Robust Fully-Asynchronous Methods for Distributed Training over General Architecture

0
🏋️
Sign in to get full access
Overview
- Distributed machine learning problems often face challenges of latency, packet losses, and uneven computation speeds among devices.
- The authors propose a Robust Fully-Asynchronous Stochastic Gradient Tracking method (R-FAST) to address these issues.
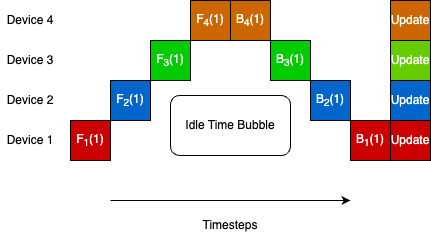
- R-FAST allows each device to perform local computation and communication at its own pace without any synchronization.
- The method uses a robust gradient tracking strategy and flexible communication architectures to overcome data heterogeneity and packet losses.
Plain English Explanation
The paper discusses the challenges of coordinating multiple devices in distributed machine learning. When devices are working together to train a model, they often run into problems like delays in communication, lost data packets, and uneven computation speeds. This can make it difficult to keep all the devices synchronized and working efficiently.
The authors propose a new method called R-FAST that allows each device to work independently without needing to be perfectly synchronized with the others. R-FAST uses a clever way of tracking the overall gradient, which helps it deal with differences in the data or computation speeds across devices. It also utilizes flexible communication networks that can handle lost packets.
The key idea is to let each device do its own computations and send updates whenever it's ready, rather than trying to force perfect coordination. This allows the system to keep running even when some devices are slower than others. The paper shows that R-FAST can run significantly faster than synchronous approaches while still achieving comparable accuracy, especially when dealing with uneven device performance.
Technical Explanation
The R-FAST method is designed to enable fully asynchronous communication and computation in distributed machine learning. Unlike synchronous approaches that require all devices to be aligned, R-FAST allows each device to perform local updates and send gradient information whenever it is ready.
The key innovation is a robust gradient tracking strategy that uses auxiliary variables to maintain an estimate of the overall gradient. This helps R-FAST overcome issues caused by data heterogeneity and packet losses across devices. The method also utilizes two flexible communication graph structures, only requiring that the graphs share at least one common root node.
Theoretically, the paper shows that R-FAST converges to a neighborhood of the optimal solution for smooth and strongly convex objectives, and to a stationary point for general non-convex problems. Empirically, the experiments demonstrate that R-FAST can run 1.5-2 times faster than synchronous baselines like Ring-AllReduce and D-PSGD, while achieving comparable accuracy. R-FAST also outperforms other asynchronous methods like AD-PSGD and OSGP, especially in the presence of stragglers.
Critical Analysis
The paper presents a compelling solution to the challenges of synchronization in distributed machine learning. By allowing fully asynchronous updates, R-FAST can handle issues like latency, packet losses, and uneven device performance that plague synchronous approaches.
However, the paper does not extensively explore the limitations of R-FAST. For example, it is unclear how the method would scale to very large numbers of devices or handle highly skewed data distributions across the network. The theoretical guarantees also assume certain smoothness and convexity properties that may not always hold in practice.
Additionally, the paper could have provided more insight into the design choices for the auxiliary gradient tracking variables and the communication graph structures. A deeper discussion of the tradeoffs involved in these design decisions would help readers better understand the strengths and weaknesses of the proposed approach.
Overall, the R-FAST method represents an important step forward in addressing the challenges of synchronization in distributed machine learning. But further research is needed to fully understand its capabilities and limitations across a wider range of real-world scenarios.
Conclusion
The R-FAST method proposed in this paper offers a promising solution to the challenge of synchronization in distributed machine learning. By allowing each device to perform computations and communications asynchronously, R-FAST can overcome issues like latency, packet losses, and uneven device performance that plague synchronous approaches.
The key innovations of R-FAST include a robust gradient tracking strategy and flexible communication architectures that can adapt to heterogeneous data and device capabilities. Empirically, the method has been shown to run significantly faster than synchronous baselines while still achieving comparable accuracy, particularly in the presence of stragglers.
While the paper presents a strong foundation, further research is needed to fully understand the limitations and scaling properties of R-FAST. Exploring its performance on larger, more diverse datasets and network configurations would help solidify its practical value. Additionally, deeper insights into the design choices underlying the method could lead to further improvements.
Overall, the R-FAST approach represents an important advancement in the field of distributed machine learning, paving the way for more efficient and robust training of large-scale models across heterogeneous device networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Robust Fully-Asynchronous Methods for Distributed Training over General Architecture
Zehan Zhu, Ye Tian, Yan Huang, Jinming Xu, Shibo He
Perfect synchronization in distributed machine learning problems is inefficient and even impossible due to the existence of latency, package losses and stragglers. We propose a Robust Fully-Asynchronous Stochastic Gradient Tracking method (R-FAST), where each device performs local computation and communication at its own pace without any form of synchronization. Different from existing asynchronous distributed algorithms, R-FAST can eliminate the impact of data heterogeneity across devices and allow for packet losses by employing a robust gradient tracking strategy that relies on properly designed auxiliary variables for tracking and buffering the overall gradient vector. More importantly, the proposed method utilizes two spanning-tree graphs for communication so long as both share at least one common root, enabling flexible designs in communication architectures. We show that R-FAST converges in expectation to a neighborhood of the optimum with a geometric rate for smooth and strongly convex objectives; and to a stationary point with a sublinear rate for general non-convex settings. Extensive experiments demonstrate that R-FAST runs 1.5-2 times faster than synchronous benchmark algorithms, such as Ring-AllReduce and D-PSGD, while still achieving comparable accuracy, and outperforms existing asynchronous SOTA algorithms, such as AD-PSGD and OSGP, especially in the presence of stragglers.
Read more7/30/2024
0
Ravnest: Decentralized Asynchronous Training on Heterogeneous Devices
Anirudh Rajiv Menon, Unnikrishnan Menon, Kailash Ahirwar
Modern deep learning models, growing larger and more complex, have demonstrated exceptional generalization and accuracy due to training on huge datasets. This trend is expected to continue. However, the increasing size of these models poses challenges in training, as traditional centralized methods are limited by memory constraints at such scales. This paper proposes an asynchronous decentralized training paradigm for large modern deep learning models that harnesses the compute power of regular heterogeneous PCs with limited resources connected across the internet to achieve favourable performance metrics. Ravnest facilitates decentralized training by efficiently organizing compute nodes into clusters with similar data transfer rates and compute capabilities, without necessitating that each node hosts the entire model. These clusters engage in $textit{Zero-Bubble Asynchronous Model Parallel}$ training, and a $textit{Parallel Multi-Ring All-Reduce}$ method is employed to effectively execute global parameter averaging across all clusters. We have framed our asynchronous SGD loss function as a block structured optimization problem with delayed updates and derived an optimal convergence rate of $Oleft(frac{1}{sqrt{K}}right)$. We further discuss linear speedup with respect to the number of participating clusters and the bound on the staleness parameter.
Read more5/24/2024

0
Straggler-Resilient Decentralized Learning via Adaptive Asynchronous Updates
Guojun Xiong, Gang Yan, Shiqiang Wang, Jian Li
With the increasing demand for large-scale training of machine learning models, fully decentralized optimization methods have recently been advocated as alternatives to the popular parameter server framework. In this paradigm, each worker maintains a local estimate of the optimal parameter vector, and iteratively updates it by waiting and averaging all estimates obtained from its neighbors, and then corrects it on the basis of its local dataset. However, the synchronization phase is sensitive to stragglers. An efficient way to mitigate this effect is to consider asynchronous updates, where each worker computes stochastic gradients and communicates with other workers at its own pace. Unfortunately, fully asynchronous updates suffer from staleness of stragglers' parameters. To address these limitations, we propose a fully decentralized algorithm DSGD-AAU with adaptive asynchronous updates via adaptively determining the number of neighbor workers for each worker to communicate with. We show that DSGD-AAU achieves a linear speedup for convergence and demonstrate its effectiveness via extensive experiments.
Read more7/10/2024

0
Asynchronous Federated Stochastic Optimization with Exact Averaging for Heterogeneous Local Objectives
Charikleia Iakovidou, Kibaek Kim
Federated learning (FL) was recently proposed to securely train models with data held over multiple locations (clients) under the coordination of a central server. Two major challenges hindering the performance of FL algorithms are long training times caused by straggling clients, and a decline in model accuracy under non-iid local data distributions (client drift). In this work, we propose and analyze Asynchronous Exact Averaging (AREA), a new stochastic (sub)gradient algorithm that utilizes asynchronous communication to speed up convergence and enhance scalability, and employs client memory to correct the client drift caused by variations in client update frequencies. Moreover, AREA is, to the best of our knowledge, the first method that is guaranteed to converge under arbitrarily long delays, without the use of delay-adaptive stepsizes, and (i) for strongly convex, smooth functions, asymptotically converges to an error neighborhood whose size depends only on the variance of the stochastic gradients used with respect to the number of iterations, and (ii) for convex, non-smooth functions, matches the convergence rate of the centralized stochastic subgradient method up to a constant factor, which depends on the average of the individual client update frequencies instead of their minimum (or maximum). Our numerical results validate our theoretical analysis and indicate AREA outperforms state-of-the-art methods when local data are highly non-iid, especially as the number of clients grows.
Read more5/30/2024