Robust Online Learning over Networks
2309.00520
0
0
🔗
Abstract
The recent deployment of multi-agent networks has enabled the distributed solution of learning problems, where agents cooperate to train a global model without sharing their local, private data. This work specifically targets some prevalent challenges inherent to distributed learning: (i) online training, i.e., the local data change over time; (ii) asynchronous agent computations; (iii) unreliable and limited communications; and (iv) inexact local computations. To tackle these challenges, we apply the Distributed Operator Theoretical (DOT) version of the Alternating Direction Method of Multipliers (ADMM), which we call DOT-ADMM. We prove that if the DOT-ADMM operator is metric subregular, then it converges with a linear rate for a large class of (not necessarily strongly) convex learning problems toward a bounded neighborhood of the optimal time-varying solution, and characterize how such neighborhood depends on (i)-(iv). We first derive an easy-to-verify condition for ensuring the metric subregularity of an operator, followed by tutorial examples on linear and logistic regression problems. We corroborate the theoretical analysis with numerical simulations comparing DOT-ADMM with other state-of-the-art algorithms, showing that only the proposed algorithm exhibits robustness to (i)-(iv).
Create account to get full access
Overview
- This paper addresses key challenges in distributed learning, where multiple agents cooperate to train a shared model without sharing their private data.
- The authors apply the Distributed Operator Theoretical (DOT) version of the Alternating Direction Method of Multipliers (ADMM), called DOT-ADMM, to tackle issues like online training, asynchronous computations, unreliable communications, and inexact local computations.
- The paper proves that DOT-ADMM converges linearly to a bounded neighborhood of the optimal time-varying solution, and characterizes how this neighborhood depends on the challenges mentioned.
- The authors provide an easy-to-verify condition for ensuring the metric subregularity of the DOT-ADMM operator, and demonstrate the approach on linear and logistic regression problems.
- Numerical simulations show that DOT-ADMM outperforms other state-of-the-art algorithms in terms of robustness to the addressed challenges.
Plain English Explanation
In modern machine learning, there is a growing trend towards distributed event-based learning via ADMM and general continuous-time formulation of stochastic ADMM, where multiple agents or devices collaborate to train a shared model without directly sharing their private data. This is known as "distributed learning."
However, distributed learning faces several challenges, such as:
- The local data available to each agent may change over time (online training).
- The agents may perform computations at different speeds (asynchronous computations).
- The communication between agents may be unreliable or limited.
- The local computations performed by each agent may not be exact.
To address these issues, the researchers in this paper applied a specific version of the Alternating Direction Method of Multipliers (ADMM) called the Distributed Operator Theoretical (DOT) ADMM, or DOT-ADMM for short. This approach enables the agents to cooperate and train a shared model while being robust to the challenges mentioned above.
The key idea is that the DOT-ADMM algorithm has a special property called "metric subregularity," which allows it to converge linearly to a bounded region around the optimal solution, even in the presence of the challenges faced by distributed learning. The paper provides an easy-to-check condition for ensuring this metric subregularity, making it more accessible to practitioners.
The authors demonstrate the effectiveness of DOT-ADMM through examples on linear and logistic regression problems, and show that it outperforms other state-of-the-art distributed learning algorithms in terms of robustness to the challenges mentioned.
Technical Explanation
The paper presents the Distributed Operator Theoretical (DOT) version of the Alternating Direction Method of Multipliers (ADMM), called DOT-ADMM, as a solution to the prevalent challenges in distributed learning, such as online training, asynchronous agent computations, unreliable and limited communications, and inexact local computations.
The key idea is to leverage the metric subregularity of the DOT-ADMM operator, which allows the algorithm to converge linearly to a bounded neighborhood of the optimal time-varying solution, despite the presence of the aforementioned challenges. The authors provide an easy-to-verify condition for ensuring the metric subregularity of the DOT-ADMM operator, and demonstrate the approach on linear and logistic regression problems.
Through numerical simulations, the authors show that DOT-ADMM outperforms other state-of-the-art distributed learning algorithms, such as DIMAT: Decentralized Iterative Merging for Training Deep Learning and Estimation and Network Design Framework for Efficient Distributed Optimization, in terms of robustness to the addressed challenges.
Critical Analysis
The paper presents a robust and theoretically sound approach to distributed learning, addressing several practical challenges that arise in real-world scenarios. The authors provide a strong mathematical foundation for the DOT-ADMM algorithm and its convergence properties, which is a significant contribution to the field.
However, the paper does not delve into the specific implementation details or computational complexity of the DOT-ADMM algorithm, which would be useful for practitioners looking to apply the method in their own projects. Additionally, the paper could have explored the impact of the choice of hyperparameters on the algorithm's performance, as well as the scalability of the approach to larger networks or more complex learning tasks.
Furthermore, the paper does not discuss the potential privacy and security implications of the distributed learning setup, which is an important consideration for real-world deployments. Addressing these concerns would strengthen the practical relevance of the research.
Overall, the paper presents a valuable contribution to the field of distributed learning, but additional practical insights and considerations would further enhance its impact and usefulness for the research community and industry practitioners.
Conclusion
This paper introduces the Distributed Operator Theoretical (DOT) version of the Alternating Direction Method of Multipliers (ADMM), called DOT-ADMM, as a robust solution to the key challenges in distributed learning. The authors prove that DOT-ADMM converges linearly to a bounded neighborhood of the optimal time-varying solution, even in the presence of online training, asynchronous computations, unreliable communications, and inexact local computations.
The paper's theoretical analysis and numerical simulations demonstrate the superiority of DOT-ADMM over other state-of-the-art distributed learning algorithms, making it a promising approach for practical applications that require distributed learning with minimal data sharing. The easy-to-verify condition for ensuring the metric subregularity of the DOT-ADMM operator further enhances the accessibility and usability of the method for the research community and industry practitioners.
While the paper provides a strong technical foundation, future work could explore implementation details, hyperparameter sensitivity, scalability, and privacy/security considerations to further strengthen the practical impact of this distributed learning approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Distributed Event-Based Learning via ADMM
Guner Dilsad Er, Sebastian Trimpe, Michael Muehlebach
0
0
We consider a distributed learning problem, where agents minimize a global objective function by exchanging information over a network. Our approach has two distinct features: (i) It substantially reduces communication by triggering communication only when necessary, and (ii) it is agnostic to the data-distribution among the different agents. We can therefore guarantee convergence even if the local data-distributions of the agents are arbitrarily distinct. We analyze the convergence rate of the algorithm and derive accelerated convergence rates in a convex setting. We also characterize the effect of communication drops and demonstrate that our algorithm is robust to communication failures. The article concludes by presenting numerical results from a distributed LASSO problem, and distributed learning tasks on MNIST and CIFAR-10 datasets. The experiments underline communication savings of 50% or more due to the event-based communication strategy, show resilience towards heterogeneous data-distributions, and highlight that our approach outperforms common baselines such as FedAvg, FedProx, and FedADMM.
5/20/2024
🔍
A GPU-Accelerated Bi-linear ADMM Algorithm for Distributed Sparse Machine Learning
Alireza Olama, Andreas Lundell, Jan Kronqvist, Elham Ahmadi, Eduardo Camponogara
0
0
This paper introduces the Bi-linear consensus Alternating Direction Method of Multipliers (Bi-cADMM), aimed at solving large-scale regularized Sparse Machine Learning (SML) problems defined over a network of computational nodes. Mathematically, these are stated as minimization problems with convex local loss functions over a global decision vector, subject to an explicit $ell_0$ norm constraint to enforce the desired sparsity. The considered SML problem generalizes different sparse regression and classification models, such as sparse linear and logistic regression, sparse softmax regression, and sparse support vector machines. Bi-cADMM leverages a bi-linear consensus reformulation of the original non-convex SML problem and a hierarchical decomposition strategy that divides the problem into smaller sub-problems amenable to parallel computing. In Bi-cADMM, this decomposition strategy is based on a two-phase approach. Initially, it performs a sample decomposition of the data and distributes local datasets across computational nodes. Subsequently, a delayed feature decomposition of the data is conducted on Graphics Processing Units (GPUs) available to each node. This methodology allows Bi-cADMM to undertake computationally intensive data-centric computations on GPUs, while CPUs handle more cost-effective computations. The proposed algorithm is implemented within an open-source Python package called Parallel Sparse Fitting Toolbox (PsFiT), which is publicly available. Finally, computational experiments demonstrate the efficiency and scalability of our algorithm through numerical benchmarks across various SML problems featuring distributed datasets.
6/27/2024
A General Continuous-Time Formulation of Stochastic ADMM and Its Variants
Chris Junchi Li
0
0
Stochastic versions of the alternating direction method of multiplier (ADMM) and its variants play a key role in many modern large-scale machine learning problems. In this work, we introduce a unified algorithmic framework called generalized stochastic ADMM and investigate their continuous-time analysis. The generalized framework widely includes many stochastic ADMM variants such as standard, linearized and gradient-based ADMM. Our continuous-time analysis provides us with new insights into stochastic ADMM and variants, and we rigorously prove that under some proper scaling, the trajectory of stochastic ADMM weakly converges to the solution of a stochastic differential equation with small noise. Our analysis also provides a theoretical explanation of why the relaxation parameter should be chosen between 0 and 2.
4/23/2024
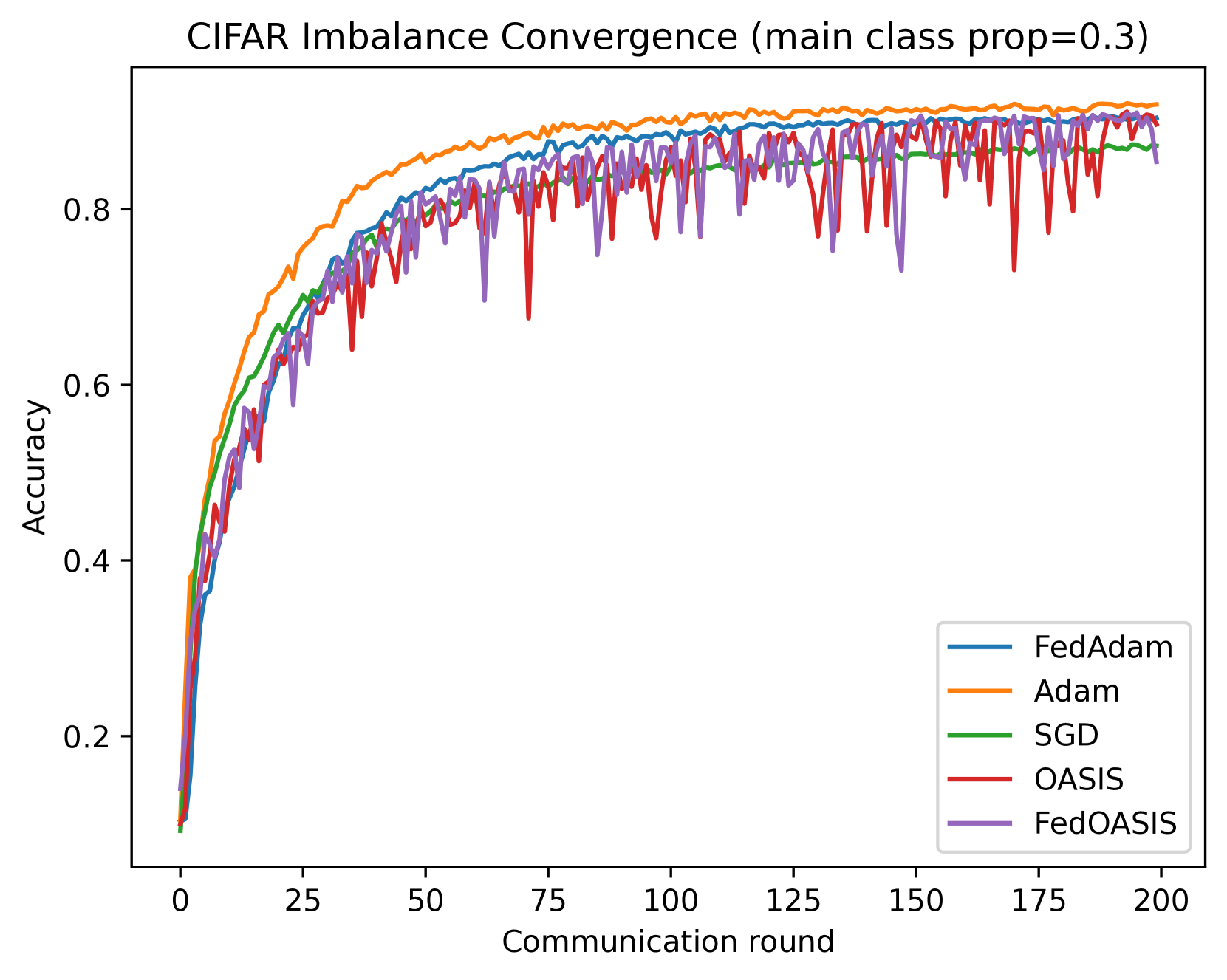
Local Methods with Adaptivity via Scaling
Savelii Chezhegov, Sergey Skorik, Nikolas Khachaturov, Danil Shalagin, Aram Avetisyan, Aleksandr Beznosikov, Martin Tak'av{c}, Yaroslav Kholodov, Alexander Gasnikov
0
0
The rapid development of machine learning and deep learning has introduced increasingly complex optimization challenges that must be addressed. Indeed, training modern, advanced models has become difficult to implement without leveraging multiple computing nodes in a distributed environment. Distributed optimization is also fundamental to emerging fields such as federated learning. Specifically, there is a need to organize the training process to minimize the time lost due to communication. A widely used and extensively researched technique to mitigate the communication bottleneck involves performing local training before communication. This approach is the focus of our paper. Concurrently, adaptive methods that incorporate scaling, notably led by Adam, have gained significant popularity in recent years. Therefore, this paper aims to merge the local training technique with the adaptive approach to develop efficient distributed learning methods. We consider the classical Local SGD method and enhance it with a scaling feature. A crucial aspect is that the scaling is described generically, allowing us to analyze various approaches, including Adam, RMSProp, and OASIS, in a unified manner. In addition to theoretical analysis, we validate the performance of our methods in practice by training a neural network.
6/14/2024