Revisiting subword tokenization: A case study on affixal negation in large language models
2404.02421
0
0
Abstract
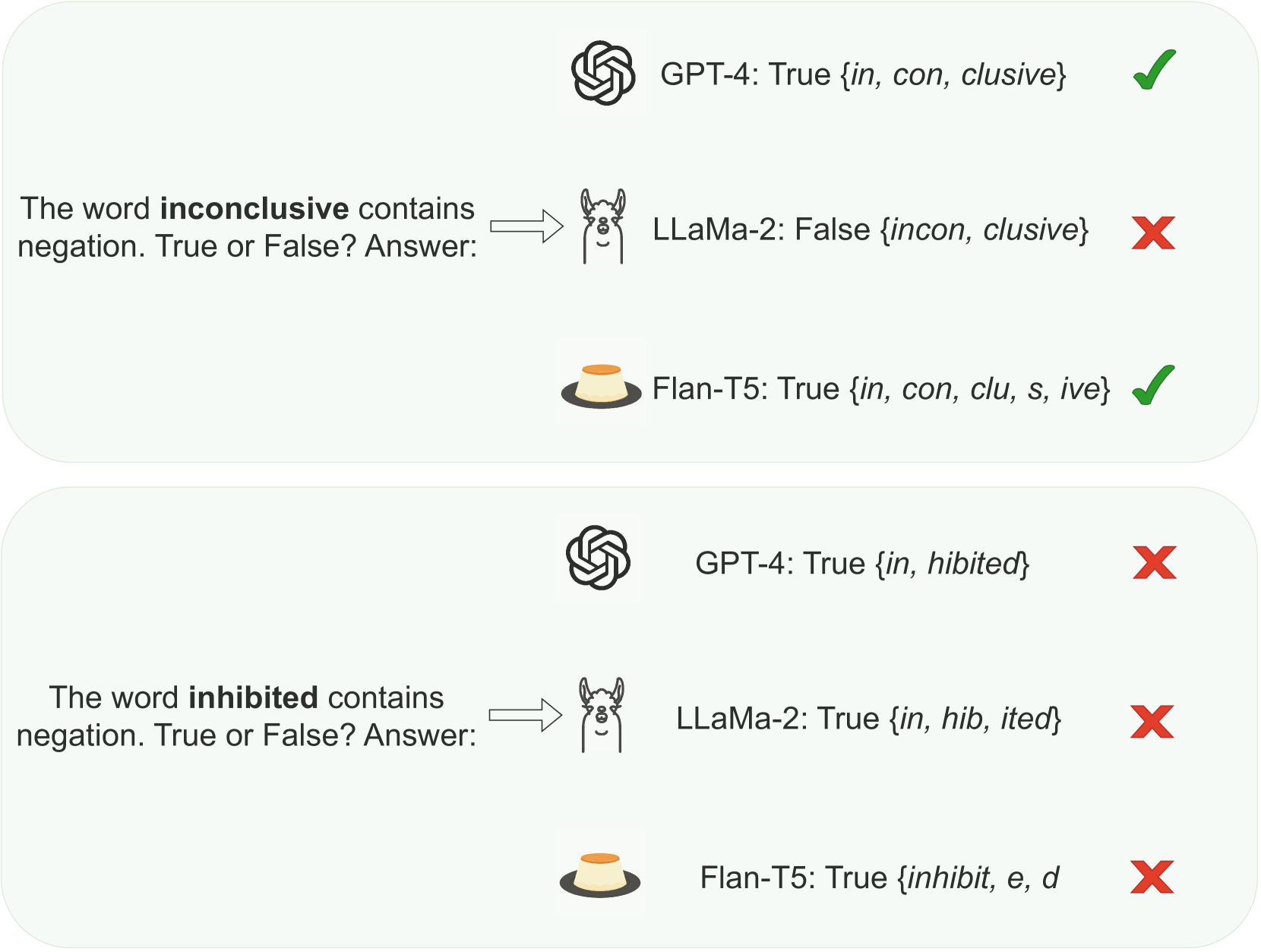
In this work, we measure the impact of affixal negation on modern English large language models (LLMs). In affixal negation, the negated meaning is expressed through a negative morpheme, which is potentially challenging for LLMs as their tokenizers are often not morphologically plausible. We conduct extensive experiments using LLMs with different subword tokenization methods, which lead to several insights on the interaction between tokenization performance and negation sensitivity. Despite some interesting mismatches between tokenization accuracy and negation detection performance, we show that models can, on the whole, reliably recognize the meaning of affixal negation.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores how well current subword tokenization methods used in large language models can preserve negative affixes (prefixes and suffixes that indicate negation).
- The researchers investigate whether common tokenization approaches like WordPiece and BPE can adequately handle negation, which is an important linguistic phenomenon.
- They use a case study on affixal negation to evaluate the strengths and limitations of these tokenization techniques.
Plain English Explanation
Subword tokenization is a way of breaking down words into smaller pieces that language models can understand. This is important because models can't always handle complete words, especially rare or complex ones. Tokenization methods like WordPiece and BPE try to find the optimal way to break words into subparts.
The researchers in this paper looked at how well these tokenization approaches handle negation - words that indicate the opposite of something, like "un-", "non-", or "-less". Negation is a crucial part of language, but it can be tricky for models to understand if the negative prefix or suffix gets split up during tokenization.
For example, the word "unhappy" might get broken into "un" and "happy" by the tokenizer. This could cause the model to miss the fact that "un-" means "not" and interpret the word differently. The researchers wanted to see if current tokenization methods are good enough at preserving these important negative affixes.
Technical Explanation
The paper conducts a case study on how well subword tokenization handles affixal negation - negation conveyed through prefixes and suffixes. The researchers evaluate two popular tokenization approaches, WordPiece and BPE, on their ability to correctly identify negative affixes in a large language model.
They create a dataset of negated words and non-negated counterparts, and analyze how the tokenizers split these words. The key metrics are whether the negative prefix/suffix is kept together as a single token, and whether the model correctly associates it with negation semantics.
The results show that current tokenization methods struggle to fully preserve negative affixes. Many get split into separate tokens, losing the connection to negation. The researchers also find differences in performance between prefix and suffix negation, with suffix negation being more challenging.
The paper discusses how this limitation of subword tokenization could impact language model understanding and downstream applications that rely on accurate negation processing. It suggests avenues for improving tokenization to better handle this important linguistic phenomenon.
Critical Analysis
The paper provides a thoughtful analysis of an important issue in natural language processing - the ability of language models to correctly handle negation. The case study on affixal negation is a clever way to rigorously evaluate this, and the results indicate clear room for improvement in subword tokenization approaches.
One potential limitation is that the analysis is focused on a specific linguistic construct (affixal negation) within a constrained dataset. It would be helpful to see how these findings extrapolate to more natural, open-ended language use. The paper also doesn't delve into the potential impact on downstream applications, which could be an interesting area for further exploration.
Additionally, while the paper highlights the shortcomings of current tokenization methods, it doesn't provide detailed solutions. The discussion of future research directions is high-level, so readers are left wondering what concrete steps could be taken to address the identified issues.
Overall, this is a valuable contribution that shines a light on an important but often overlooked aspect of language model performance. The critical analysis encourages readers to think carefully about the nuances of negation and how they might be better addressed in the development of more robust natural language processing systems.
Conclusion
This paper takes a close look at how well current subword tokenization techniques, such as WordPiece and BPE, are able to preserve negative affixes - prefixes and suffixes that convey negation. Through a detailed case study, the researchers find that these common tokenization approaches often struggle to keep negative affixes together as single tokens, which can undermine a language model's understanding of negation.
The insights from this work highlight an important limitation in state-of-the-art language models, which rely heavily on subword tokenization. Correctly handling negation is crucial for natural language processing, as it allows models to accurately interpret the meaning and sentiment of text. The paper's findings suggest that further research is needed to develop tokenization methods that are more adept at preserving linguistic phenomena like affixal negation.
By shedding light on this issue, the paper encourages the NLP community to think more deeply about the nuances of language and how they can be better represented in the models we develop. Addressing the shortcomings of subword tokenization when it comes to negation could lead to significant improvements in language understanding and the real-world applications that depend on it.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
A Systematic Analysis of Subwords and Cross-Lingual Transfer in Multilingual Translation
Francois Meyer, Jan Buys
0
0
Multilingual modelling can improve machine translation for low-resource languages, partly through shared subword representations. This paper studies the role of subword segmentation in cross-lingual transfer. We systematically compare the efficacy of several subword methods in promoting synergy and preventing interference across different linguistic typologies. Our findings show that subword regularisation boosts synergy in multilingual modelling, whereas BPE more effectively facilitates transfer during cross-lingual fine-tuning. Notably, our results suggest that differences in orthographic word boundary conventions (the morphological granularity of written words) may impede cross-lingual transfer more significantly than linguistic unrelatedness. Our study confirms that decisions around subword modelling can be key to optimising the benefits of multilingual modelling.
4/1/2024
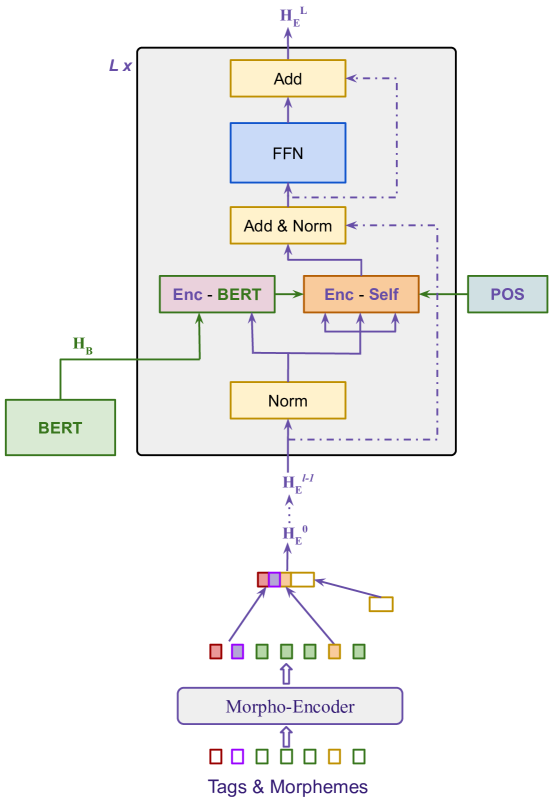
Low-resource neural machine translation with morphological modeling
Antoine Nzeyimana
0
0
Morphological modeling in neural machine translation (NMT) is a promising approach to achieving open-vocabulary machine translation for morphologically-rich languages. However, existing methods such as sub-word tokenization and character-based models are limited to the surface forms of the words. In this work, we propose a framework-solution for modeling complex morphology in low-resource settings. A two-tier transformer architecture is chosen to encode morphological information at the inputs. At the target-side output, a multi-task multi-label training scheme coupled with a beam search-based decoder are found to improve machine translation performance. An attention augmentation scheme to the transformer model is proposed in a generic form to allow integration of pre-trained language models and also facilitate modeling of word order relationships between the source and target languages. Several data augmentation techniques are evaluated and shown to increase translation performance in low-resource settings. We evaluate our proposed solution on Kinyarwanda - English translation using public-domain parallel text. Our final models achieve competitive performance in relation to large multi-lingual models. We hope that our results will motivate more use of explicit morphological information and the proposed model and data augmentations in low-resource NMT.
4/4/2024
💬
On the Effect of (Near) Duplicate Subwords in Language Modelling
Anton Schafer, Thomas Hofmann, Imanol Schlag, Tiago Pimentel
0
0
Tokenisation is a core part of language models (LMs). It involves splitting a character sequence into subwords which are assigned arbitrary indices before being served to the LM. While typically lossless, however, this process may lead to less sample efficient LM training: as it removes character-level information, it could make it harder for LMs to generalise across similar subwords, such as now and Now. We refer to such subwords as near duplicates. In this paper, we study the impact of near duplicate subwords on LM training efficiency. First, we design an experiment that gives us an upper bound to how much we should expect a model to improve if we could perfectly generalise across near duplicates. We do this by duplicating each subword in our LM's vocabulary, creating perfectly equivalent classes of subwords. Experimentally, we find that LMs need roughly 17% more data when trained in a fully duplicated setting. Second, we investigate the impact of naturally occurring near duplicates on LMs. Here, we see that merging them considerably hurts LM performance. Therefore, although subword duplication negatively impacts LM training efficiency, naturally occurring near duplicates may not be as similar as anticipated, limiting the potential for performance improvements.
5/6/2024
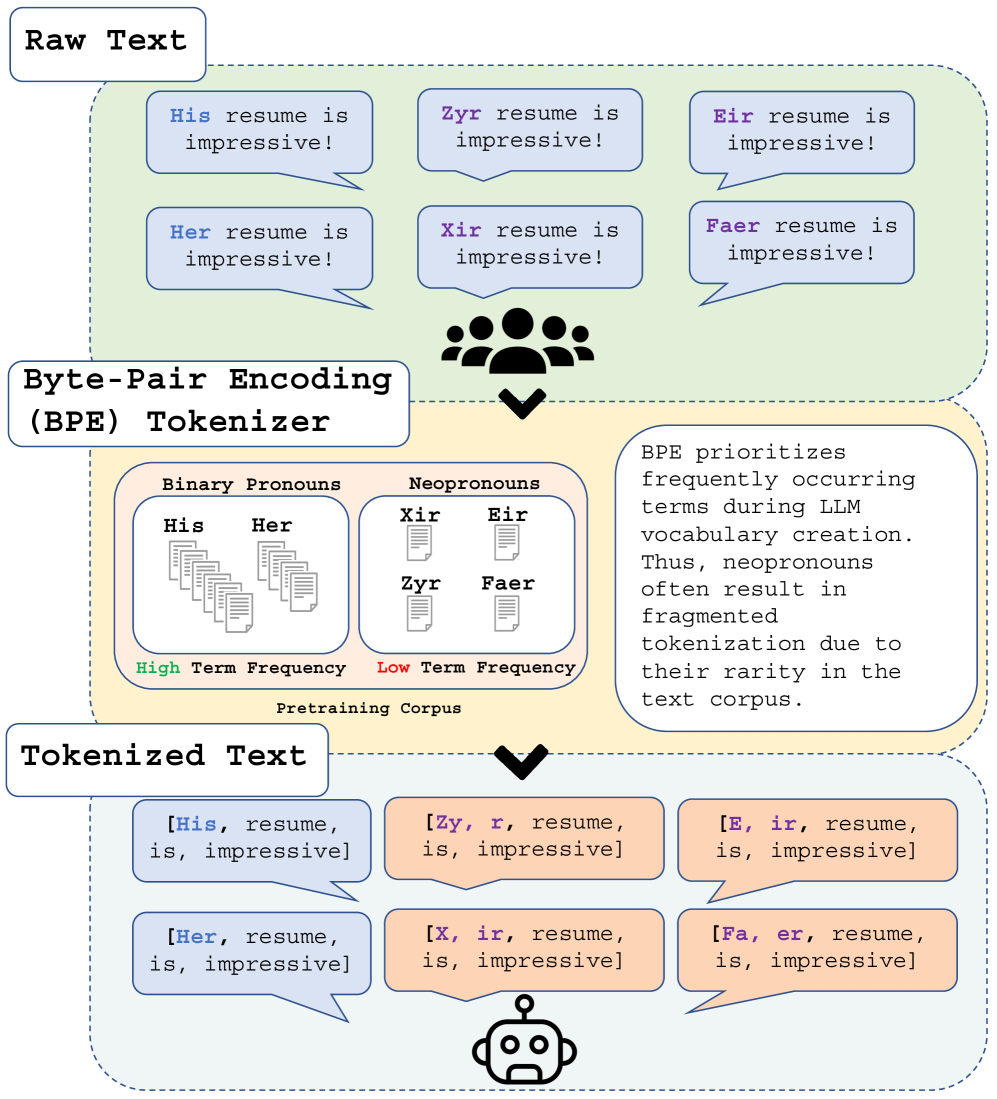
Tokenization Matters: Navigating Data-Scarce Tokenization for Gender Inclusive Language Technologies
Anaelia Ovalle, Ninareh Mehrabi, Palash Goyal, Jwala Dhamala, Kai-Wei Chang, Richard Zemel, Aram Galstyan, Yuval Pinter, Rahul Gupta
0
0
Gender-inclusive NLP research has documented the harmful limitations of gender binary-centric large language models (LLM), such as the inability to correctly use gender-diverse English neopronouns (e.g., xe, zir, fae). While data scarcity is a known culprit, the precise mechanisms through which scarcity affects this behavior remain underexplored. We discover LLM misgendering is significantly influenced by Byte-Pair Encoding (BPE) tokenization, the tokenizer powering many popular LLMs. Unlike binary pronouns, BPE overfragments neopronouns, a direct consequence of data scarcity during tokenizer training. This disparate tokenization mirrors tokenizer limitations observed in multilingual and low-resource NLP, unlocking new misgendering mitigation strategies. We propose two techniques: (1) pronoun tokenization parity, a method to enforce consistent tokenization across gendered pronouns, and (2) utilizing pre-existing LLM pronoun knowledge to improve neopronoun proficiency. Our proposed methods outperform finetuning with standard BPE, improving neopronoun accuracy from 14.1% to 58.4%. Our paper is the first to link LLM misgendering to tokenization and deficient neopronoun grammar, indicating that LLMs unable to correctly treat neopronouns as pronouns are more prone to misgender.
4/9/2024