Local Methods with Adaptivity via Scaling
2406.00846
0
0
Abstract
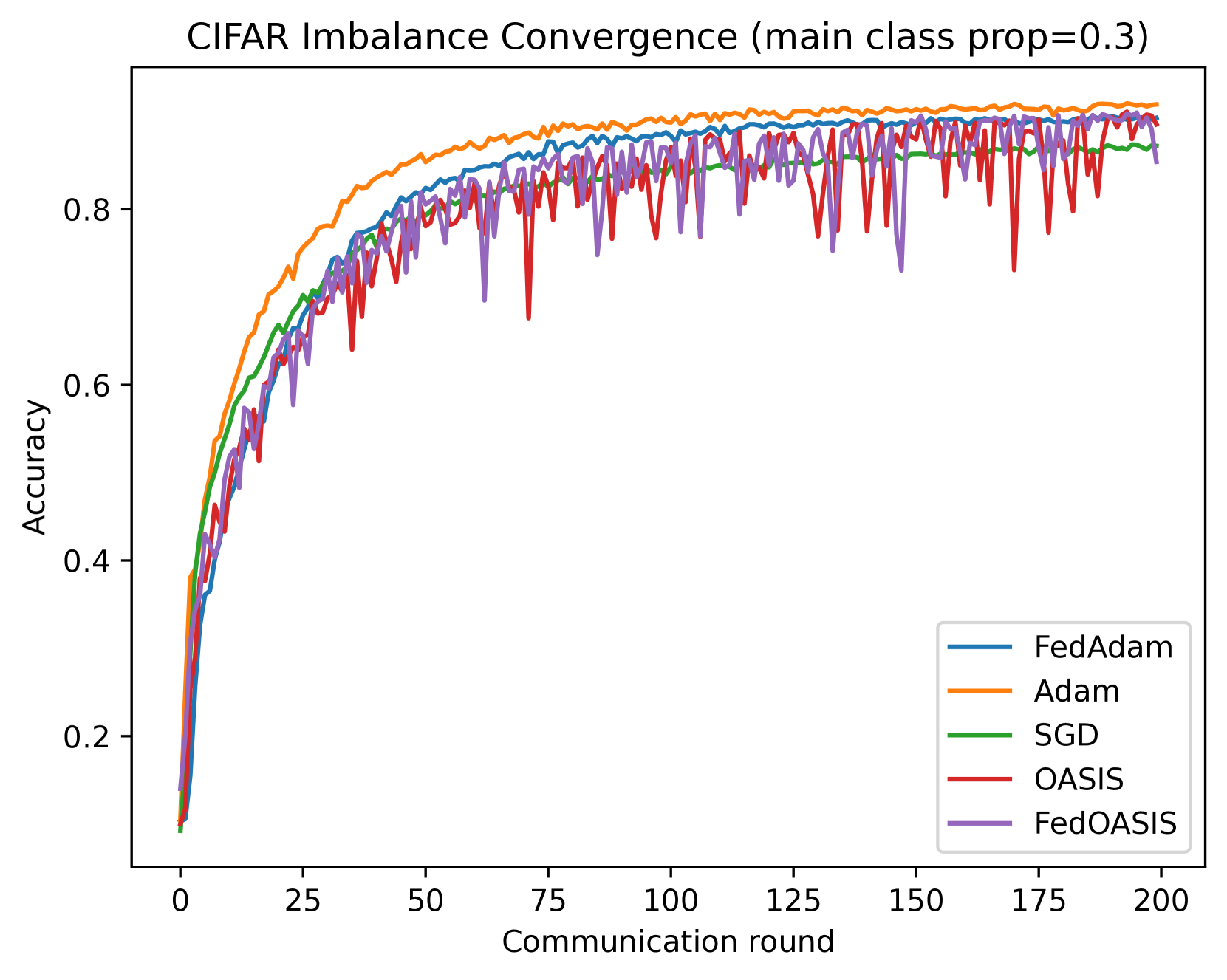
The rapid development of machine learning and deep learning has introduced increasingly complex optimization challenges that must be addressed. Indeed, training modern, advanced models has become difficult to implement without leveraging multiple computing nodes in a distributed environment. Distributed optimization is also fundamental to emerging fields such as federated learning. Specifically, there is a need to organize the training process to minimize the time lost due to communication. A widely used and extensively researched technique to mitigate the communication bottleneck involves performing local training before communication. This approach is the focus of our paper. Concurrently, adaptive methods that incorporate scaling, notably led by Adam, have gained significant popularity in recent years. Therefore, this paper aims to merge the local training technique with the adaptive approach to develop efficient distributed learning methods. We consider the classical Local SGD method and enhance it with a scaling feature. A crucial aspect is that the scaling is described generically, allowing us to analyze various approaches, including Adam, RMSProp, and OASIS, in a unified manner. In addition to theoretical analysis, we validate the performance of our methods in practice by training a neural network.
Create account to get full access
Overview
- Distributed optimization is a key challenge in machine learning, where multiple devices or agents need to collaborate to train a shared model.
- Communication between devices can be a bottleneck, limiting the efficiency and scalability of distributed learning.
- This paper proposes a new method called "Local Methods with Adaptivity via Scaling" (LMAS) that aims to address these challenges.
Plain English Explanation
LMAS is a technique for distributed machine learning that tries to reduce the amount of communication required between devices. In typical distributed learning, devices need to constantly send updates back and forth to a central server or coordinator. This communication can slow down the training process, especially as the number of devices increases.
LMAS tackles this by having each device run its own local optimization process, scaling the updates based on the local data and model. This allows devices to make progress on their own, without needing to constantly communicate with a central server. When they do share updates, the scaling helps ensure the updates are relevant and helpful for the overall model.
The key idea is to strike a balance between local autonomy and global coordination. Devices run independently, but periodically share scaled updates that can be effectively integrated. This reduces the communication burden while still allowing the model to converge to a good solution.
Technical Explanation
The LMAS algorithm works as follows:
- Each device maintains its own local model and performs optimization steps on its local data.
- After some number of local steps, the device computes a scaled update to its local model.
- This scaled update is then shared with a central coordinator or server.
- The coordinator aggregates the scaled updates from all devices and updates the global model accordingly.
- The updated global model is then shared back with the devices, which use it to initialize their local models for the next round of optimization.
The key innovation is the scaling step, where devices adapt the magnitude of their updates based on properties of their local data and model. This helps ensure the updates are relevant and impactful, rather than simply sending raw gradients.
The authors show theoretically and empirically that this approach can achieve faster convergence and better final model quality compared to standard distributed optimization methods, especially in heterogeneous settings where devices have varying data distributions or computational capabilities.
Critical Analysis
The LMAS method represents an interesting step forward in addressing the communication bottleneck in distributed machine learning. By empowering devices to perform more local optimization and selectively sharing relevant updates, it can reduce the overall communication required.
However, the paper does not address some potential drawbacks or limitations of this approach. For example, the scaling mechanism relies on heuristics that may not generalize well to all problem settings. There are also open questions about how to handle non-i.i.d. data distributions and ensure fairness across devices with varying resources.
Additionally, the theoretical analysis makes some simplifying assumptions, such as convex objectives and Lipschitz-continuous gradients, that may not hold in more realistic deep learning scenarios. Further empirical validation on larger-scale, heterogeneous problems would be helpful to better understand the practical benefits and limitations of LMAS.
Overall, the LMAS method is a promising direction, but there is still room for refinement and further research to address some of the remaining challenges in distributed optimization and decentralized training of machine learning models.
Conclusion
The "Local Methods with Adaptivity via Scaling" (LMAS) approach proposed in this paper offers a novel way to address the communication challenges in distributed machine learning. By empowering devices to perform more local optimization and selectively share relevant updates, LMAS can reduce the overall communication burden while still allowing for effective global model convergence.
While the method shows promise, there are still some open questions and limitations that warrant further research. Nonetheless, the core idea of balancing local autonomy and global coordination is an important contribution that could inform the development of more scalable and efficient distributed learning algorithms.
As the field of machine learning continues to push the boundaries of what is possible with larger and more complex models, techniques like LMAS will become increasingly crucial for enabling collaborative training at scale, across heterogeneous devices and data sources. This work represents an important step in that direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Communication-Efficient Adaptive Batch Size Strategies for Distributed Local Gradient Methods
Tim Tsz-Kit Lau, Weijian Li, Chenwei Xu, Han Liu, Mladen Kolar
0
0
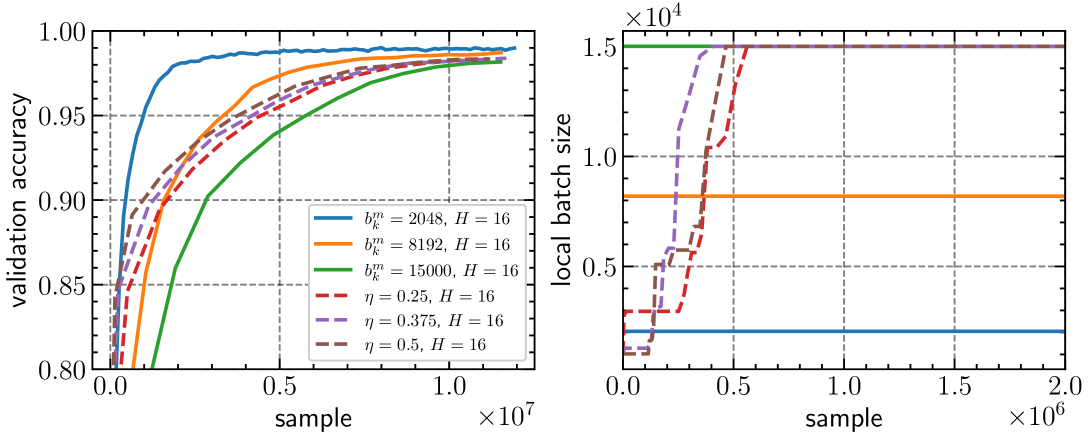
Modern deep neural networks often require distributed training with many workers due to their large size. As worker numbers increase, communication overheads become the main bottleneck in data-parallel minibatch stochastic gradient methods with per-iteration gradient synchronization. Local gradient methods like Local SGD reduce communication by only syncing after several local steps. Despite understanding their convergence in i.i.d. and heterogeneous settings and knowing the importance of batch sizes for efficiency and generalization, optimal local batch sizes are difficult to determine. We introduce adaptive batch size strategies for local gradient methods that increase batch sizes adaptively to reduce minibatch gradient variance. We provide convergence guarantees under homogeneous data conditions and support our claims with image classification experiments, demonstrating the effectiveness of our strategies in training and generalization.
6/21/2024
📈
Navigating Scaling Laws: Compute Optimality in Adaptive Model Training
Sotiris Anagnostidis, Gregor Bachmann, Imanol Schlag, Thomas Hofmann
0
0
In recent years, the state-of-the-art in deep learning has been dominated by very large models that have been pre-trained on vast amounts of data. The paradigm is very simple: investing more computational resources (optimally) leads to better performance, and even predictably so; neural scaling laws have been derived that accurately forecast the performance of a network for a desired level of compute. This leads to the notion of a `compute-optimal' model, i.e. a model that allocates a given level of compute during training optimally to maximize performance. In this work, we extend the concept of optimality by allowing for an `adaptive' model, i.e. a model that can change its shape during training. By doing so, we can design adaptive models that optimally traverse between the underlying scaling laws and outpace their `static' counterparts, leading to a significant reduction in the required compute to reach a given target performance. We show that our approach generalizes across modalities and different shape parameters.
5/24/2024
Ravnest: Decentralized Asynchronous Training on Heterogeneous Devices
Anirudh Rajiv Menon, Unnikrishnan Menon, Kailash Ahirwar
0
0
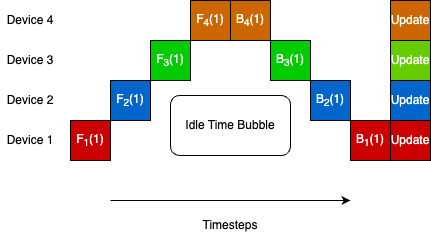
Modern deep learning models, growing larger and more complex, have demonstrated exceptional generalization and accuracy due to training on huge datasets. This trend is expected to continue. However, the increasing size of these models poses challenges in training, as traditional centralized methods are limited by memory constraints at such scales. This paper proposes an asynchronous decentralized training paradigm for large modern deep learning models that harnesses the compute power of regular heterogeneous PCs with limited resources connected across the internet to achieve favourable performance metrics. Ravnest facilitates decentralized training by efficiently organizing compute nodes into clusters with similar data transfer rates and compute capabilities, without necessitating that each node hosts the entire model. These clusters engage in $textit{Zero-Bubble Asynchronous Model Parallel}$ training, and a $textit{Parallel Multi-Ring All-Reduce}$ method is employed to effectively execute global parameter averaging across all clusters. We have framed our asynchronous SGD loss function as a block structured optimization problem with delayed updates and derived an optimal convergence rate of $Oleft(frac{1}{sqrt{K}}right)$. We further discuss linear speedup with respect to the number of participating clusters and the bound on the staleness parameter.
5/24/2024

The Limits and Potentials of Local SGD for Distributed Heterogeneous Learning with Intermittent Communication
Kumar Kshitij Patel, Margalit Glasgow, Ali Zindari, Lingxiao Wang, Sebastian U. Stich, Ziheng Cheng, Nirmit Joshi, Nathan Srebro
0
0
Local SGD is a popular optimization method in distributed learning, often outperforming other algorithms in practice, including mini-batch SGD. Despite this success, theoretically proving the dominance of local SGD in settings with reasonable data heterogeneity has been difficult, creating a significant gap between theory and practice. In this paper, we provide new lower bounds for local SGD under existing first-order data heterogeneity assumptions, showing that these assumptions are insufficient to prove the effectiveness of local update steps. Furthermore, under these same assumptions, we demonstrate the min-max optimality of accelerated mini-batch SGD, which fully resolves our understanding of distributed optimization for several problem classes. Our results emphasize the need for better models of data heterogeneity to understand the effectiveness of local SGD in practice. Towards this end, we consider higher-order smoothness and heterogeneity assumptions, providing new upper bounds that imply the dominance of local SGD over mini-batch SGD when data heterogeneity is low.
5/21/2024