S-LoRA: Serving Thousands of Concurrent LoRA Adapters
2311.03285
41
2
📶
Abstract
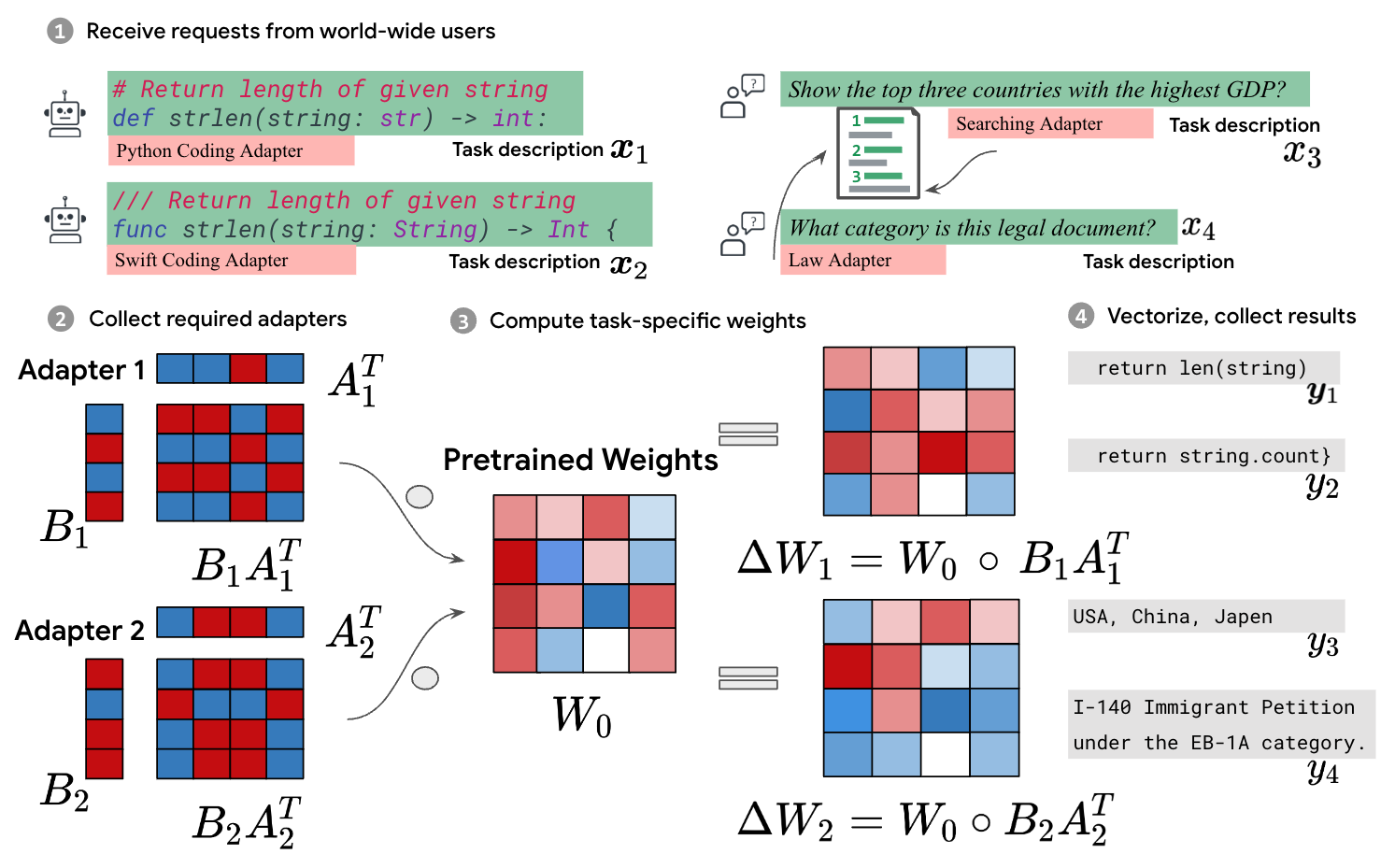
The pretrain-then-finetune paradigm is commonly adopted in the deployment of large language models. Low-Rank Adaptation (LoRA), a parameter-efficient fine-tuning method, is often employed to adapt a base model to a multitude of tasks, resulting in a substantial collection of LoRA adapters derived from one base model. We observe that this paradigm presents significant opportunities for batched inference during serving. To capitalize on these opportunities, we present S-LoRA, a system designed for the scalable serving of many LoRA adapters. S-LoRA stores all adapters in the main memory and fetches the adapters used by the currently running queries to the GPU memory. To efficiently use the GPU memory and reduce fragmentation, S-LoRA proposes Unified Paging. Unified Paging uses a unified memory pool to manage dynamic adapter weights with different ranks and KV cache tensors with varying sequence lengths. Additionally, S-LoRA employs a novel tensor parallelism strategy and highly optimized custom CUDA kernels for heterogeneous batching of LoRA computation. Collectively, these features enable S-LoRA to serve thousands of LoRA adapters on a single GPU or across multiple GPUs with a small overhead. Compared to state-of-the-art libraries such as HuggingFace PEFT and vLLM (with naive support of LoRA serving), S-LoRA can improve the throughput by up to 4 times and increase the number of served adapters by several orders of magnitude. As a result, S-LoRA enables scalable serving of many task-specific fine-tuned models and offers the potential for large-scale customized fine-tuning services. The code is available at https://github.com/S-LoRA/S-LoRA
Create account to get full access
Overview
- The paper discusses a system called S-LoRA, which is designed for the scalable serving of many Low-Rank Adaptation (LoRA) adapters.
- LoRA is a parameter-efficient fine-tuning method that is commonly used to adapt large language models to a variety of tasks, resulting in a collection of LoRA adapters.
- The paper explores the opportunities for batched inference during the serving of these LoRA adapters and presents S-LoRA as a solution to enable scalable serving.
Plain English Explanation
Low-Rank Adaptation (LoRA) is a technique used to fine-tune large language models for specific tasks. This process results in a collection of "LoRA adapters" - small, task-specific modifications to the base model. The researchers observed that this collection of LoRA adapters presents opportunities for more efficient serving, as the adapters can be batched together during inference.
To capitalize on these opportunities, the researchers developed a system called S-LoRA. S-LoRA stores all the LoRA adapters in the main memory and fetches the ones needed for the current queries onto the GPU memory. To use the GPU memory efficiently and reduce fragmentation, S-LoRA introduces a technique called "Unified Paging," which manages the dynamic adapter weights and other tensors in a unified memory pool.
Additionally, S-LoRA employs a novel tensor parallelism strategy and custom CUDA kernels to optimize the computation of the LoRA adapters. These features allow S-LoRA to serve thousands of LoRA adapters on a single GPU or across multiple GPUs with minimal overhead.
Compared to existing libraries, S-LoRA can improve throughput by up to 4 times and significantly increase the number of adapters that can be served. This enables scalable serving of many task-specific fine-tuned models and opens the door for large-scale customized fine-tuning services.
Technical Explanation
The paper presents S-LoRA, a system designed to enable the scalable serving of many LoRA adapters. The researchers observe that the common practice of fine-tuning large language models using the pretrain-then-finetune paradigm results in a substantial collection of LoRA adapters derived from a single base model.
To address the challenges of efficiently serving this collection of adapters, S-LoRA introduces several key features:
-
Adapter Storage and Fetching: S-LoRA stores all the LoRA adapters in the main memory and fetches the adapters used by the currently running queries to the GPU memory.
-
Unified Paging: To efficiently use the GPU memory and reduce fragmentation, S-LoRA proposes "Unified Paging," which uses a unified memory pool to manage the dynamic adapter weights with different ranks and the KV cache tensors with varying sequence lengths.
-
Tensor Parallelism and Optimized Kernels: S-LoRA employs a novel tensor parallelism strategy and highly optimized custom CUDA kernels for heterogeneous batching of LoRA computation.
These features enable S-LoRA to serve thousands of LoRA adapters on a single GPU or across multiple GPUs with a small overhead. Compared to state-of-the-art libraries like HuggingFace PEFT and vLLM (with naive support of LoRA serving), S-LoRA can improve the throughput by up to 4 times and increase the number of served adapters by several orders of magnitude.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated system for the scalable serving of LoRA adapters. The researchers have identified a significant opportunity in the common pretrain-then-finetune paradigm and have developed a comprehensive solution to address the challenges.
One potential limitation of the research is the focus on LoRA adapters specifically. While LoRA is a popular fine-tuning method, there may be other adapter-based techniques that could benefit from the scalable serving approach presented in S-LoRA. It would be interesting to see if the system can be extended to support a wider range of adapter-based fine-tuning methods.
Additionally, the paper does not explore the implications of serving a large number of task-specific models for end-users. While the technical capabilities of S-LoRA are impressive, the ethical and social considerations of enabling large-scale customized fine-tuning services could be an area for further research and discussion.
Conclusion
The S-LoRA system presented in this paper represents a significant advancement in the scalable serving of fine-tuned language models. By leveraging the opportunities inherent in the pretrain-then-finetune paradigm and LoRA adapters, S-LoRA enables the efficient serving of thousands of task-specific models on a single GPU or across multiple GPUs.
This work has the potential to unlock new possibilities in the field of customized language model services, where users can access a wide range of fine-tuned models tailored to their specific needs. The researchers' innovative approaches to adapter storage, memory management, and computational optimization demonstrate the potential for significant improvements in the scalability and efficiency of fine-tuned language model serving.
As the field of large language models continues to evolve, systems like S-LoRA will play a crucial role in bridging the gap between research and real-world applications, enabling the deployment of highly specialized and customized language models at scale.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
0
0
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
4/29/2024

Sparse High Rank Adapters
Kartikeya Bhardwaj, Nilesh Prasad Pandey, Sweta Priyadarshi, Viswanath Ganapathy, Rafael Esteves, Shreya Kadambi, Shubhankar Borse, Paul Whatmough, Risheek Garrepalli, Mart Van Baalen, Harris Teague, Markus Nagel
0
0
Low Rank Adaptation (LoRA) has gained massive attention in the recent generative AI research. One of the main advantages of LoRA is its ability to be fused with pretrained models adding no overhead during inference. However, from a mobile deployment standpoint, we can either avoid inference overhead in the fused mode but lose the ability to switch adapters rapidly, or suffer significant (up to 30% higher) inference latency while enabling rapid switching in the unfused mode. LoRA also exhibits concept-loss when multiple adapters are used concurrently. In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged. This results in a highly sparse adapter which can be switched directly in the fused mode. We further provide theoretical and empirical insights on how high sparsity in SHiRA can aid multi-adapter fusion by reducing concept loss. Our extensive experiments on LVMs and LLMs demonstrate that finetuning only a small fraction of the parameters in the base model is sufficient for many tasks while enabling both rapid switching and multi-adapter fusion. Finally, we provide a latency- and memory-efficient SHiRA implementation based on Parameter-Efficient Finetuning (PEFT) Library. This implementation trains at nearly the same speed as LoRA while consuming lower peak GPU memory, thus making SHiRA easy to adopt for practical use cases.
6/21/2024
🌿
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
0
0
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
5/3/2024
🔍
Run LoRA Run: Faster and Lighter LoRA Implementations
Daria Cherniuk, Aleksandr Mikhalev, Ivan Oseledets
0
0
LoRA is a technique that reduces the number of trainable parameters in a neural network by introducing low-rank adapters to linear layers. This technique is used both for fine-tuning and full training of large language models. This paper presents the RunLoRA framework for efficient implementations of LoRA that significantly improves the speed of neural network training and fine-tuning using low-rank adapters. The proposed implementation optimizes the computation of LoRA operations based on dimensions of corresponding linear layer, layer input dimensions and lora rank by choosing best forward and backward computation graph based on FLOPs and time estimations, resulting in faster training without sacrificing accuracy. The experimental results show up to 28% speedup on language modeling networks.
6/17/2024