Large Scale Knowledge Washing
2405.16720
0
0
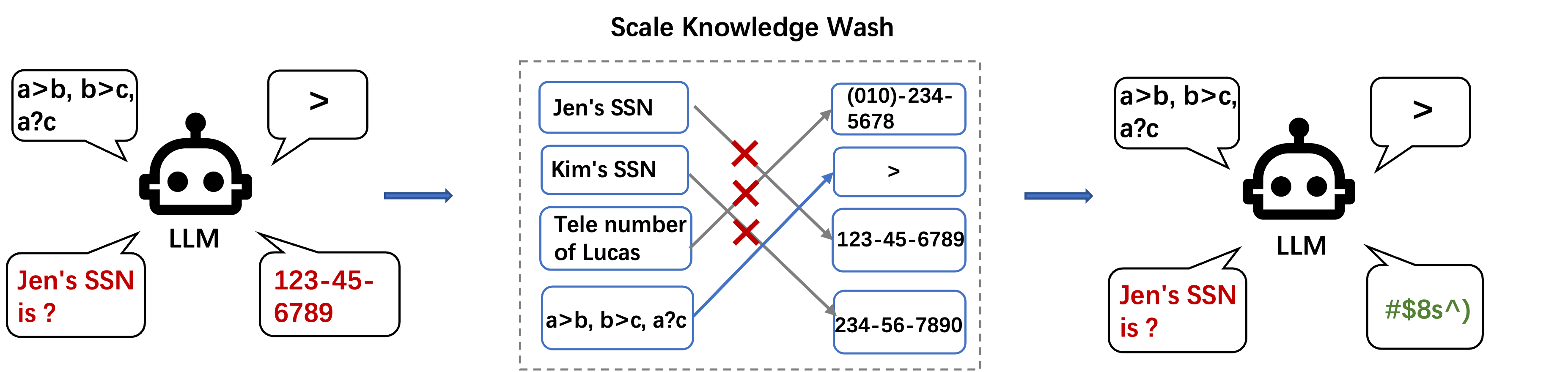
Abstract
Large language models show impressive abilities in memorizing world knowledge, which leads to concerns regarding memorization of private information, toxic or sensitive knowledge, and copyrighted content. We introduce the problem of Large Scale Knowledge Washing, focusing on unlearning an extensive amount of factual knowledge. Previous unlearning methods usually define the reverse loss and update the model via backpropagation, which may affect the model's fluency and reasoning ability or even destroy the model due to extensive training with the reverse loss. Existing works introduce additional data from downstream tasks to prevent the model from losing capabilities, which requires downstream task awareness. Controlling the tradeoff of unlearning and maintaining existing capabilities is also challenging. To this end, we propose LAW (Large Scale Washing) to update the MLP layers in decoder-only large language models to perform knowledge washing, as inspired by model editing methods and based on the hypothesis that knowledge and reasoning are disentanglable. We derive a new objective with the knowledge to be unlearned to update the weights of certain MLP layers. Experimental results demonstrate the effectiveness of LAW in forgetting target knowledge while maintaining reasoning ability. The code will be open-sourced at https://github.com/wangyu-ustc/LargeScaleWashing.
Create account to get full access
Overview
- This paper proposes a novel approach called "Large Scale Knowledge Washing" for removing unwanted knowledge from large language models.
- The authors explore techniques to selectively "unlearn" specific information or biases that may have been acquired during the model's training.
- The research aims to provide a systematic way to control and manage the knowledge contained in these powerful AI systems.
Plain English Explanation
The paper discusses a method called "Large Scale Knowledge Washing" that could allow us to selectively remove certain information or biases from large language models. These AI systems are trained on vast amounts of data and can end up absorbing all kinds of knowledge, including things we may not want them to know.
Machine Unlearning in Large Language Models and Rethinking Machine Unlearning in Large Language Models have explored similar ideas, looking at ways to "unlearn" unwanted information. The proposed "Large Scale Knowledge Washing" approach builds on this, aiming to provide a more systematic way to control and manage the knowledge contained in these powerful AI systems.
The key idea is to develop techniques that can target and remove specific pieces of information or biases from the model, without having to retrain the entire system from scratch. This could be useful in scenarios where we want to fix mistakes or remove harmful content that the model has picked up during its training.
Imagine a language model that has learned some inappropriate jokes or biased views. With "Large Scale Knowledge Washing," we might be able to selectively remove just those problematic elements, while keeping the model's overall capabilities intact. This could help make these AI systems more reliable and trustworthy.
Technical Explanation
The paper presents a framework for "Large Scale Knowledge Washing" that allows for the selective unlearning of specific information or biases in large language models. The authors draw inspiration from previous work on machine unlearning and rethinking machine unlearning in large language models.
The key technical contributions include:
-
Targeted Unlearning Techniques: The authors develop methods to identify and remove targeted knowledge or biases from the model's parameters and embeddings, without disrupting the overall performance.
-
Efficient Unlearning Algorithms: The proposed algorithms aim to achieve unlearning in a computationally efficient manner, making it feasible to apply the techniques at scale.
-
Empirical Evaluation: The paper provides experimental results demonstrating the effectiveness of the "Large Scale Knowledge Washing" approach on various language tasks and datasets, including measures of knowledge retention and unlearning.
-
Theoretical Analysis: The authors also present a theoretical analysis of the unlearning process, exploring factors such as the stability of the unlearned knowledge and the impact on the model's generalization capabilities.
The research builds on recent work exploring methods for improving the "digital forgetting" capabilities of large language models, as well as broader surveys of unlearning approaches in this domain.
Critical Analysis
The "Large Scale Knowledge Washing" approach proposed in this paper represents an important step towards developing more controllable and transparent large language models. Being able to selectively remove unwanted knowledge or biases is a valuable capability, as it can help ensure these powerful AI systems are aligned with our values and goals.
However, the paper does not fully address some of the potential challenges and limitations of this approach. For example, the authors do not delve into the complexities of identifying and defining what constitutes "unwanted" knowledge in the first place, which can be a highly subjective and context-dependent task.
Additionally, while the paper demonstrates the effectiveness of the unlearning techniques, it is unclear how the process might impact the model's overall performance and generalization abilities. Further research is needed to fully understand the trade-offs and long-term implications of such selective unlearning.
Towards Natural Machine Unlearning and the broader survey of unlearning approaches highlight the need for more holistic and interpretable methods for managing the knowledge within large language models. The "Large Scale Knowledge Washing" approach represents an important step in this direction, but additional work is needed to address these complex challenges fully.
Conclusion
The "Large Scale Knowledge Washing" paper presents a novel framework for selectively removing unwanted knowledge or biases from large language models. This capability is crucial as these AI systems become more powerful and ubiquitous, as it allows for greater control and transparency in how they acquire and retain information.
While the proposed techniques show promise, the paper also raises important questions about the challenges and trade-offs involved in managing the knowledge within these complex models. Ongoing research in this area, such as work on natural machine unlearning and broader surveys of unlearning approaches, will be essential in developing robust and trustworthy large language models that can be reliably deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Machine Unlearning in Large Language Models
Saaketh Koundinya Gundavarapu, Shreya Agarwal, Arushi Arora, Chandana Thimmalapura Jagadeeshaiah
0
0
Machine unlearning, a novel area within artificial intelligence, focuses on addressing the challenge of selectively forgetting or reducing undesirable knowledge or behaviors in machine learning models, particularly in the context of large language models (LLMs). This paper introduces a methodology to align LLMs, such as Open Pre-trained Transformer Language Models, with ethical, privacy, and safety standards by leveraging the gradient ascent algorithm for knowledge unlearning. Our approach aims to selectively erase or modify learned information in LLMs, targeting harmful responses and copyrighted content. This paper presents a dual-pronged approach to enhance the ethical and safe behavior of large language models (LLMs) by addressing the issues of harmful responses and copyrighted content. To mitigate harmful responses, we applied gradient ascent on the PKU dataset, achieving a 75% reduction in harmful responses for Open Pre-trained Transformer Language Models (OPT1.3b and OPT2.7b) citet{zhang2022opt} while retaining previous knowledge using the TruthfulQA dataset citet{DBLP:journals/corr/abs-2109-07958}. For handling copyrighted content, we constructed a custom dataset based on the Lord of the Rings corpus and aligned LLMs (OPT1.3b and OPT2.7b) citet{zhang2022opt} through LoRA: Low-Rank Adaptation of Large Language Models citet{DBLP:journals/corr/abs-2106-09685} finetuning. Subsequently, we employed gradient ascent to unlearn the Lord of the Rings content, resulting in a remarkable reduction in the presence of copyrighted material. To maintain a diverse knowledge base, we utilized the Book Corpus dataset. Additionally, we propose a new evaluation technique for assessing the effectiveness of harmful unlearning.
5/27/2024

RWKU: Benchmarking Real-World Knowledge Unlearning for Large Language Models
Zhuoran Jin, Pengfei Cao, Chenhao Wang, Zhitao He, Hongbang Yuan, Jiachun Li, Yubo Chen, Kang Liu, Jun Zhao
0
0
Large language models (LLMs) inevitably memorize sensitive, copyrighted, and harmful knowledge from the training corpus; therefore, it is crucial to erase this knowledge from the models. Machine unlearning is a promising solution for efficiently removing specific knowledge by post hoc modifying models. In this paper, we propose a Real-World Knowledge Unlearning benchmark (RWKU) for LLM unlearning. RWKU is designed based on the following three key factors: (1) For the task setting, we consider a more practical and challenging unlearning setting, where neither the forget corpus nor the retain corpus is accessible. (2) For the knowledge source, we choose 200 real-world famous people as the unlearning targets and show that such popular knowledge is widely present in various LLMs. (3) For the evaluation framework, we design the forget set and the retain set to evaluate the model's capabilities across various real-world applications. Regarding the forget set, we provide four four membership inference attack (MIA) methods and nine kinds of adversarial attack probes to rigorously test unlearning efficacy. Regarding the retain set, we assess locality and utility in terms of neighbor perturbation, general ability, reasoning ability, truthfulness, factuality, and fluency. We conduct extensive experiments across two unlearning scenarios, two models and six baseline methods and obtain some meaningful findings. We release our benchmark and code publicly at http://rwku-bench.github.io for future work.
6/18/2024
💬
Towards Safer Large Language Models through Machine Unlearning
Zheyuan Liu, Guangyao Dou, Zhaoxuan Tan, Yijun Tian, Meng Jiang
0
0
The rapid advancement of Large Language Models (LLMs) has demonstrated their vast potential across various domains, attributed to their extensive pretraining knowledge and exceptional generalizability. However, LLMs often encounter challenges in generating harmful content when faced with problematic prompts. To address this problem, existing work attempted to implement a gradient ascent based approach to prevent LLMs from producing harmful output. While these methods can be effective, they frequently impact the model utility in responding to normal prompts. To address this gap, we introduce Selective Knowledge negation Unlearning (SKU), a novel unlearning framework for LLMs, designed to eliminate harmful knowledge while preserving utility on normal prompts. Specifically, SKU is consisted of two stages: harmful knowledge acquisition stage and knowledge negation stage. The first stage aims to identify and acquire harmful knowledge within the model, whereas the second is dedicated to remove this knowledge. SKU selectively isolates and removes harmful knowledge in model parameters, ensuring the model's performance remains robust on normal prompts. Our experiments conducted across various LLM architectures demonstrate that SKU identifies a good balance point between removing harmful information and preserving utility.
6/6/2024

Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Xiaojun Xu, Yuguang Yao, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
0
0
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
4/8/2024