Robust Semi-supervised Multimodal Medical Image Segmentation via Cross Modality Collaboration

0

Sign in to get full access
Overview
- Presents a robust semi-supervised multimodal medical image segmentation approach via cross-modality collaboration.
- Leverages a shared representation learning framework to effectively learn from limited labeled data and abundant unlabeled data.
- Demonstrates superior performance over state-of-the-art methods on various medical image segmentation tasks.
Plain English Explanation
Medical imaging techniques like MRI and CT scans are crucial for diagnosis and treatment planning. However, accurately segmenting (separating) different anatomical structures in these images can be challenging, especially when labeled training data is scarce.
This research paper introduces a new approach to multimodal medical image segmentation - the process of identifying and separating different tissues or organs in images from multiple imaging modalities (e.g., MRI and CT). The key innovations are:
-
Shared Representation Learning: The model learns a shared feature representation that can effectively leverage information from both labeled and unlabeled data across different imaging modalities. This allows the model to learn more robust and generalizable features, even when labeled data is limited.
-
Cross-Modality Collaboration: The model explicitly encourages collaboration between modalities, allowing them to learn from each other and improve overall segmentation performance. This is particularly helpful when one modality has stronger performance than another on certain anatomical structures.
By combining these techniques, the researchers demonstrate that their approach can outperform state-of-the-art methods for medical image segmentation tasks, even with limited labeled data. This could have important implications for clinical applications, where labeled data can be scarce and time-consuming to obtain.
Technical Explanation
The proposed framework, called RSMS-Net, consists of a shared encoder network and multiple modality-specific decoders. The shared encoder learns a common feature representation that captures salient information across modalities, while the modality-specific decoders focus on extracting modality-relevant features for segmentation.
To effectively leverage both labeled and unlabeled data, RSMS-Net employs a semi-supervised learning strategy with three key components:
-
Supervised Segmentation Loss: The model is trained to minimize the segmentation error on the limited labeled data using standard supervised learning techniques.
-
Consistency Regularization: The model is encouraged to produce consistent segmentation outputs for the same anatomical structures across different modalities, even for unlabeled data. This helps the shared encoder learn a more robust and generalizable feature representation.
-
Cross-Modality Collaboration: The model explicitly learns to leverage the complementary strengths of different modalities by encouraging the modality-specific decoders to collaborate and learn from each other's predictions.
The researchers evaluate RSMS-Net on several medical image segmentation tasks, including brain, cardiac, and prostate segmentation, and demonstrate its superiority over state-of-the-art semi-supervised and multimodal segmentation methods.
Critical Analysis
The paper presents a well-designed and promising approach to addressing the challenge of limited labeled data in multimodal medical image segmentation. The authors have thoughtfully incorporated several key components, such as shared representation learning and cross-modality collaboration, to effectively leverage the information contained in both labeled and unlabeled data.
One potential limitation is the reliance on the assumption that different modalities provide complementary information about the target anatomical structures. In some cases, this may not always be true, and the cross-modality collaboration may not yield significant benefits. Additionally, the paper does not discuss the computational complexity or training time of the proposed RSMS-Net model, which could be an important consideration for real-world clinical applications.
Further research could explore ways to dynamically assess the level of complementarity between modalities and adjust the cross-modality collaboration accordingly. Investigating the model's robustness to noise or variations in data quality across modalities would also be valuable.
Conclusion
This research paper presents a novel semi-supervised multimodal medical image segmentation approach that effectively leverages both labeled and unlabeled data through shared representation learning and cross-modality collaboration. The demonstrated performance improvements over state-of-the-art methods suggest that this approach could have significant practical implications for clinical applications, where labeled data is often scarce. The proposed framework represents an important step forward in addressing the challenges of limited data in medical image analysis and could inspire further advancements in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Robust Semi-supervised Multimodal Medical Image Segmentation via Cross Modality Collaboration
Xiaogen Zhou, Yiyou Sun, Min Deng, Winnie Chiu Wing Chu, Qi Dou
Multimodal learning leverages complementary information derived from different modalities, thereby enhancing performance in medical image segmentation. However, prevailing multimodal learning methods heavily rely on extensive well-annotated data from various modalities to achieve accurate segmentation performance. This dependence often poses a challenge in clinical settings due to limited availability of such data. Moreover, the inherent anatomical misalignment between different imaging modalities further complicates the endeavor to enhance segmentation performance. To address this problem, we propose a novel semi-supervised multimodal segmentation framework that is robust to scarce labeled data and misaligned modalities. Our framework employs a novel cross modality collaboration strategy to distill modality-independent knowledge, which is inherently associated with each modality, and integrates this information into a unified fusion layer for feature amalgamation. With a channel-wise semantic consistency loss, our framework ensures alignment of modality-independent information from a feature-wise perspective across modalities, thereby fortifying it against misalignments in multimodal scenarios. Furthermore, our framework effectively integrates contrastive consistent learning to regulate anatomical structures, facilitating anatomical-wise prediction alignment on unlabeled data in semi-supervised segmentation tasks. Our method achieves competitive performance compared to other multimodal methods across three tasks: cardiac, abdominal multi-organ, and thyroid-associated orbitopathy segmentations. It also demonstrates outstanding robustness in scenarios involving scarce labeled data and misaligned modalities.
Read more9/5/2024

0
Complementary Information Mutual Learning for Multimodality Medical Image Segmentation
Chuyun Shen, Wenhao Li, Haoqing Chen, Xiaoling Wang, Fengping Zhu, Yuxin Li, Xiangfeng Wang, Bo Jin
Radiologists must utilize multiple modal images for tumor segmentation and diagnosis due to the limitations of medical imaging and the diversity of tumor signals. This leads to the development of multimodal learning in segmentation. However, the redundancy among modalities creates challenges for existing subtraction-based joint learning methods, such as misjudging the importance of modalities, ignoring specific modal information, and increasing cognitive load. These thorny issues ultimately decrease segmentation accuracy and increase the risk of overfitting. This paper presents the complementary information mutual learning (CIML) framework, which can mathematically model and address the negative impact of inter-modal redundant information. CIML adopts the idea of addition and removes inter-modal redundant information through inductive bias-driven task decomposition and message passing-based redundancy filtering. CIML first decomposes the multimodal segmentation task into multiple subtasks based on expert prior knowledge, minimizing the information dependence between modalities. Furthermore, CIML introduces a scheme in which each modality can extract information from other modalities additively through message passing. To achieve non-redundancy of extracted information, the redundant filtering is transformed into complementary information learning inspired by the variational information bottleneck. The complementary information learning procedure can be efficiently solved by variational inference and cross-modal spatial attention. Numerical results from the verification task and standard benchmarks indicate that CIML efficiently removes redundant information between modalities, outperforming SOTA methods regarding validation accuracy and segmentation effect.
Read more7/11/2024
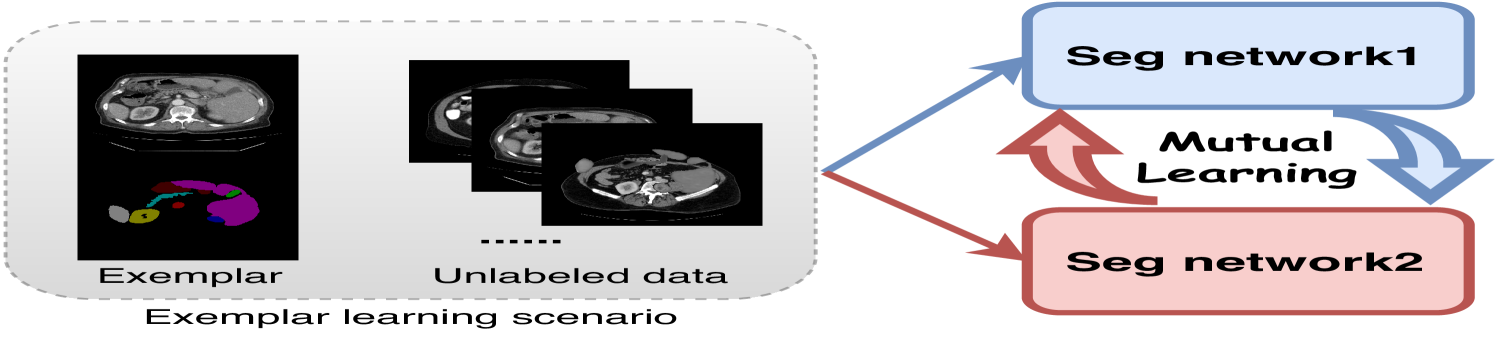
0
Cross-model Mutual Learning for Exemplar-based Medical Image Segmentation
Qing En, Yuhong Guo
Medical image segmentation typically demands extensive dense annotations for model training, which is both time-consuming and skill-intensive. To mitigate this burden, exemplar-based medical image segmentation methods have been introduced to achieve effective training with only one annotated image. In this paper, we introduce a novel Cross-model Mutual learning framework for Exemplar-based Medical image Segmentation (CMEMS), which leverages two models to mutually excavate implicit information from unlabeled data at multiple granularities. CMEMS can eliminate confirmation bias and enable collaborative training to learn complementary information by enforcing consistency at different granularities across models. Concretely, cross-model image perturbation based mutual learning is devised by using weakly perturbed images to generate high-confidence pseudo-labels, supervising predictions of strongly perturbed images across models. This approach enables joint pursuit of prediction consistency at the image granularity. Moreover, cross-model multi-level feature perturbation based mutual learning is designed by letting pseudo-labels supervise predictions from perturbed multi-level features with different resolutions, which can broaden the perturbation space and enhance the robustness of our framework. CMEMS is jointly trained using exemplar data, synthetic data, and unlabeled data in an end-to-end manner. Experimental results on two medical image datasets indicate that the proposed CMEMS outperforms the state-of-the-art segmentation methods with extremely limited supervision.
Read more4/19/2024

0
Multimodal Information Interaction for Medical Image Segmentation
Xinxin Fan, Lin Liu, Haoran Zhang
The use of multimodal data in assisted diagnosis and segmentation has emerged as a prominent area of interest in current research. However, one of the primary challenges is how to effectively fuse multimodal features. Most of the current approaches focus on the integration of multimodal features while ignoring the correlation and consistency between different modal features, leading to the inclusion of potentially irrelevant information. To address this issue, we introduce an innovative Multimodal Information Cross Transformer (MicFormer), which employs a dual-stream architecture to simultaneously extract features from each modality. Leveraging the Cross Transformer, it queries features from one modality and retrieves corresponding responses from another, facilitating effective communication between bimodal features. Additionally, we incorporate a deformable Transformer architecture to expand the search space. We conducted experiments on the MM-WHS dataset, and in the CT-MRI multimodal image segmentation task, we successfully improved the whole-heart segmentation DICE score to 85.57 and MIoU to 75.51. Compared to other multimodal segmentation techniques, our method outperforms by margins of 2.83 and 4.23, respectively. This demonstrates the efficacy of MicFormer in integrating relevant information between different modalities in multimodal tasks. These findings hold significant implications for multimodal image tasks, and we believe that MicFormer possesses extensive potential for broader applications across various domains. Access to our method is available at https://github.com/fxxJuses/MICFormer
Read more4/26/2024