RWKU: Benchmarking Real-World Knowledge Unlearning for Large Language Models
2406.10890
0
0

Abstract
Large language models (LLMs) inevitably memorize sensitive, copyrighted, and harmful knowledge from the training corpus; therefore, it is crucial to erase this knowledge from the models. Machine unlearning is a promising solution for efficiently removing specific knowledge by post hoc modifying models. In this paper, we propose a Real-World Knowledge Unlearning benchmark (RWKU) for LLM unlearning. RWKU is designed based on the following three key factors: (1) For the task setting, we consider a more practical and challenging unlearning setting, where neither the forget corpus nor the retain corpus is accessible. (2) For the knowledge source, we choose 200 real-world famous people as the unlearning targets and show that such popular knowledge is widely present in various LLMs. (3) For the evaluation framework, we design the forget set and the retain set to evaluate the model's capabilities across various real-world applications. Regarding the forget set, we provide four four membership inference attack (MIA) methods and nine kinds of adversarial attack probes to rigorously test unlearning efficacy. Regarding the retain set, we assess locality and utility in terms of neighbor perturbation, general ability, reasoning ability, truthfulness, factuality, and fluency. We conduct extensive experiments across two unlearning scenarios, two models and six baseline methods and obtain some meaningful findings. We release our benchmark and code publicly at http://rwku-bench.github.io for future work.
Create account to get full access
Overview
• This paper presents a benchmark called RWKU (Real-World Knowledge Unlearning) for evaluating how well large language models can unlearn real-world knowledge.
• The authors argue that the ability to effectively unlearn information is important for addressing issues like privacy, copyright infringement, and biases in language models.
• The RWKU benchmark consists of a set of tasks that measure a model's ability to unlearn specific factual knowledge, while preserving its overall language understanding capabilities.
Plain English Explanation
Large language models, like the ones used in chatbots and virtual assistants, are trained on vast amounts of online data, which can include sensitive or copyrighted information. This creates potential privacy and legal issues. The ability to selectively "unlearn" certain real-world knowledge while maintaining the model's overall language understanding is an important capability.
The researchers in this paper have developed a benchmark called RWKU to test how well language models can do this. The RWKU benchmark includes a set of tasks that evaluate whether a model can effectively forget specific factual information, like the name of a company or a historical event, without losing its general language skills.
This is a challenging task, as language models tend to encode a lot of real-world knowledge during training, and simply "forgetting" certain facts can be difficult. The RWKU benchmark provides a way to rigorously test and compare different approaches to this problem.
The ability to unlearn real-world knowledge could help address issues like privacy, copyright infringement, and biases in language models. It's an important area of research that this paper aims to advance.
Technical Explanation
The RWKU benchmark consists of a set of tasks that measure a language model's ability to unlearn specific factual knowledge while preserving its overall language understanding capabilities. The tasks involve prompting the model with questions or statements that require it to recall or use information that the researchers want the model to unlearn.
The authors evaluate several different approaches to unlearning, including Rethinking Machine Unlearning for Large Language Models, Machine Unlearning for Large Language Models, and RKLD: Reverse KL Divergence-based Knowledge Distillation. They also explore a technique called Large-Scale Knowledge Washing, which aims to remove specific knowledge from the model.
The results of the RWKU benchmark show that while current unlearning techniques can be effective to some degree, there is still room for improvement. The authors identify several challenges, such as the difficulty of selectively forgetting knowledge without impacting overall language understanding, and the potential for unlearning to introduce new biases or errors.
Critical Analysis
The RWKU benchmark represents an important step forward in addressing the challenge of unlearning real-world knowledge in large language models. The authors have clearly identified a significant problem and developed a rigorous way to evaluate potential solutions.
However, the paper also acknowledges several limitations and areas for further research. For example, the tasks in the RWKU benchmark are fairly narrow and may not fully capture the complexity of real-world knowledge that language models need to unlearn. Additionally, the authors note that the current unlearning techniques they evaluated can still have negative impacts on the model's overall performance.
Further research is needed to develop more sophisticated and effective unlearning methods that can better preserve a language model's general language understanding while selectively forgetting specific information. This is a challenging problem, but one that is crucial for addressing the privacy, legal, and ethical concerns around large language models.
Conclusion
The RWKU benchmark presented in this paper is a valuable contribution to the field of large language model research. It highlights the importance of the ability to unlearn real-world knowledge and provides a framework for evaluating different approaches to this problem.
While the current state of the art in unlearning techniques still has room for improvement, this paper lays the groundwork for further advancements. Developing effective unlearning capabilities could help address critical issues like privacy, copyright infringement, and biases in large language models, with significant implications for the responsible development and deployment of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Xiaojun Xu, Yuguang Yao, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
0
0
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
4/8/2024

Machine Unlearning in Large Language Models
Saaketh Koundinya Gundavarapu, Shreya Agarwal, Arushi Arora, Chandana Thimmalapura Jagadeeshaiah
0
0
Machine unlearning, a novel area within artificial intelligence, focuses on addressing the challenge of selectively forgetting or reducing undesirable knowledge or behaviors in machine learning models, particularly in the context of large language models (LLMs). This paper introduces a methodology to align LLMs, such as Open Pre-trained Transformer Language Models, with ethical, privacy, and safety standards by leveraging the gradient ascent algorithm for knowledge unlearning. Our approach aims to selectively erase or modify learned information in LLMs, targeting harmful responses and copyrighted content. This paper presents a dual-pronged approach to enhance the ethical and safe behavior of large language models (LLMs) by addressing the issues of harmful responses and copyrighted content. To mitigate harmful responses, we applied gradient ascent on the PKU dataset, achieving a 75% reduction in harmful responses for Open Pre-trained Transformer Language Models (OPT1.3b and OPT2.7b) citet{zhang2022opt} while retaining previous knowledge using the TruthfulQA dataset citet{DBLP:journals/corr/abs-2109-07958}. For handling copyrighted content, we constructed a custom dataset based on the Lord of the Rings corpus and aligned LLMs (OPT1.3b and OPT2.7b) citet{zhang2022opt} through LoRA: Low-Rank Adaptation of Large Language Models citet{DBLP:journals/corr/abs-2106-09685} finetuning. Subsequently, we employed gradient ascent to unlearn the Lord of the Rings content, resulting in a remarkable reduction in the presence of copyrighted material. To maintain a diverse knowledge base, we utilized the Book Corpus dataset. Additionally, we propose a new evaluation technique for assessing the effectiveness of harmful unlearning.
5/27/2024

RKLD: Reverse KL-Divergence-based Knowledge Distillation for Unlearning Personal Information in Large Language Models
Bichen Wang, Yuzhe Zi, Yixin Sun, Yanyan Zhao, Bing Qin
0
0
With the passage of the Right to Be Forgotten (RTBF) regulations and the scaling up of language model training datasets, research on model unlearning in large language models (LLMs) has become more crucial. Before the era of LLMs, machine unlearning research focused mainly on classification tasks in models with small parameters. In these tasks, the content to be forgotten or retained is clear and straightforward. However, as parameter sizes have grown and tasks have become more complex, balancing forget quality and model utility has become more challenging, especially in scenarios involving personal data instead of classification results. Existing methods based on gradient ascent and its variants often struggle with this balance, leading to unintended information loss or partial forgetting. To address this challenge, we propose RKLD, a novel textbf{R}everse textbf{KL}-Divergence-based Knowledge textbf{D}istillation unlearning algorithm for LLMs targeting the unlearning of personal information. Through RKLD, we achieve significant forget quality and effectively maintain the model utility in our experiments.
6/5/2024
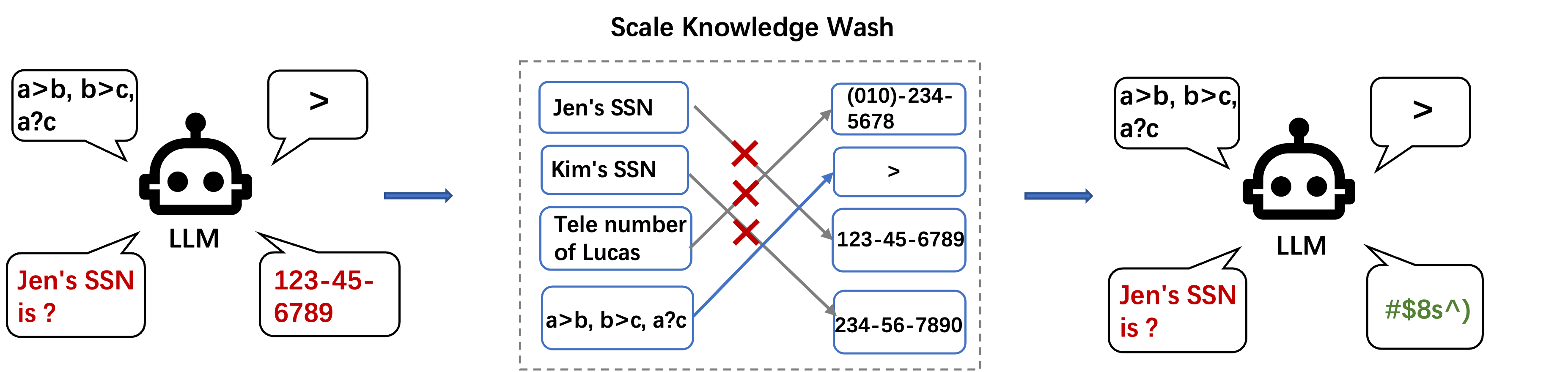
Large Scale Knowledge Washing
Yu Wang, Ruihan Wu, Zexue He, Xiusi Chen, Julian McAuley
0
0
Large language models show impressive abilities in memorizing world knowledge, which leads to concerns regarding memorization of private information, toxic or sensitive knowledge, and copyrighted content. We introduce the problem of Large Scale Knowledge Washing, focusing on unlearning an extensive amount of factual knowledge. Previous unlearning methods usually define the reverse loss and update the model via backpropagation, which may affect the model's fluency and reasoning ability or even destroy the model due to extensive training with the reverse loss. Existing works introduce additional data from downstream tasks to prevent the model from losing capabilities, which requires downstream task awareness. Controlling the tradeoff of unlearning and maintaining existing capabilities is also challenging. To this end, we propose LAW (Large Scale Washing) to update the MLP layers in decoder-only large language models to perform knowledge washing, as inspired by model editing methods and based on the hypothesis that knowledge and reasoning are disentanglable. We derive a new objective with the knowledge to be unlearned to update the weights of certain MLP layers. Experimental results demonstrate the effectiveness of LAW in forgetting target knowledge while maintaining reasoning ability. The code will be open-sourced at https://github.com/wangyu-ustc/LargeScaleWashing.
5/29/2024