Revisiting MoE and Dense Speed-Accuracy Comparisons for LLM Training
2405.15052
0
0

Abstract
Mixture-of-Experts (MoE) enjoys performance gain by increasing model capacity while keeping computation cost constant. When comparing MoE to dense models, prior work typically adopt the following setting: 1) use FLOPs or activated parameters as a measure of model complexity; 2) train all models to the same number of tokens. We argue that this setting favors MoE as FLOPs and activated parameters do not accurately measure the communication overhead in sparse layers, leading to a larger actual training budget for MoE. In this work, we revisit the settings by adopting step time as a more accurate measure of model complexity, and by determining the total compute budget under the Chinchilla compute-optimal settings. To efficiently run MoE on modern accelerators, we adopt a 3D sharding method that keeps the dense-to-MoE step time increase within a healthy range. We evaluate MoE and dense LLMs on a set of nine 0-shot and two 1-shot English tasks, as well as MMLU 5-shot and GSM8K 8-shot across three model scales at 6.4B, 12.6B, and 29.6B. Experimental results show that even under these settings, MoE consistently outperform dense LLMs on the speed-accuracy trade-off curve with meaningful gaps. Our full model implementation and sharding strategy will be released at~url{https://github.com/apple/axlearn}
Create account to get full access
Overview
- Revisits the performance comparison between Mixture of Experts (MoE) and dense models for large language model (LLM) training
- Examines the speed-accuracy tradeoffs between these two approaches
- Provides insights that challenge some common assumptions about the relative benefits of MoE and dense models
Plain English Explanation
This research paper takes a fresh look at the debate around using Mixture of Experts (MoE) models versus dense models for training large language models (LLMs). MoE models divide the work across multiple specialized "expert" networks, while dense models have a single, comprehensive network.
The paper's key finding is that the conventional wisdom around MoE models may need to be re-evaluated. Previous research had suggested MoE models offered significant speed and efficiency advantages over dense models. However, this new study indicates the differences in speed and accuracy may not be as stark as once thought.
The authors explore various factors, such as model scaling and inference optimization, that impact the relative performance of MoE and dense models. They find that with careful design and engineering, dense models can achieve comparable or even better speed and accuracy than MoE models in certain situations.
This research challenges the assumption that MoE models are inherently superior to dense models for LLM training. It suggests the choice between the two approaches may come down to factors like the specific use case, resource constraints, and model architecture rather than a clear-cut performance advantage.
Technical Explanation
The paper begins by revisiting the speed-accuracy tradeoffs between Mixture of Experts (MoE) and dense models for training large language models (LLMs). Previous research, such as Dense Training, Sparse Inference: Rethinking Sparse Model Training, had suggested MoE models offered significant advantages in terms of speed and efficiency.
However, the authors of this paper argue that the landscape has shifted, and the relative performance of MoE and dense models may not be as clear-cut. They explore various factors that impact the speed and accuracy of these two approaches, including model scaling and inference optimization.
The paper presents experiments that compare the speed and accuracy of MoE and dense models across different model sizes and tasks. The results indicate that with careful design and engineering, dense models can achieve comparable or even better performance than MoE models in certain scenarios.
The authors also discuss the potential trade-offs and considerations when choosing between MoE and dense models for LLM training. Factors like the specific use case, resource constraints, and model architecture may play a significant role in determining the optimal approach.
Critical Analysis
The paper raises important points that challenge some of the common assumptions about the relative benefits of MoE and dense models for LLM training. The authors acknowledge that previous research had generally favored MoE models, but they argue that the landscape has evolved, and the differences in speed and accuracy may not be as stark as once believed.
One potential limitation of the study is that it focuses on a specific set of model architectures and tasks. While the authors claim their findings are generally applicable, it would be valuable to see the analysis extended to a wider range of LLM architectures and use cases.
Additionally, the paper does not delve deeply into the practical implications of choosing between MoE and dense models. Questions around deployment, scalability, and the unique challenges faced by each approach could be explored further.
It is also worth considering whether the findings of this paper are influenced by the rapid advancements in hardware and software optimization for LLM training. As these technologies continue to evolve, the relative performance of MoE and dense models may shift again, necessitating further investigation.
Conclusion
This research paper provides a timely re-evaluation of the speed-accuracy tradeoffs between Mixture of Experts (MoE) and dense models for large language model (LLM) training. The authors challenge the conventional wisdom that MoE models are inherently superior, presenting experimental evidence that dense models can achieve comparable or even better performance in certain scenarios.
The findings of this paper have important implications for the ongoing debate around the optimal approach to LLM training. It suggests that the choice between MoE and dense models may not be straightforward and may depend on a variety of factors, including the specific use case, resource constraints, and model architecture.
As the field of large language models continues to evolve, this research highlights the importance of revisiting and re-evaluating established assumptions. By taking a fresh look at the speed-accuracy tradeoffs, the authors have provided valuable insights that can inform the design and deployment of future large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda
0
0
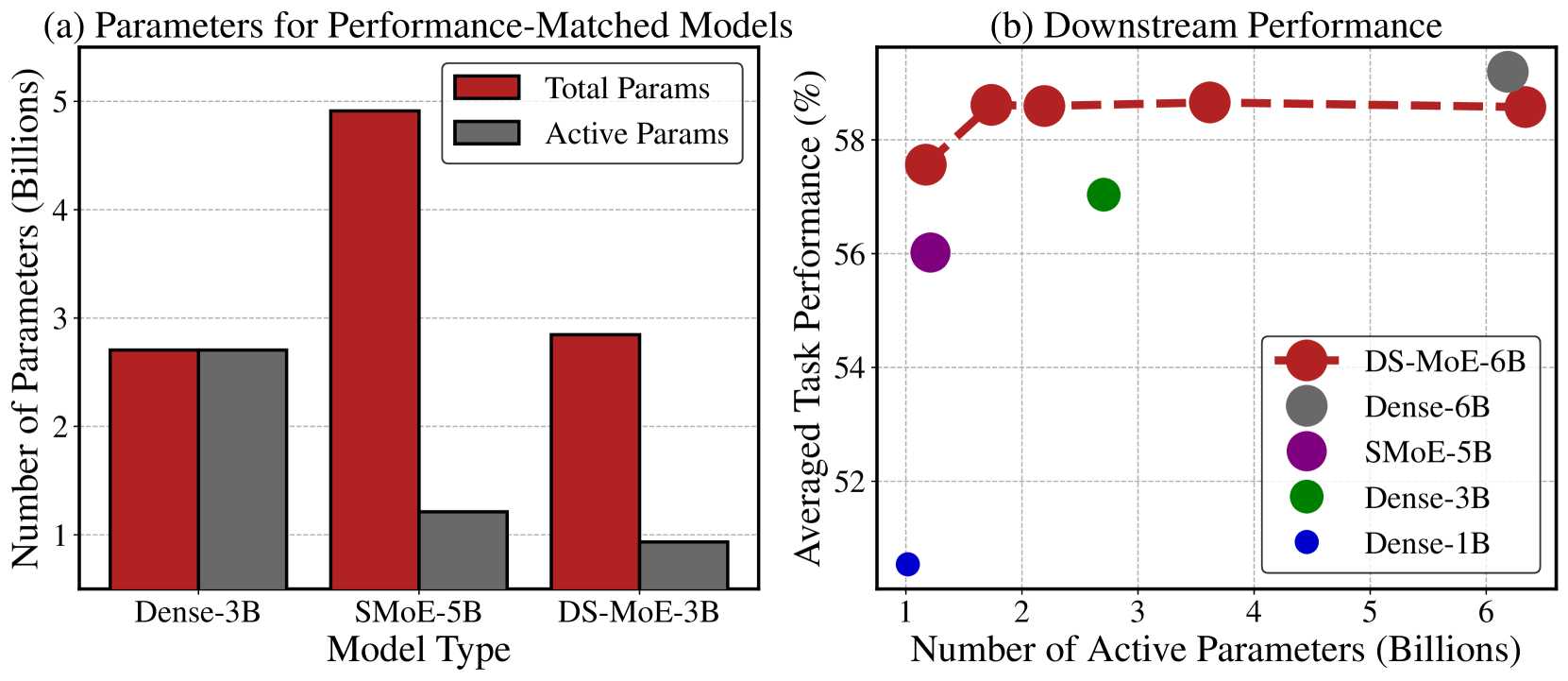
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
4/9/2024
Toward Inference-optimal Mixture-of-Expert Large Language Models
Longfei Yun, Yonghao Zhuang, Yao Fu, Eric P Xing, Hao Zhang
0
0
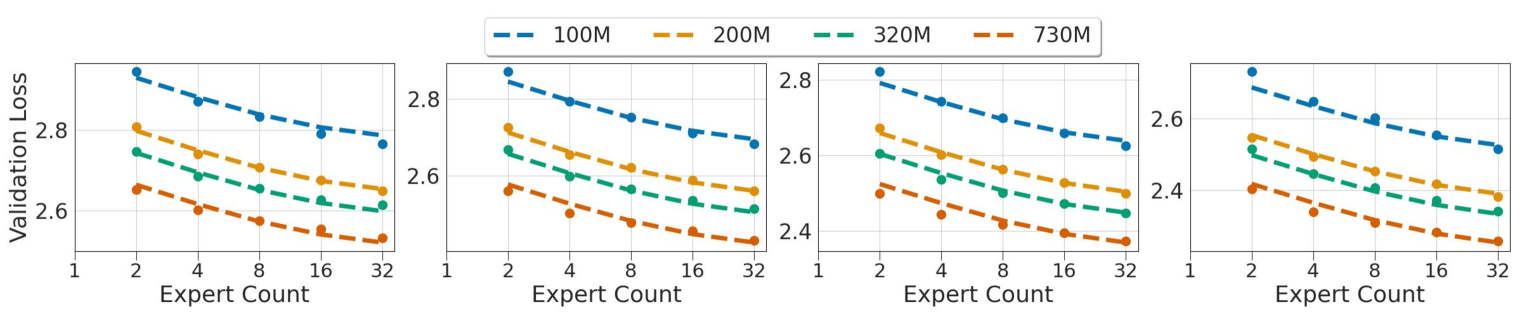
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
4/4/2024
LocMoE: A Low-Overhead MoE for Large Language Model Training
Jing Li, Zhijie Sun, Xuan He, Li Zeng, Yi Lin, Entong Li, Binfan Zheng, Rongqian Zhao, Xin Chen
0
0
The Mixtures-of-Experts (MoE) model is a widespread distributed and integrated learning method for large language models (LLM), which is favored due to its ability to sparsify and expand models efficiently. However, the performance of MoE is limited by load imbalance and high latency of All-to-All communication, along with relatively redundant computation owing to large expert capacity. Load imbalance may result from existing routing policies that consistently tend to select certain experts. The frequent inter-node communication in the All-to-All procedure also significantly prolongs the training time. To alleviate the above performance problems, we propose a novel routing strategy that combines load balance and locality by converting partial inter-node communication to that of intra-node. Notably, we elucidate that there is a minimum threshold for expert capacity, calculated through the maximal angular deviation between the gating weights of the experts and the assigned tokens. We port these modifications on the PanGu-Sigma model based on the MindSpore framework with multi-level routing and conduct experiments on Ascend clusters. The experiment results demonstrate that the proposed LocMoE reduces training time per epoch by 12.68% to 22.24% compared to classical routers, such as hash router and switch router, without impacting the model accuracy.
5/24/2024

Examining Post-Training Quantization for Mixture-of-Experts: A Benchmark
Pingzhi Li, Xiaolong Jin, Yu Cheng, Tianlong Chen
0
0
Large Language Models~(LLMs) have become foundational in the realm of natural language processing, demonstrating performance improvements as model sizes increase. The Mixture-of-Experts~(MoE) approach offers a promising way to scale LLMs more efficiently by using fewer computational FLOPs through sparse activation. However, it suffers from significant memory overheads, necessitating model compression techniques. Post-training quantization, a popular method for model compression, proves less effective when directly applied to MoE models due to MoE's overlooked inherent sparsity. This paper explores several MoE structure-aware quantization heuristics, ranging from coarse to fine granularity, from MoE block to individual linear weight. Our investigations reveal critical principles: different MoE structures (i.e., blocks, experts, linear layers) require varying numbers of weight bits for effective and efficient quantization. Conclusions are supported by extensive benchmarking across two representative MoE models and six tasks. We further introduce novel enhancements to more accurately identify the most critical weights in MoE quantization that necessitate higher bit allocations, including the linear weight outlier scorer and MoE block scorer. Additionally, subsequent experiments validate our findings in the context of both weight and activation quantization.
6/13/2024