Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
2404.05567
0
0
Abstract
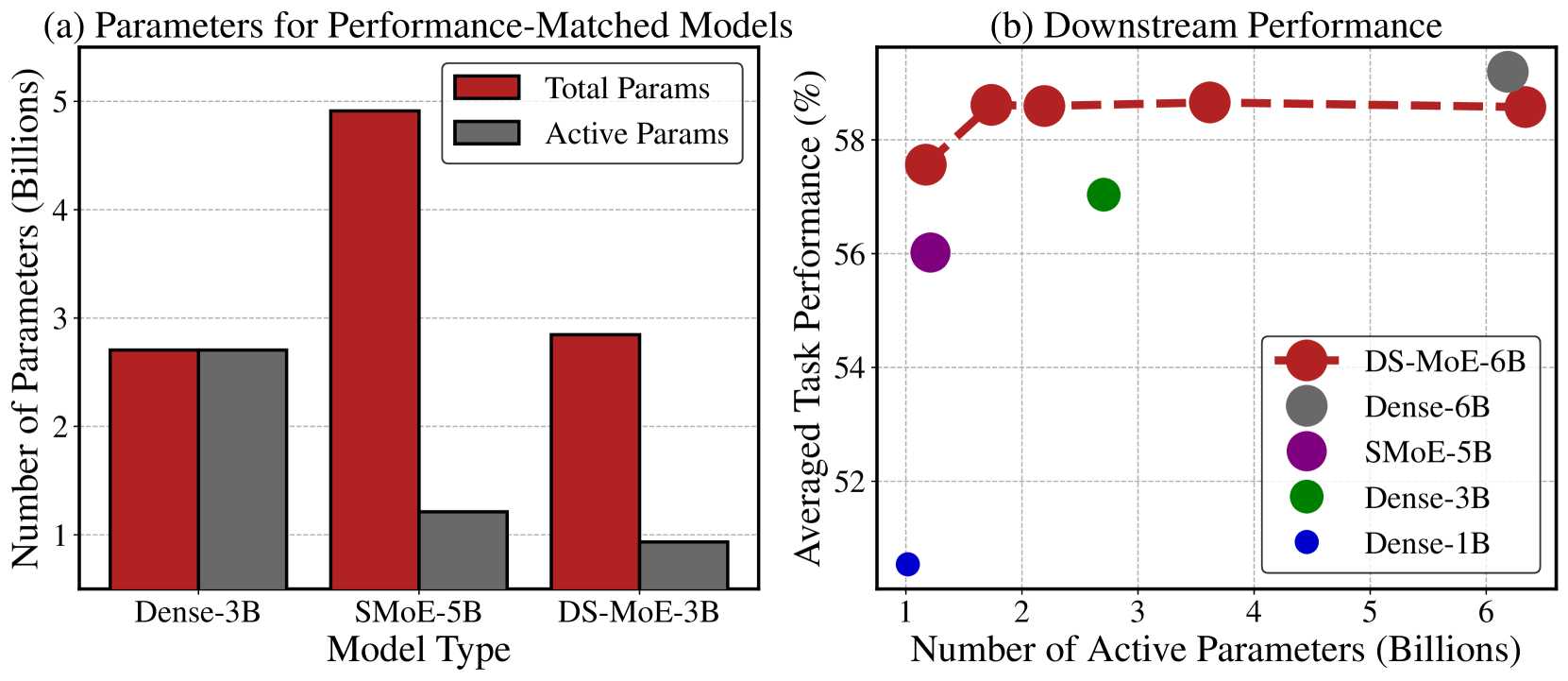
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
Create account to get full access
Overview
- This paper proposes a new approach to training and deploying Mixture-of-Experts (MoE) language models, which are large models that combine multiple specialized "expert" sub-models.
- The key ideas are to "densely train" the model during the training phase, but then use "sparse inference" during deployment, only activating a small subset of the experts for each input.
- This allows the model to achieve high performance while using fewer computational resources during deployment, making it more practical for real-world applications.
Plain English Explanation
The researchers behind this paper have come up with a new way to train and use a special type of large language model called a Mixture-of-Experts (MoE) model. MoE models work by having multiple "expert" sub-models, each of which specializes in different types of language tasks.
The key innovation in this paper is the idea of "dense training" versus "sparse inference." During the training phase, the researchers train all of the expert sub-models intensively, allowing the model to become highly capable. However, when the model is actually used to generate text, it only activates a small subset of the experts for each input. This "sparse inference" allows the model to maintain high performance while using far fewer computational resources.
This is an important advancement because it makes these powerful MoE models much more practical for real-world applications, where the computational cost of running a massive language model is a major concern. By training the model densely but using it sparsely, the researchers have found a way to get the best of both worlds - high capability coupled with efficient deployment.
Technical Explanation
The paper proposes a new training and inference paradigm for Mixture-of-Experts (MoE) language models, as detailed in Prompt-Prompted Mixture of Experts for Efficient LLM Generation and Embracing the Unknown: A Step-by-Step Approach Towards Reliable Mixture-of-Experts Models.
During the training phase, the model is "densely trained," meaning all of the expert sub-models are trained intensively on a wide range of language tasks. This allows the model to develop highly capable and specialized sub-models. However, during inference (deployment), the model only activates a small, "sparse" subset of the experts for each input. This "dense training, sparse inference" approach allows the model to maintain high performance while using far fewer computational resources.
The researchers compare this to prior work on Sparsely Gated Mixture-of-Experts Models and SEER: Efficient Inference of Large-Scale Mixture of Experts Models, which also aim to improve the efficiency of MoE models. However, the dense training approach in this paper leads to better overall model capability compared to these prior sparse training methods.
Additionally, the paper explores ways to further improve the efficiency of these densely trained MoE models, including using prompting techniques from OMNI: Efficient Multimodal Generalist Models via Scalable Training and Task-Agnostic Prompting.
Critical Analysis
The paper presents a compelling approach to improving the practicality of large Mixture-of-Experts language models. The key idea of dense training followed by sparse inference is a promising direction that could lead to more efficient and capable language models for real-world applications.
That said, the paper does not explore some potential limitations or drawbacks of this approach. For example, the researchers do not discuss how the dense training phase may impact the overall training time and computational cost, which could be a concern for some use cases. Additionally, the paper does not address potential issues around the reliability and robustness of the sparse inference approach, such as how it might handle out-of-distribution inputs or edge cases.
Further research would be needed to fully understand the tradeoffs and limitations of this approach, as well as explore ways to address any shortcomings. Nonetheless, the core ideas presented in the paper represent an important step forward in developing more practical and efficient large language models.
Conclusion
This paper proposes a novel training and inference approach for Mixture-of-Experts language models, which involves densely training the model during the training phase but then only activating a sparse subset of experts during deployment. This "dense training, sparse inference" method allows the model to maintain high performance while using fewer computational resources, making it more practical for real-world applications.
The key insights and contributions of this work include the introduction of this training/inference paradigm, as well as ways to further improve the efficiency of these densely trained MoE models through techniques like prompting. While there may be some limitations that require further exploration, the overall approach represents an important advancement in the field of large language models and their practical application.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Revisiting MoE and Dense Speed-Accuracy Comparisons for LLM Training
Xianzhi Du, Tom Gunter, Xiang Kong, Mark Lee, Zirui Wang, Aonan Zhang, Nan Du, Ruoming Pang
0
0
Mixture-of-Experts (MoE) enjoys performance gain by increasing model capacity while keeping computation cost constant. When comparing MoE to dense models, prior work typically adopt the following setting: 1) use FLOPs or activated parameters as a measure of model complexity; 2) train all models to the same number of tokens. We argue that this setting favors MoE as FLOPs and activated parameters do not accurately measure the communication overhead in sparse layers, leading to a larger actual training budget for MoE. In this work, we revisit the settings by adopting step time as a more accurate measure of model complexity, and by determining the total compute budget under the Chinchilla compute-optimal settings. To efficiently run MoE on modern accelerators, we adopt a 3D sharding method that keeps the dense-to-MoE step time increase within a healthy range. We evaluate MoE and dense LLMs on a set of nine 0-shot and two 1-shot English tasks, as well as MMLU 5-shot and GSM8K 8-shot across three model scales at 6.4B, 12.6B, and 29.6B. Experimental results show that even under these settings, MoE consistently outperform dense LLMs on the speed-accuracy trade-off curve with meaningful gaps. Our full model implementation and sharding strategy will be released at~url{https://github.com/apple/axlearn}
5/27/2024
Toward Inference-optimal Mixture-of-Expert Large Language Models
Longfei Yun, Yonghao Zhuang, Yao Fu, Eric P Xing, Hao Zhang
0
0
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
4/4/2024
XMoE: Sparse Models with Fine-grained and Adaptive Expert Selection
Yuanhang Yang, Shiyi Qi, Wenchao Gu, Chaozheng Wang, Cuiyun Gao, Zenglin Xu
0
0
Sparse models, including sparse Mixture-of-Experts (MoE) models, have emerged as an effective approach for scaling Transformer models. However, they often suffer from computational inefficiency since a significant number of parameters are unnecessarily involved in computations via multiplying values by zero or low activation values. To address this issue, we present tool, a novel MoE designed to enhance both the efficacy and efficiency of sparse MoE models. tool leverages small experts and a threshold-based router to enable tokens to selectively engage only essential parameters. Our extensive experiments on language modeling and machine translation tasks demonstrate that tool can enhance model performance while decreasing the computation load at MoE layers by over 50% without sacrificing performance. Furthermore, we present the versatility of tool by applying it to dense models, enabling sparse computation during inference. We provide a comprehensive analysis and make our code available at https://github.com/ysngki/XMoE.
5/27/2024
🔮
From Sparse to Soft Mixtures of Experts
Joan Puigcerver, Carlos Riquelme, Basil Mustafa, Neil Houlsby
0
0
Sparse mixture of expert architectures (MoEs) scale model capacity without significant increases in training or inference costs. Despite their success, MoEs suffer from a number of issues: training instability, token dropping, inability to scale the number of experts, or ineffective finetuning. In this work, we propose Soft MoE, a fully-differentiable sparse Transformer that addresses these challenges, while maintaining the benefits of MoEs. Soft MoE performs an implicit soft assignment by passing different weighted combinations of all input tokens to each expert. As in other MoEs, experts in Soft MoE only process a subset of the (combined) tokens, enabling larger model capacity (and performance) at lower inference cost. In the context of visual recognition, Soft MoE greatly outperforms dense Transformers (ViTs) and popular MoEs (Tokens Choice and Experts Choice). Furthermore, Soft MoE scales well: Soft MoE Huge/14 with 128 experts in 16 MoE layers has over 40x more parameters than ViT Huge/14, with only 2% increased inference time, and substantially better quality.
5/28/2024