Tokenization Matters: Navigating Data-Scarce Tokenization for Gender Inclusive Language Technologies
2312.11779
0
0
Abstract
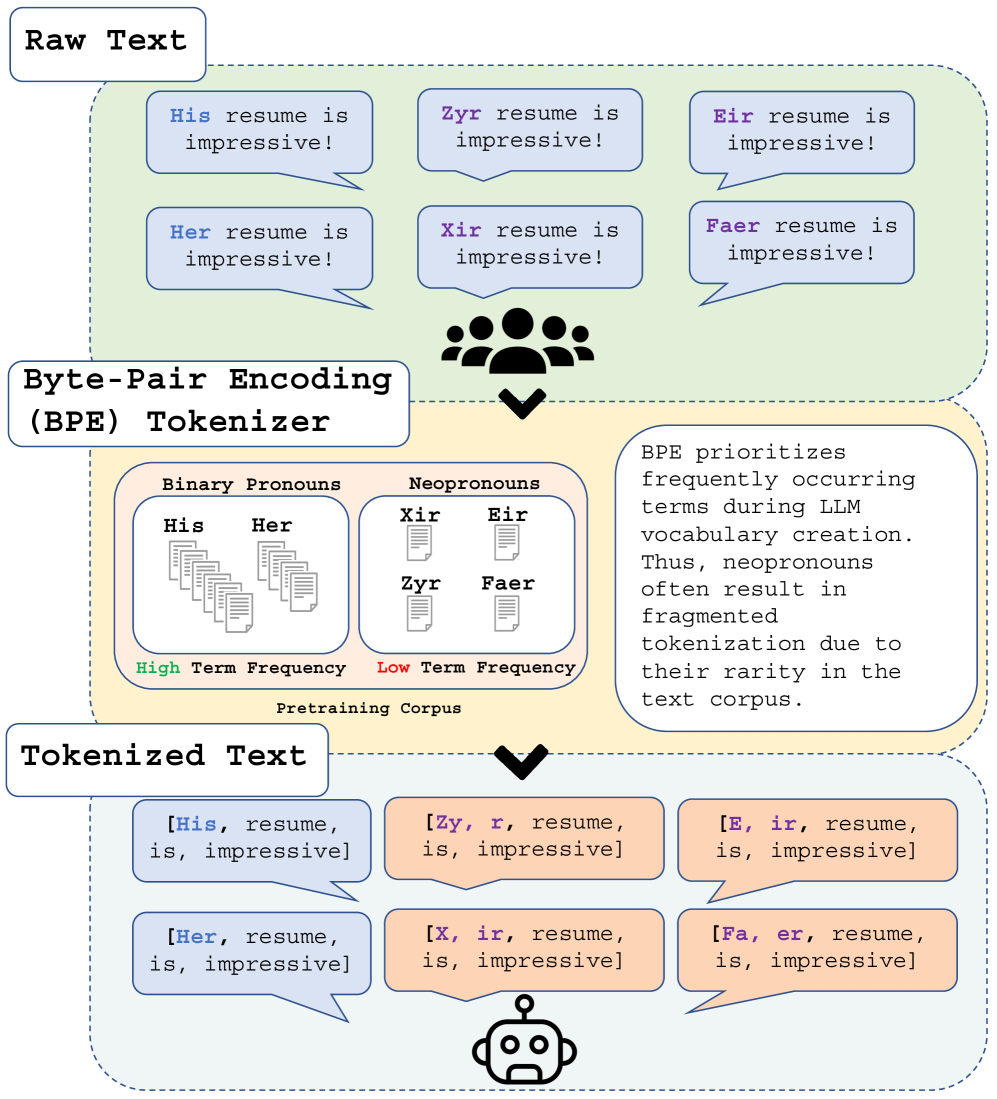
Gender-inclusive NLP research has documented the harmful limitations of gender binary-centric large language models (LLM), such as the inability to correctly use gender-diverse English neopronouns (e.g., xe, zir, fae). While data scarcity is a known culprit, the precise mechanisms through which scarcity affects this behavior remain underexplored. We discover LLM misgendering is significantly influenced by Byte-Pair Encoding (BPE) tokenization, the tokenizer powering many popular LLMs. Unlike binary pronouns, BPE overfragments neopronouns, a direct consequence of data scarcity during tokenizer training. This disparate tokenization mirrors tokenizer limitations observed in multilingual and low-resource NLP, unlocking new misgendering mitigation strategies. We propose two techniques: (1) pronoun tokenization parity, a method to enforce consistent tokenization across gendered pronouns, and (2) utilizing pre-existing LLM pronoun knowledge to improve neopronoun proficiency. Our proposed methods outperform finetuning with standard BPE, improving neopronoun accuracy from 14.1% to 58.4%. Our paper is the first to link LLM misgendering to tokenization and deficient neopronoun grammar, indicating that LLMs unable to correctly treat neopronouns as pronouns are more prone to misgender.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the issue of tokenization and addressing misgendering in large language models (LLMs).
- The authors propose a new approach called "pronoun tokenization parity" to improve gender-inclusive natural language processing.
- The goal is to ensure LLMs can accurately handle a range of gender-neutral and gender-diverse pronouns.
Plain English Explanation
When people communicate using language models like chatbots or digital assistants, it's important that the language models can properly recognize and respond to different pronouns, including gender-neutral pronouns like ["xem"] or ["x", "em"]. Otherwise, the language models may misgender the person they're talking to, which can be hurtful and alienating.
This paper looks at how language models currently handle pronouns, and proposes a new approach called "pronoun tokenization parity" to make the models more inclusive. The idea is to train the language models to accurately process a wider range of pronouns, so they can have natural conversations without accidentally misgendering people.
By addressing this issue of pronoun tokenization, the researchers hope to make language models more respectful and welcoming to people of all gender identities.
Technical Explanation
The paper first provides background on the growing need for gender-inclusive NLP to address issues like position bias and pronoun use fidelity in language models.
The authors then introduce their "pronoun tokenization parity" approach, which aims to ensure LLMs can accurately handle a wide range of gender-neutral and gender-diverse pronouns during the tokenization process. This involves modifying the tokenizer to properly recognize and represent different pronoun forms, rather than treating them as unknown tokens.
The paper describes experiments evaluating this approach on benchmark datasets, demonstrating its ability to improve pronoun use fidelity and reduce misgendering errors compared to standard tokenization. The authors also discuss potential applications of this technique for named entity recognition in gender-diverse contexts.
Critical Analysis
The paper provides a thoughtful and technically sound approach to addressing an important issue in gender-inclusive natural language processing. The authors acknowledge the limitations of current tokenization methods and make a compelling case for the need for "pronoun tokenization parity" to better support gender diversity.
However, the paper does not delve into potential challenges around the implementation and scalability of this approach across different language models and domains. There are also open questions around how to handle novel or less common pronoun forms, and how to ensure the approach maintains high performance on other NLP tasks.
Additionally, the paper could have benefited from a more in-depth discussion of the societal implications of this work, and how it relates to broader efforts to promote inclusive and equitable language practices.
Conclusion
This paper presents a novel technique called "pronoun tokenization parity" to improve the ability of language models to accurately handle a diverse range of gender pronouns. By addressing issues of tokenization and misgendering, the authors aim to make language AI systems more inclusive and respectful of people's gender identities.
While the technical approach appears promising, the paper highlights the need for further research and consideration of the broader social and ethical implications of this work. Ultimately, efforts to build more gender-inclusive natural language processing have the potential to positively impact how people interact with and experience language technologies.
Related Papers
Transforming Dutch: Debiasing Dutch Coreference Resolution Systems for Non-binary Pronouns
Goya van Boven, Yupei Du, Dong Nguyen
0
0
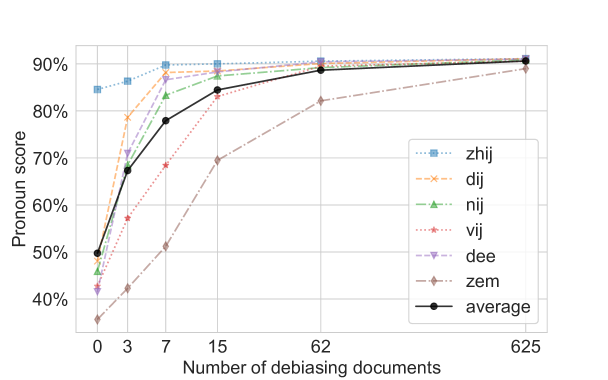
Gender-neutral pronouns are increasingly being introduced across Western languages. Recent evaluations have however demonstrated that English NLP systems are unable to correctly process gender-neutral pronouns, with the risk of erasing and misgendering non-binary individuals. This paper examines a Dutch coreference resolution system's performance on gender-neutral pronouns, specifically hen and die. In Dutch, these pronouns were only introduced in 2016, compared to the longstanding existence of singular they in English. We additionally compare two debiasing techniques for coreference resolution systems in non-binary contexts: Counterfactual Data Augmentation (CDA) and delexicalisation. Moreover, because pronoun performance can be hard to interpret from a general evaluation metric like LEA, we introduce an innovative evaluation metric, the pronoun score, which directly represents the portion of correctly processed pronouns. Our results reveal diminished performance on gender-neutral pronouns compared to gendered counterparts. Nevertheless, although delexicalisation fails to yield improvements, CDA substantially reduces the performance gap between gendered and gender-neutral pronouns. We further show that CDA remains effective in low-resource settings, in which a limited set of debiasing documents is used. This efficacy extends to previously unseen neopronouns, which are currently infrequently used but may gain popularity in the future, underscoring the viability of effective debiasing with minimal resources and low computational costs.
5/2/2024
⚙️
Toward a Theory of Tokenization in LLMs
Nived Rajaraman, Jiantao Jiao, Kannan Ramchandran
0
0
While there has been a large body of research attempting to circumvent tokenization for language modeling (Clark et al., 2022; Xue et al., 2022), the current consensus is that it is a necessary initial step for designing state-of-the-art performant language models. In this paper, we investigate tokenization from a theoretical point of view by studying the behavior of transformers on simple data generating processes. When trained on data drawn from certain simple $k^{text{th}}$-order Markov processes for $k > 1$, transformers exhibit a surprising phenomenon - in the absence of tokenization, they empirically fail to learn the right distribution and predict characters according to a unigram model (Makkuva et al., 2024). With the addition of tokenization, however, we empirically observe that transformers break through this barrier and are able to model the probabilities of sequences drawn from the source near-optimally, achieving small cross-entropy loss. With this observation as starting point, we study the end-to-end cross-entropy loss achieved by transformers with and without tokenization. With the appropriate tokenization, we show that even the simplest unigram models (over tokens) learnt by transformers are able to model the probability of sequences drawn from $k^{text{th}}$-order Markov sources near optimally. Our analysis provides a justification for the use of tokenization in practice through studying the behavior of transformers on Markovian data.
4/15/2024
Investigating Markers and Drivers of Gender Bias in Machine Translations
Peter J Barclay (Edinburgh Napier University), Ashkan Sami (Edinburgh Napier University)
0
0
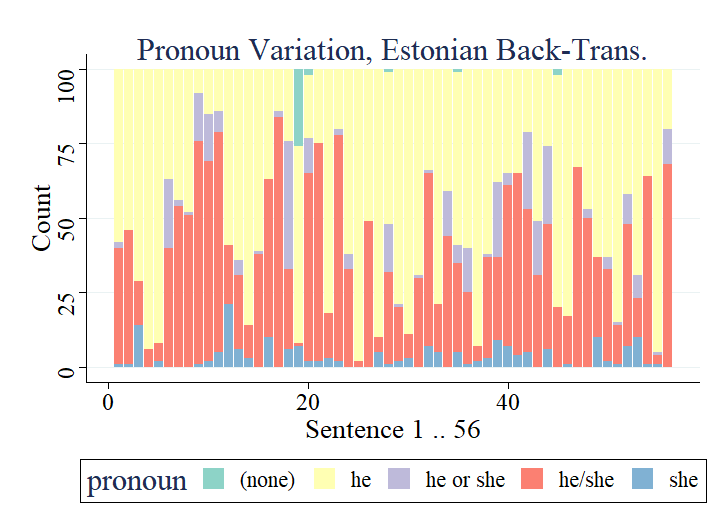
Implicit gender bias in Large Language Models (LLMs) is a well-documented problem, and implications of gender introduced into automatic translations can perpetuate real-world biases. However, some LLMs use heuristics or post-processing to mask such bias, making investigation difficult. Here, we examine bias in LLMss via back-translation, using the DeepL translation API to investigate the bias evinced when repeatedly translating a set of 56 Software Engineering tasks used in a previous study. Each statement starts with 'she', and is translated first into a 'genderless' intermediate language then back into English; we then examine pronoun-choice in the back-translated texts. We expand prior research in the following ways: (1) by comparing results across five intermediate languages, namely Finnish, Indonesian, Estonian, Turkish and Hungarian; (2) by proposing a novel metric for assessing the variation in gender implied in the repeated translations, avoiding the over-interpretation of individual pronouns, apparent in earlier work; (3) by investigating sentence features that drive bias; (4) and by comparing results from three time-lapsed datasets to establish the reproducibility of the approach. We found that some languages display similar patterns of pronoun use, falling into three loose groups, but that patterns vary between groups; this underlines the need to work with multiple languages. We also identify the main verb appearing in a sentence as a likely significant driver of implied gender in the translations. Moreover, we see a good level of replicability in the results, and establish that our variation metric proves robust despite an obvious change in the behaviour of the DeepL translation API during the course of the study. These results show that the back-translation method can provide further insights into bias in language models.
4/3/2024
📶
Can Perplexity Predict Fine-Tuning Performance? An Investigation of Tokenization Effects on Sequential Language Models for Nepali
Nishant Luitel, Nirajan Bekoju, Anand Kumar Sah, Subarna Shakya
0
0
Recent language models use subwording mechanisms to handle Out-of-Vocabulary(OOV) words seen during test time and, their generation capacity is generally measured using perplexity, an intrinsic metric. It is known that increasing the subword granularity results in a decrease of perplexity value. However, the study of how subwording affects the understanding capacity of language models has been very few and only limited to a handful of languages. To reduce this gap we used 6 different tokenization schemes to pretrain relatively small language models in Nepali and used the representations learned to finetune on several downstream tasks. Although byte-level BPE algorithm has been used in recent models like GPT, RoBERTa we show that on average they are sub-optimal in comparison to algorithms such as SentencePiece in finetuning performances for Nepali. Additionally, similar recent studies have focused on the Bert-based language model. We, however, pretrain and finetune sequential transformer-based language models.
4/30/2024