Rhythmic Foley: A Framework For Seamless Audio-Visual Alignment In Video-to-Audio Synthesis

0

Sign in to get full access
Overview
- Video-to-audio synthesis is the task of generating audio that matches the visual content in a video
- This paper presents "Rhythmic Foley," a framework for aligning audio and visual content in video-to-audio synthesis
- The approach leverages diffusion models to generate Foley sounds that are seamlessly synchronized with the video
Plain English Explanation
The paper introduces a new method called "Rhythmic Foley" that aims to create more seamless and natural-sounding audio for videos. Video-to-audio synthesis is the process of generating audio to match the visuals in a video, and this can be challenging to do well.
The key idea behind Rhythmic Foley is to use diffusion models to generate "Foley" sounds - sounds that mimic the actions happening on screen, like footsteps or object interactions. By carefully aligning these Foley sounds with the visual content, the method can produce audio that feels much more natural and synchronized compared to previous approaches.
The authors show that Rhythmic Foley outperforms other video-to-audio techniques in terms of the quality and alignment of the generated audio. This could have applications in areas like film, animation, and virtual reality, where seamless audio-visual integration is important for creating immersive experiences.
Technical Explanation
The Rhythmic Foley framework consists of two main components:
-
Foley Sound Generator: This module uses a diffusion model to generate appropriate Foley sounds based on the visual input. The diffusion model is trained to map from visual features to corresponding Foley sounds.
-
Audio-Visual Alignment: The generated Foley sounds are then aligned with the visual content using a hidden alignment model. This ensures that the sounds are synchronized with the on-screen actions in a natural and seamless way.
The key innovation of Rhythmic Foley is this tight coupling between Foley sound generation and audio-visual alignment. By considering both aspects jointly, the framework can produce high-quality, well-synchronized audio that enhances the viewer's experience.
Critical Analysis
The paper provides a comprehensive taxonomy of audio-visual synchronization techniques and situates Rhythmic Foley as an advancement over prior work. However, the authors acknowledge that their method still has some limitations:
- The Foley sound generation is limited to specific sound categories, and may not generalize to more diverse or complex audio effects.
- The audio-visual alignment assumes that Foley sounds are the only relevant audio, and does not consider incorporating or aligning with any existing audio in the video.
- Evaluating the perceptual quality and realism of the generated audio-visual content is challenging and subjective, and the paper could benefit from more extensive user studies.
Future work could explore ways to expand the Foley sound repertoire, incorporate existing audio, and develop more robust evaluation metrics to further improve the seamless integration of audio and visuals.
Conclusion
The Rhythmic Foley framework represents an important step forward in video-to-audio synthesis by focusing on the crucial aspect of aligning Foley sounds with visual content. By leveraging diffusion models and hidden alignment, the method can generate high-quality, synchronized audio that enhances the viewing experience.
While there are still some limitations to address, the core ideas behind Rhythmic Foley have the potential to benefit a wide range of applications, from film and animation to virtual reality and gaming, where seamless audio-visual integration is highly valued.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rhythmic Foley: A Framework For Seamless Audio-Visual Alignment In Video-to-Audio Synthesis
Zhiqi Huang, Dan Luo, Jun Wang, Huan Liao, Zhiheng Li, Zhiyong Wu
Our research introduces an innovative framework for video-to-audio synthesis, which solves the problems of audio-video desynchronization and semantic loss in the audio. By incorporating a semantic alignment adapter and a temporal synchronization adapter, our method significantly improves semantic integrity and the precision of beat point synchronization, particularly in fast-paced action sequences. Utilizing a contrastive audio-visual pre-trained encoder, our model is trained with video and high-quality audio data, improving the quality of the generated audio. This dual-adapter approach empowers users with enhanced control over audio semantics and beat effects, allowing the adjustment of the controller to achieve better results. Extensive experiments substantiate the effectiveness of our framework in achieving seamless audio-visual alignment.
Read more9/16/2024

0
FoleyCrafter: Bring Silent Videos to Life with Lifelike and Synchronized Sounds
Yiming Zhang, Yicheng Gu, Yanhong Zeng, Zhening Xing, Yuancheng Wang, Zhizheng Wu, Kai Chen
We study Neural Foley, the automatic generation of high-quality sound effects synchronizing with videos, enabling an immersive audio-visual experience. Despite its wide range of applications, existing approaches encounter limitations when it comes to simultaneously synthesizing high-quality and video-aligned (i.e.,, semantic relevant and temporal synchronized) sounds. To overcome these limitations, we propose FoleyCrafter, a novel framework that leverages a pre-trained text-to-audio model to ensure high-quality audio generation. FoleyCrafter comprises two key components: the semantic adapter for semantic alignment and the temporal controller for precise audio-video synchronization. The semantic adapter utilizes parallel cross-attention layers to condition audio generation on video features, producing realistic sound effects that are semantically relevant to the visual content. Meanwhile, the temporal controller incorporates an onset detector and a timestampbased adapter to achieve precise audio-video alignment. One notable advantage of FoleyCrafter is its compatibility with text prompts, enabling the use of text descriptions to achieve controllable and diverse video-to-audio generation according to user intents. We conduct extensive quantitative and qualitative experiments on standard benchmarks to verify the effectiveness of FoleyCrafter. Models and codes are available at https://github.com/open-mmlab/FoleyCrafter.
Read more7/2/2024
0
Video-Foley: Two-Stage Video-To-Sound Generation via Temporal Event Condition For Foley Sound
Junwon Lee, Jaekwon Im, Dabin Kim, Juhan Nam
Foley sound synthesis is crucial for multimedia production, enhancing user experience by synchronizing audio and video both temporally and semantically. Recent studies on automating this labor-intensive process through video-to-sound generation face significant challenges. Systems lacking explicit temporal features suffer from poor controllability and alignment, while timestamp-based models require costly and subjective human annotation. We propose Video-Foley, a video-to-sound system using Root Mean Square (RMS) as a temporal event condition with semantic timbre prompts (audio or text). RMS, a frame-level intensity envelope feature closely related to audio semantics, ensures high controllability and synchronization. The annotation-free self-supervised learning framework consists of two stages, Video2RMS and RMS2Sound, incorporating novel ideas including RMS discretization and RMS-ControlNet with a pretrained text-to-audio model. Our extensive evaluation shows that Video-Foley achieves state-of-the-art performance in audio-visual alignment and controllability for sound timing, intensity, timbre, and nuance. Code, model weights, and demonstrations are available on the accompanying website. (https://jnwnlee.github.io/video-foley-demo)
Read more8/23/2024
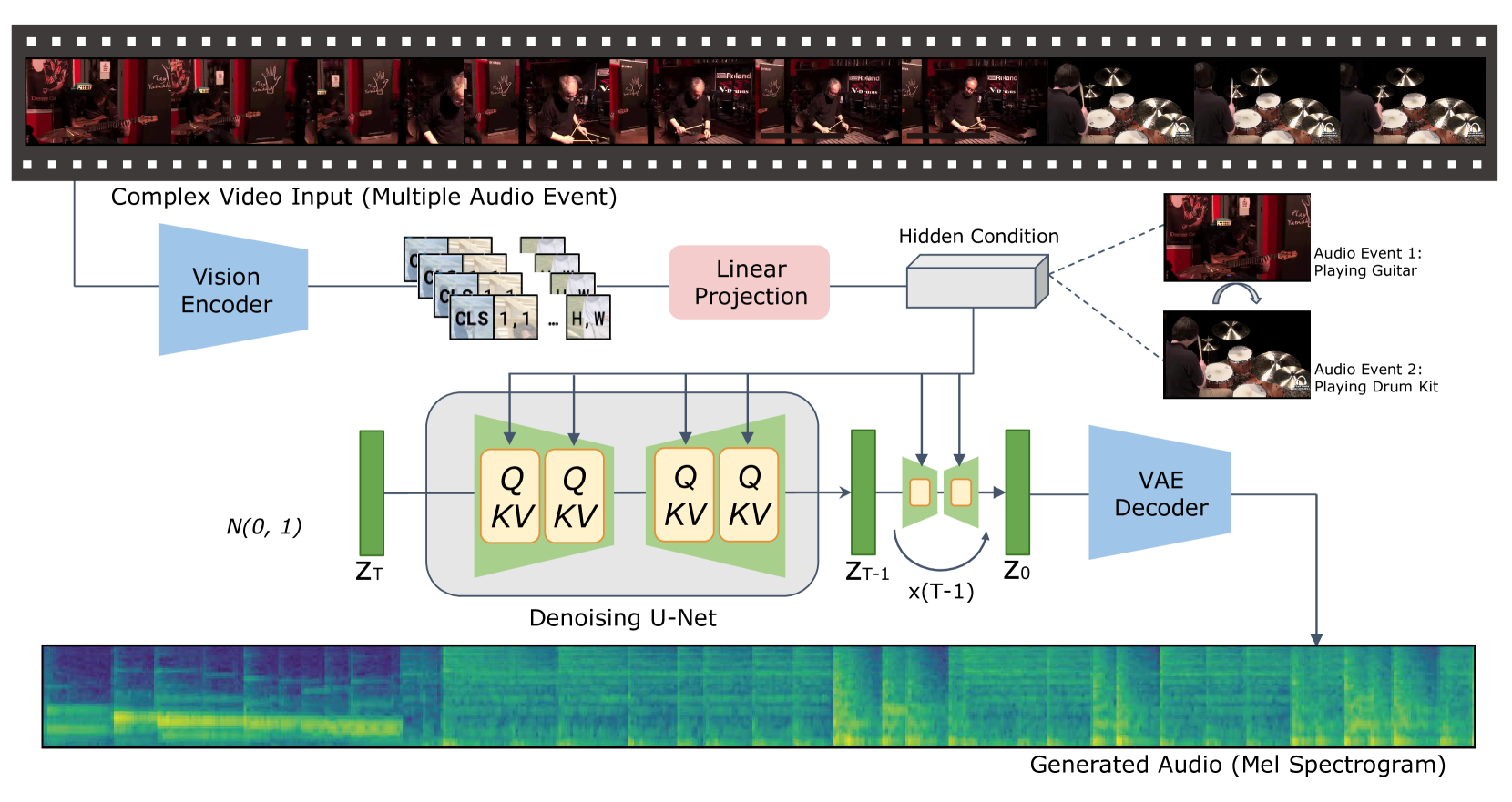
0
Video-to-Audio Generation with Hidden Alignment
Manjie Xu, Chenxing Li, Yong Ren, Rilin Chen, Yu Gu, Wei Liang, Dong Yu
Generating semantically and temporally aligned audio content in accordance with video input has become a focal point for researchers, particularly following the remarkable breakthrough in text-to-video generation. In this work, we aim to offer insights into the video-to-audio generation paradigm, focusing on three crucial aspects: vision encoders, auxiliary embeddings, and data augmentation techniques. Beginning with a foundational model VTA-LDM built on a simple yet surprisingly effective intuition, we explore various vision encoders and auxiliary embeddings through ablation studies. Employing a comprehensive evaluation pipeline that emphasizes generation quality and video-audio synchronization alignment, we demonstrate that our model exhibits state-of-the-art video-to-audio generation capabilities. Furthermore, we provide critical insights into the impact of different data augmentation methods on enhancing the generation framework's overall capacity. We showcase possibilities to advance the challenge of generating synchronized audio from semantic and temporal perspectives. We hope these insights will serve as a stepping stone toward developing more realistic and accurate audio-visual generation models.
Read more7/11/2024