RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation
2406.04339
0
0

Abstract
A fundamental objective in robot manipulation is to enable models to comprehend visual scenes and execute actions. Although existing robot Multimodal Large Language Models (MLLMs) can handle a range of basic tasks, they still face challenges in two areas: 1) inadequate reasoning ability to tackle complex tasks, and 2) high computational costs for MLLM fine-tuning and inference. The recently proposed state space model (SSM) known as Mamba demonstrates promising capabilities in non-trivial sequence modeling with linear inference complexity. Inspired by this, we introduce RoboMamba, an end-to-end robotic MLLM that leverages the Mamba model to deliver both robotic reasoning and action capabilities, while maintaining efficient fine-tuning and inference. Specifically, we first integrate the vision encoder with Mamba, aligning visual data with language embedding through co-training, empowering our model with visual common sense and robot-related reasoning. To further equip RoboMamba with action pose prediction abilities, we explore an efficient fine-tuning strategy with a simple policy head. We find that once RoboMamba possesses sufficient reasoning capability, it can acquire manipulation skills with minimal fine-tuning parameters (0.1% of the model) and time (20 minutes). In experiments, RoboMamba demonstrates outstanding reasoning capabilities on general and robotic evaluation benchmarks. Meanwhile, our model showcases impressive pose prediction results in both simulation and real-world experiments, achieving inference speeds 7 times faster than existing robot MLLMs. Our project web page: https://sites.google.com/view/robomamba-web
Create account to get full access
Overview
- This paper presents RoboMamba, a multimodal state space model for efficient robot reasoning and manipulation.
- The model combines visual, tactile, and proprioceptive inputs to build a comprehensive understanding of the robot's environment and state.
- The authors demonstrate how RoboMamba can improve the efficiency and accuracy of robot decision-making and control.
Plain English Explanation
The RoboMamba model is designed to help robots better understand their surroundings and make more informed decisions. Typical robots rely on a single type of sensor, like cameras or touch sensors, to perceive the world. RoboMamba, on the other hand, combines information from multiple sensors - including visual, tactile, and proprioceptive (related to the robot's own body position and movement) - to build a more complete picture of the robot's environment and its own state.
By integrating these diverse sensory inputs, RoboMamba can enable robots to reason about their surroundings and plan their actions more effectively. For example, a robot equipped with RoboMamba might be able to visually identify an object, use touch sensors to assess its weight and texture, and leverage proprioceptive data to understand how to best grasp and manipulate it. This comprehensive understanding can lead to more efficient and accurate robot decision-making and control.
Technical Explanation
The core of the RoboMamba model is a multimodal state space representation that fuses visual, tactile, and proprioceptive inputs. The authors provide a detailed explanation of the model architecture and training process, including the use of specialized neural network architectures to process the different sensor modalities and combine them into a unified state representation.
Through extensive experiments, the researchers demonstrate that RoboMamba outperforms traditional single-modality approaches in a variety of robot manipulation tasks. The model shows improved performance in terms of task success rate, efficiency, and generalization to novel scenarios. The authors attribute these gains to the model's ability to leverage complementary information from the different sensor inputs to build a more robust and informative representation of the robot's state.
Critical Analysis
The RoboMamba model represents a promising step forward in the field of multimodal robot perception and control. By combining diverse sensory inputs, the model can potentially overcome the limitations of single-modality approaches and enable more robust and intelligent robot behavior. However, the authors acknowledge that the current implementation has some limitations, such as the need for careful sensor calibration and the potential for increased computational complexity.
Additionally, while the experiments demonstrate the model's effectiveness in controlled laboratory settings, further research is needed to assess its performance in real-world, unstructured environments. Factors such as sensor noise, occlusion, and dynamic changes in the environment may pose significant challenges that the current model may not be fully equipped to handle.
Conclusion
The RoboMamba model presents an innovative approach to robot perception and decision-making by leveraging multimodal sensory inputs. The authors have demonstrated the potential of this approach to improve the efficiency and accuracy of robot manipulation tasks. As the field of robotics continues to advance, models like RoboMamba could play a crucial role in enabling robots to better understand and interact with the world around them, ultimately leading to more capable and versatile systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
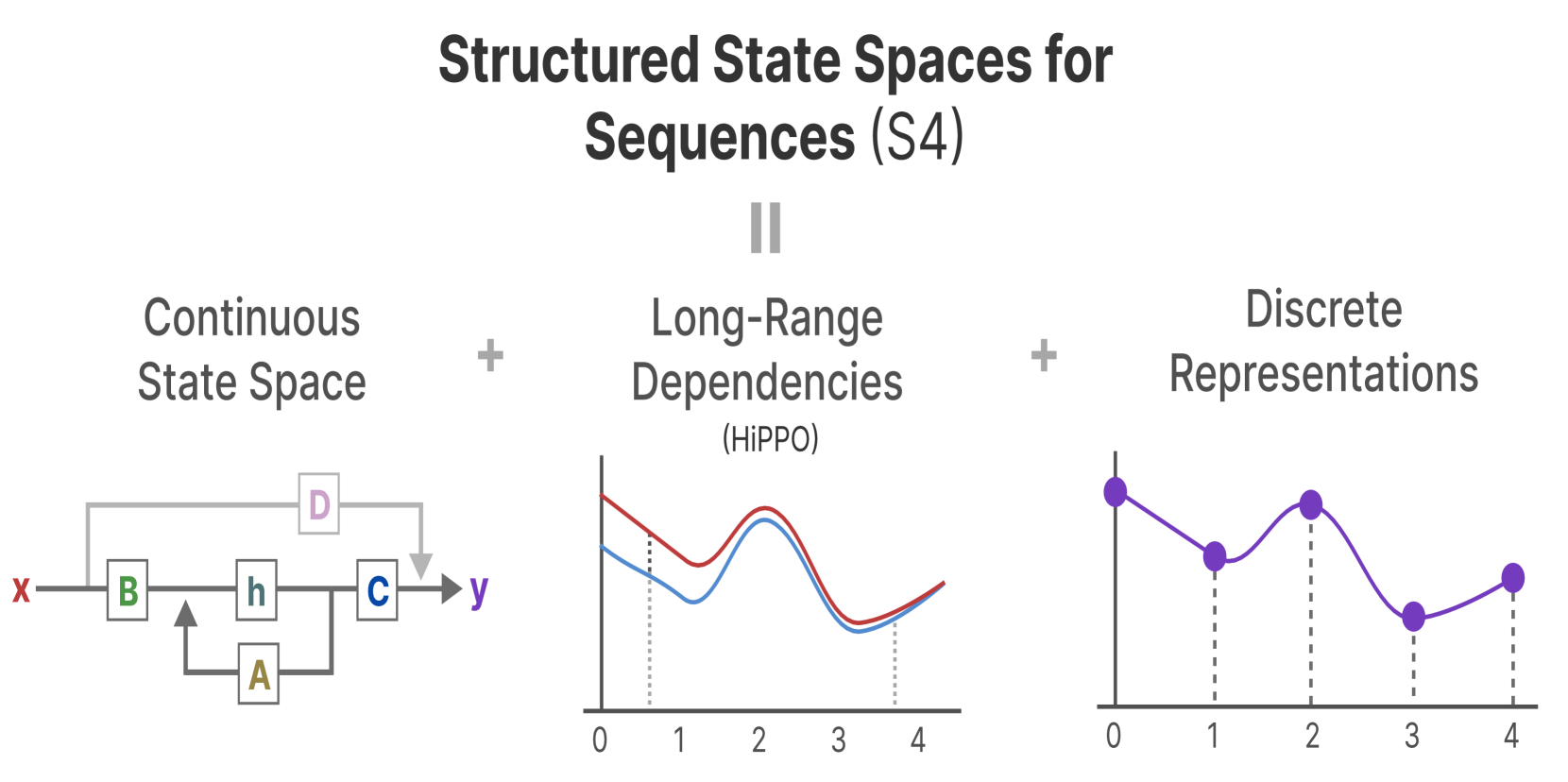
Vision Mamba: A Comprehensive Survey and Taxonomy
Xiao Liu, Chenxu Zhang, Lei Zhang
0
0
State Space Model (SSM) is a mathematical model used to describe and analyze the behavior of dynamic systems. This model has witnessed numerous applications in several fields, including control theory, signal processing, economics and machine learning. In the field of deep learning, state space models are used to process sequence data, such as time series analysis, natural language processing (NLP) and video understanding. By mapping sequence data to state space, long-term dependencies in the data can be better captured. In particular, modern SSMs have shown strong representational capabilities in NLP, especially in long sequence modeling, while maintaining linear time complexity. Notably, based on the latest state-space models, Mamba merges time-varying parameters into SSMs and formulates a hardware-aware algorithm for efficient training and inference. Given its impressive efficiency and strong long-range dependency modeling capability, Mamba is expected to become a new AI architecture that may outperform Transformer. Recently, a number of works have attempted to study the potential of Mamba in various fields, such as general vision, multi-modal, medical image analysis and remote sensing image analysis, by extending Mamba from natural language domain to visual domain. To fully understand Mamba in the visual domain, we conduct a comprehensive survey and present a taxonomy study. This survey focuses on Mamba's application to a variety of visual tasks and data types, and discusses its predecessors, recent advances and far-reaching impact on a wide range of domains. Since Mamba is now on an upward trend, please actively notice us if you have new findings, and new progress on Mamba will be included in this survey in a timely manner and updated on the Mamba project at https://github.com/lx6c78/Vision-Mamba-A-Comprehensive-Survey-and-Taxonomy.
5/8/2024
A Survey on Visual Mamba
Hanwei Zhang, Ying Zhu, Dan Wang, Lijun Zhang, Tianxiang Chen, Zi Ye
0
0
State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
4/29/2024

KalMamba: Towards Efficient Probabilistic State Space Models for RL under Uncertainty
Philipp Becker, Niklas Freymuth, Gerhard Neumann
0
0
Probabilistic State Space Models (SSMs) are essential for Reinforcement Learning (RL) from high-dimensional, partial information as they provide concise representations for control. Yet, they lack the computational efficiency of their recent deterministic counterparts such as S4 or Mamba. We propose KalMamba, an efficient architecture to learn representations for RL that combines the strengths of probabilistic SSMs with the scalability of deterministic SSMs. KalMamba leverages Mamba to learn the dynamics parameters of a linear Gaussian SSM in a latent space. Inference in this latent space amounts to standard Kalman filtering and smoothing. We realize these operations using parallel associative scanning, similar to Mamba, to obtain a principled, highly efficient, and scalable probabilistic SSM. Our experiments show that KalMamba competes with state-of-the-art SSM approaches in RL while significantly improving computational efficiency, especially on longer interaction sequences.
6/24/2024
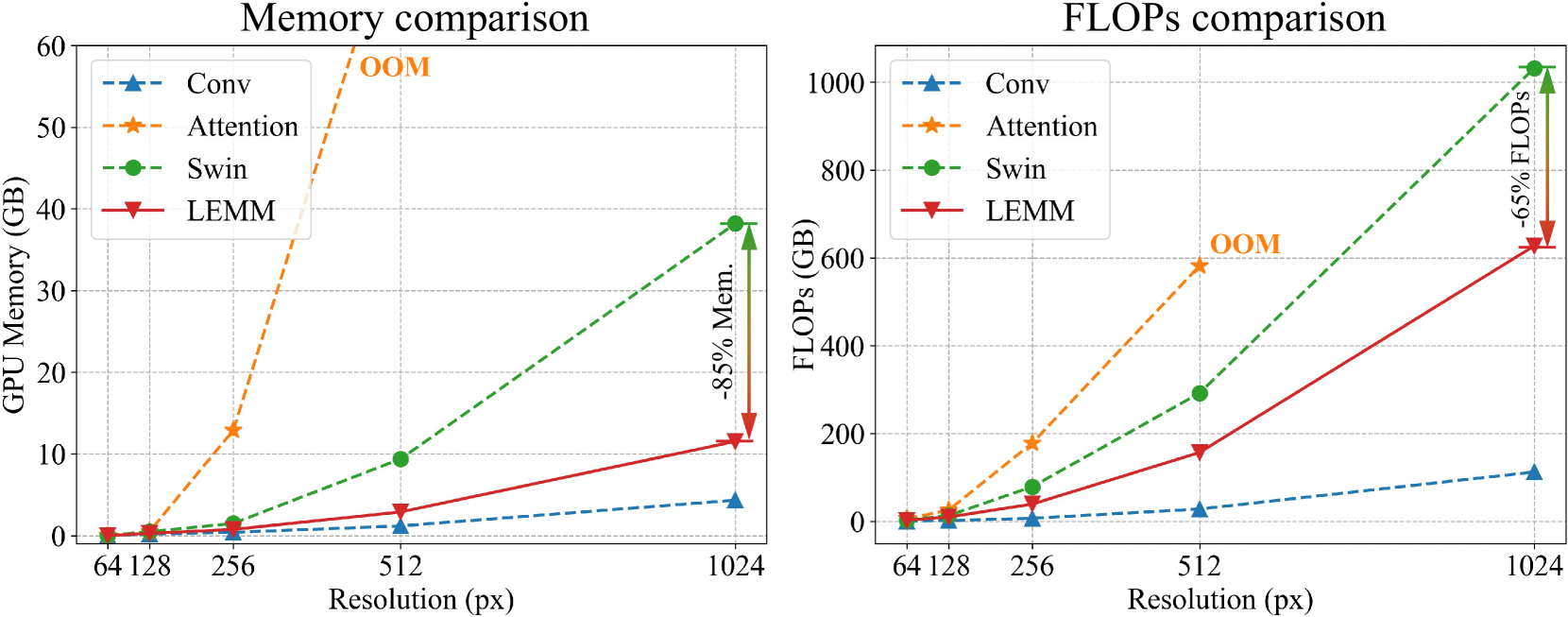
A Novel State Space Model with Local Enhancement and State Sharing for Image Fusion
Zihan Cao, Xiao Wu, Liang-Jian Deng, Yu Zhong
0
0
In image fusion tasks, images from different sources possess distinct characteristics. This has driven the development of numerous methods to explore better ways of fusing them while preserving their respective characteristics. Mamba, as a state space model, has emerged in the field of natural language processing. Recently, many studies have attempted to extend Mamba to vision tasks. However, due to the nature of images different from casual language sequences, the limited state capacity of Mamba weakens its ability to model image information. Additionally, the sequence modeling ability of Mamba is only capable of spatial information and cannot effectively capture the rich spectral information in images. Motivated by these challenges, we customize and improve the vision Mamba network designed for the image fusion task. Specifically, we propose the local-enhanced vision Mamba block, dubbed as LEVM. The LEVM block can improve local information perception of the network and simultaneously learn local and global spatial information. Furthermore, we propose the state sharing technique to enhance spatial details and integrate spatial and spectral information. Finally, the overall network is a multi-scale structure based on vision Mamba, called LE-Mamba. Extensive experiments show the proposed methods achieve state-of-the-art results on multispectral pansharpening and multispectral and hyperspectral image fusion datasets, and demonstrate the effectiveness of the proposed approach. Code will be made available.
4/16/2024