comparison using the widely recognized HumanEval and MBPP benchmarks to highlight the progressive enhancements in LLM capabilities for code generation. We identify critical challenges and promising opportunities regarding the gap between academia and practical development. Furthermore, we have established a dedicated resource website (https://codellm.github.io) to continuously document and disseminate the most recent advances in the field.
Read more6/4/2024

0
What's Wrong with Your Code Generated by Large Language Models? An Extensive Study
Shihan Dou, Haoxiang Jia, Shenxi Wu, Huiyuan Zheng, Weikang Zhou, Muling Wu, Mingxu Chai, Jessica Fan, Caishuang Huang, Yunbo Tao, Yan Liu, Enyu Zhou, Ming Zhang, Yuhao Zhou, Yueming Wu, Rui Zheng, Ming Wen, Rongxiang Weng, Jingang Wang, Xunliang Cai, Tao Gui, Xipeng Qiu, Qi Zhang, Xuanjing Huang
The increasing development of large language models (LLMs) in code generation has drawn significant attention among researchers. To enhance LLM-based code generation ability, current efforts are predominantly directed towards collecting high-quality datasets and leveraging diverse training technologies. However, there is a notable lack of comprehensive studies examining the limitations and boundaries of these existing methods. To bridge this gap, we conducted an extensive empirical study evaluating the performance of three leading closed-source LLMs and four popular open-source LLMs on three commonly used benchmarks. Our investigation, which evaluated the length, cyclomatic complexity and API number of the generated code, revealed that these LLMs face challenges in generating successful code for more complex problems, and tend to produce code that is shorter yet more complicated as compared to canonical solutions. Additionally, we developed a taxonomy of bugs for incorrect codes that includes three categories and 12 sub-categories, and analyze the root cause for common bug types. Furthermore, to better understand the performance of LLMs in real-world projects, we manually created a real-world benchmark comprising 140 code generation tasks. Our analysis highlights distinct differences in bug distributions between actual scenarios and existing benchmarks. Finally, we propose a novel training-free iterative method that introduces self-critique, enabling LLMs to critique and correct their generated code based on bug types and compiler feedback. Experimental results demonstrate that our approach can significantly mitigate bugs and increase the passing rate by 29.2% after two iterations, indicating substantial potential for LLMs to handle more complex problems.
Read more7/9/2024

0
MoTCoder: Elevating Large Language Models with Modular of Thought for Challenging Programming Tasks
Jingyao Li, Pengguang Chen, Bin Xia, Hong Xu, Jiaya Jia
Large Language Models (LLMs) have showcased impressive capabilities in handling straightforward programming tasks. However, their performance tends to falter when confronted with more challenging programming problems. We observe that conventional models often generate solutions as monolithic code blocks, restricting their effectiveness in tackling intricate questions. To overcome this limitation, we present Modular-of-Thought Coder (MoTCoder). We introduce a pioneering framework for MoT instruction tuning, designed to promote the decomposition of tasks into logical sub-tasks and sub-modules. Our investigations reveal that, through the cultivation and utilization of sub-modules, MoTCoder significantly improves both the modularity and correctness of the generated solutions, leading to substantial relative pass@1 improvements of 12.9% on APPS and 9.43% on CodeContests. Our codes are available at https://github.com/dvlab-research/MoTCoder.
Read more8/23/2024