Run LoRA Run: Faster and Lighter LoRA Implementations
2312.03415
0
0
🔍
Abstract
LoRA is a technique that reduces the number of trainable parameters in a neural network by introducing low-rank adapters to linear layers. This technique is used both for fine-tuning and full training of large language models. This paper presents the RunLoRA framework for efficient implementations of LoRA that significantly improves the speed of neural network training and fine-tuning using low-rank adapters. The proposed implementation optimizes the computation of LoRA operations based on dimensions of corresponding linear layer, layer input dimensions and lora rank by choosing best forward and backward computation graph based on FLOPs and time estimations, resulting in faster training without sacrificing accuracy. The experimental results show up to 28% speedup on language modeling networks.
Create account to get full access
Overview
- This paper introduces faster and more lightweight implementations of Low-Rank Adaptation (LoRA), a technique used to efficiently fine-tune large language models.
- The authors propose two new LoRA methods - Batched LoRA and Orthonormal LoRA - that aim to improve the performance and efficiency of LoRA compared to the original approach.
- The paper includes numerical experiments that demonstrate the benefits of the proposed methods in terms of training time, model size, and performance on various tasks.
Plain English Explanation
LoRA is a technique that allows you to fine-tune large language models like GPT-3 or BERT without having to update all the model's parameters. Instead, LoRA only updates a small number of parameters, which makes the process faster and requires less storage space.
The authors of this paper wanted to make LoRA even faster and more efficient. They developed two new versions of LoRA:
-
Batched LoRA: This method processes the input in small batches, which can speed up the training process.
-
Orthonormal LoRA: This method uses a special type of matrix that is more efficient to compute and store, leading to faster training and smaller model size.
The paper shows that these new LoRA methods outperform the original LoRA approach in terms of training time, model size, and performance on various language tasks. For example, Batched LoRA can be up to 2.7 times faster than standard LoRA, while Orthonormal LoRA can reduce the model size by up to 40%.
These improvements make LoRA even more useful for fine-tuning large language models, especially in scenarios where computational resources or storage space are limited, such as on mobile devices or in low-power environments.
Technical Explanation
The paper introduces two new LoRA methods to improve upon the original LoRA approach:
-
Batched LoRA: This method processes the input in small batches, rather than processing the entire input at once. By breaking the input into smaller chunks, the authors can leverage the parallelism of modern hardware to speed up the training process. The authors show that Batched LoRA can be up to 2.7 times faster than standard LoRA.
-
Orthonormal LoRA: This method uses a special type of matrix called an orthonormal matrix to represent the LoRA parameters. Orthonormal matrices have the property that their inverse is equal to their transpose, which makes them more efficient to compute and store. The authors demonstrate that Orthonormal LoRA can reduce the model size by up to 40% compared to standard LoRA, while maintaining similar performance.
The paper includes numerical experiments that evaluate the performance of Batched LoRA and Orthonormal LoRA on various language tasks, such as text classification and question answering. The results show that the proposed methods outperform the original LoRA approach in terms of training time, model size, and task performance.
Critical Analysis
The paper provides a valuable contribution to the field of efficient fine-tuning of large language models. The authors' focus on improving the speed and memory footprint of LoRA is well-justified, as these are important practical considerations for deploying language models in real-world applications.
However, the paper does not address some potential limitations of the proposed methods. For example, the authors do not discuss how Batched LoRA and Orthonormal LoRA might perform on more diverse or challenging tasks, or how they might scale to larger language models. Additionally, the paper does not provide a detailed analysis of the trade-offs between the different LoRA variants, such as the potential for accuracy degradation in exchange for faster training or smaller model size.
Further research could explore the robustness and generalizability of the proposed methods, as well as investigate potential synergies between Batched LoRA and Orthonormal LoRA, or between these methods and other efficient fine-tuning techniques like OLORA or S-LoRA.
Conclusion
This paper introduces two new LoRA methods - Batched LoRA and Orthonormal LoRA - that significantly improve the efficiency of the original LoRA approach. The authors demonstrate that these methods can reduce training time by up to 2.7 times and model size by up to 40%, while maintaining similar performance on various language tasks.
These improvements to LoRA make it an even more attractive choice for fine-tuning large language models, especially in resource-constrained environments. The proposed methods could have important practical implications for deploying powerful language models on edge devices, mobile applications, or other scenarios where computational resources and storage space are limited.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
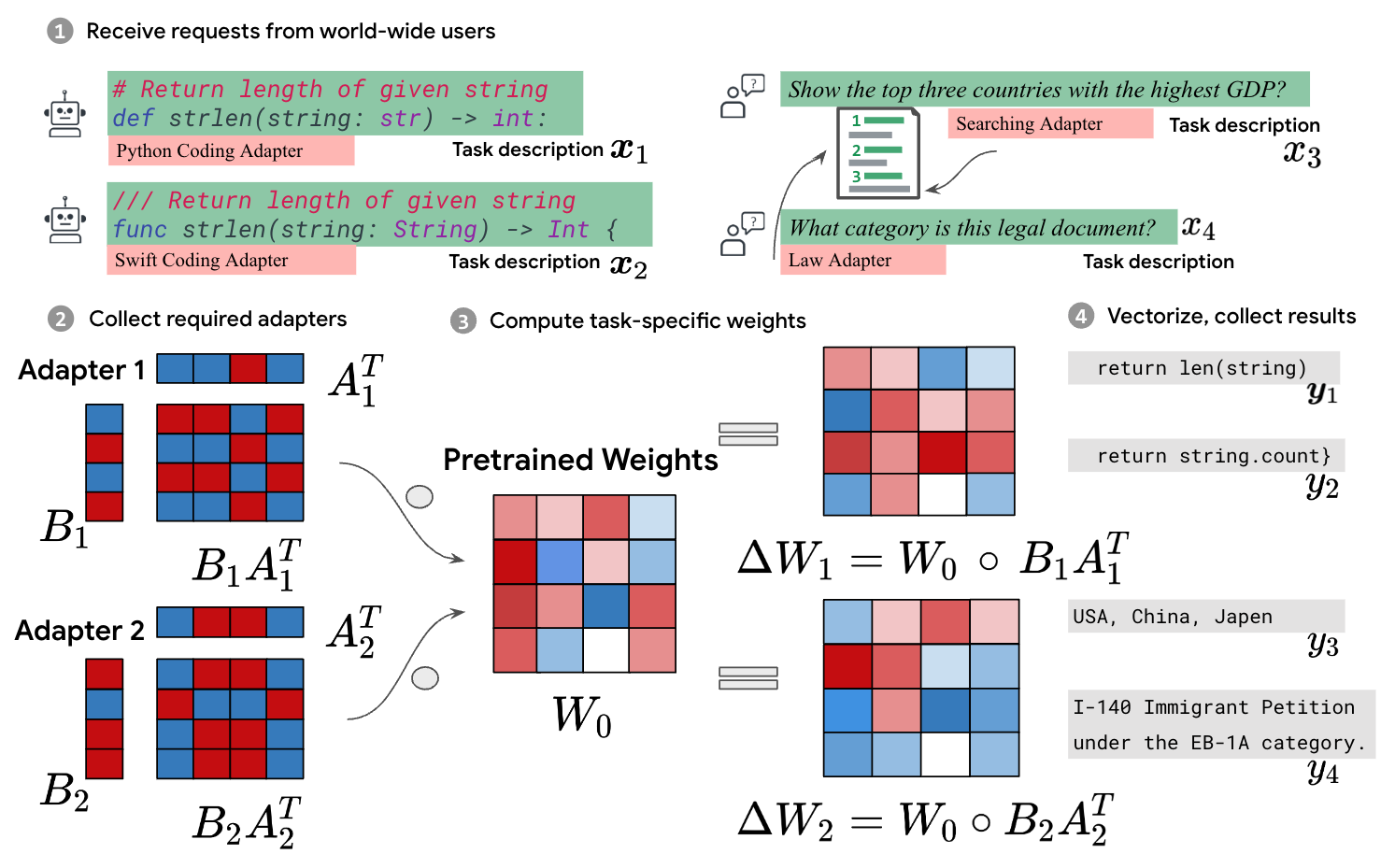
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
0
0
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
4/29/2024

OLoRA: Orthonormal Low-Rank Adaptation of Large Language Models
Kerim Buyukakyuz
0
0
The advent of large language models (LLMs) has revolutionized natural language processing, enabling unprecedented capabilities in understanding and generating human-like text. However, the computational cost and convergence times associated with fine-tuning these models remain significant challenges. Low-Rank Adaptation (LoRA) has emerged as a promising method to mitigate these issues by introducing efficient fine-tuning techniques with a reduced number of trainable parameters. In this paper, we present OLoRA, an enhancement to the LoRA method that leverages orthonormal matrix initialization through QR decomposition. OLoRA significantly accelerates the convergence of LLM training while preserving the efficiency benefits of LoRA, such as the number of trainable parameters and GPU memory footprint. Our empirical evaluations demonstrate that OLoRA not only converges faster but also exhibits improved performance compared to standard LoRA across a variety of language modeling tasks. This advancement opens new avenues for more efficient and accessible fine-tuning of LLMs, potentially enabling broader adoption and innovation in natural language applications.
6/5/2024
⚙️
A Note on LoRA
Vlad Fomenko, Han Yu, Jongho Lee, Stanley Hsieh, Weizhu Chen
0
0
LoRA (Low-Rank Adaptation) has emerged as a preferred method for efficiently adapting Large Language Models (LLMs) with remarkable simplicity and efficacy. This note extends the original LoRA paper by offering new perspectives that were not initially discussed and presents a series of insights for deploying LoRA at scale. Without introducing new experiments, we aim to improve the understanding and application of LoRA.
4/9/2024
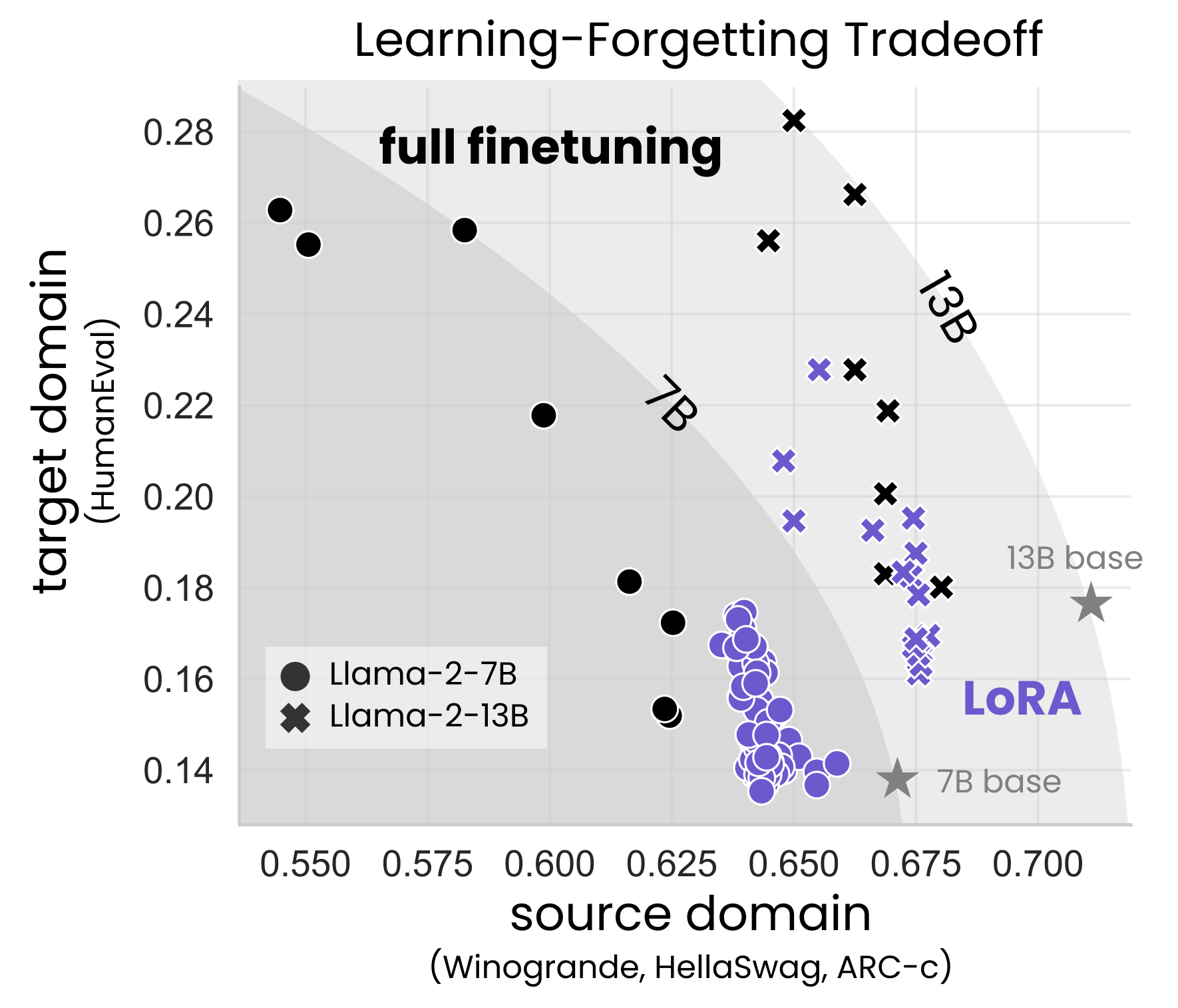
LoRA Learns Less and Forgets Less
Dan Biderman, Jose Gonzalez Ortiz, Jacob Portes, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, John P. Cunningham
0
0
Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning ($approx$100K prompt-response pairs) and continued pretraining ($approx$10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model's performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations. We show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
5/17/2024