S-SAM: SVD-based Fine-Tuning of Segment Anything Model for Medical Image Segmentation

0
Sign in to get full access
Overview
- The paper proposes a method called S-SAM (SVD-based Fine-Tuning of Segment Anything Model) for medical image segmentation.
- S-SAM fine-tunes the Segment Anything Model (SAM) using Singular Value Decomposition (SVD) to adapt it to medical image segmentation tasks.
- The method aims to improve the segmentation performance of SAM on medical images without requiring extensive fine-tuning or a large amount of annotated data.
Plain English Explanation
The Segment Anything Model (SAM) is a powerful AI model that can segment objects in images with just a few clicks. However, when used for medical image segmentation, its performance may not be optimal. The researchers behind the S-SAM method wanted to find a way to improve SAM's performance on medical images without the need for extensive fine-tuning or a large amount of annotated data.
Their solution is to use a technique called Singular Value Decomposition (SVD) to fine-tune the SAM model. SVD is a mathematical method that can help identify the most important features in an image. By applying SVD to the SAM model, the researchers were able to extract the key features that are relevant for medical image segmentation and use that knowledge to fine-tune the model.
The resulting S-SAM model is able to segment medical images more accurately than the original SAM model, without requiring a lot of additional training data or computational resources. This makes it a potentially valuable tool for medical professionals who need to analyze medical images quickly and accurately.
Technical Explanation
The researchers propose a method called S-SAM (SVD-based Fine-Tuning of Segment Anything Model) to adapt the Segment Anything Model (SAM) for medical image segmentation tasks.
The key steps of the S-SAM method are:
-
Feature Extraction: The researchers use Singular Value Decomposition (SVD) to extract the most important features from the SAM model. SVD is a technique that can identify the underlying structure of high-dimensional data, such as the features learned by a deep learning model.
-
Fine-Tuning: The researchers then use the extracted features to fine-tune the SAM model for medical image segmentation. This fine-tuning process is much more efficient than training the model from scratch, as it only requires a small amount of annotated medical image data.
-
Inference: The fine-tuned S-SAM model can then be used to segment medical images, with improved performance compared to the original SAM model.
The researchers evaluate the S-SAM method on several medical image segmentation datasets, including brain MRI, chest X-ray, and retinal OCT images. They show that S-SAM outperforms the original SAM model and other fine-tuning approaches, while requiring fewer training samples and computational resources.
Critical Analysis
The S-SAM method presented in this paper is a novel and interesting approach to adapting the Segment Anything Model for medical image segmentation tasks. The use of Singular Value Decomposition to extract the most important features from the pre-trained SAM model is a clever idea that can help improve the model's performance on medical images without requiring extensive fine-tuning or a large amount of annotated data.
However, the paper does not provide a detailed analysis of the limitations or potential issues with the S-SAM method. For example, it would be interesting to know how the S-SAM method compares to other fine-tuning approaches, such as PP-SAM or SimSAM, in terms of performance, computational requirements, and data efficiency.
Additionally, the paper does not discuss the potential challenges or limitations of using the S-SAM method in real-world medical settings, such as the impact of image artifacts, variations in imaging modalities, or the need for interpretability and explainability of the segmentation results.
Overall, the S-SAM method appears to be a promising approach to improving the performance of the Segment Anything Model on medical image segmentation tasks, but further research and evaluation would be needed to fully understand its strengths, weaknesses, and practical implications.
Conclusion
The S-SAM method proposed in this paper is a novel approach to adapting the Segment Anything Model (SAM) for medical image segmentation tasks. By leveraging Singular Value Decomposition (SVD) to fine-tune the SAM model, the researchers were able to improve its performance on medical images without requiring extensive training or a large amount of annotated data.
The S-SAM method has the potential to be a valuable tool for medical professionals who need to analyze medical images quickly and accurately. By providing a more efficient and effective way to segment medical images, the S-SAM method could help streamline various healthcare workflows, from diagnostic imaging to surgical planning.
However, further research is needed to fully understand the limitations and practical implications of the S-SAM method, as well as how it compares to other fine-tuning approaches for medical image segmentation. As the field of medical AI continues to evolve, methods like S-SAM will likely play an increasingly important role in improving the accuracy and efficiency of medical image analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
S-SAM: SVD-based Fine-Tuning of Segment Anything Model for Medical Image Segmentation
Jay N. Paranjape, Shameema Sikder, S. Swaroop Vedula, Vishal M. Patel
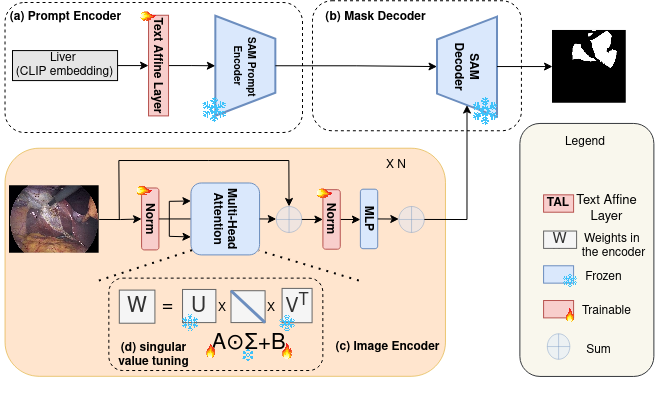
Medical image segmentation has been traditionally approached by training or fine-tuning the entire model to cater to any new modality or dataset. However, this approach often requires tuning a large number of parameters during training. With the introduction of the Segment Anything Model (SAM) for prompted segmentation of natural images, many efforts have been made towards adapting it efficiently for medical imaging, thus reducing the training time and resources. However, these methods still require expert annotations for every image in the form of point prompts or bounding box prompts during training and inference, making it tedious to employ them in practice. In this paper, we propose an adaptation technique, called S-SAM, that only trains parameters equal to 0.4% of SAM's parameters and at the same time uses simply the label names as prompts for producing precise masks. This not only makes tuning SAM more efficient than the existing adaptation methods but also removes the burden of providing expert prompts. We call this modified version S-SAM and evaluate it on five different modalities including endoscopic images, x-ray, ultrasound, CT, and histology images. Our experiments show that S-SAM outperforms state-of-the-art methods as well as existing SAM adaptation methods while tuning a significantly less number of parameters. We release the code for S-SAM at https://github.com/JayParanjape/SVDSAM.
Read more8/14/2024
0
SAM Fewshot Finetuning for Anatomical Segmentation in Medical Images
Weiyi Xie, Nathalie Willems, Shubham Patil, Yang Li, Mayank Kumar
We propose a straightforward yet highly effective few-shot fine-tuning strategy for adapting the Segment Anything (SAM) to anatomical segmentation tasks in medical images. Our novel approach revolves around reformulating the mask decoder within SAM, leveraging few-shot embeddings derived from a limited set of labeled images (few-shot collection) as prompts for querying anatomical objects captured in image embeddings. This innovative reformulation greatly reduces the need for time-consuming online user interactions for labeling volumetric images, such as exhaustively marking points and bounding boxes to provide prompts slice by slice. With our method, users can manually segment a few 2D slices offline, and the embeddings of these annotated image regions serve as effective prompts for online segmentation tasks. Our method prioritizes the efficiency of the fine-tuning process by exclusively training the mask decoder through caching mechanisms while keeping the image encoder frozen. Importantly, this approach is not limited to volumetric medical images, but can generically be applied to any 2D/3D segmentation task. To thoroughly evaluate our method, we conducted extensive validation on four datasets, covering six anatomical segmentation tasks across two modalities. Furthermore, we conducted a comparative analysis of different prompting options within SAM and the fully-supervised nnU-Net. The results demonstrate the superior performance of our method compared to SAM employing only point prompts (approximately 50% improvement in IoU) and performs on-par with fully supervised methods whilst reducing the requirement of labeled data by at least an order of magnitude.
Read more7/8/2024

0
PP-SAM: Perturbed Prompts for Robust Adaptation of Segment Anything Model for Polyp Segmentation
Md Mostafijur Rahman, Mustafa Munir, Debesh Jha, Ulas Bagci, Radu Marculescu
The Segment Anything Model (SAM), originally designed for general-purpose segmentation tasks, has been used recently for polyp segmentation. Nonetheless, fine-tuning SAM with data from new imaging centers or clinics poses significant challenges. This is because this necessitates the creation of an expensive and time-intensive annotated dataset, along with the potential for variability in user prompts during inference. To address these issues, we propose a robust fine-tuning technique, PP-SAM, that allows SAM to adapt to the polyp segmentation task with limited images. To this end, we utilize variable perturbed bounding box prompts (BBP) to enrich the learning context and enhance the model's robustness to BBP perturbations during inference. Rigorous experiments on polyp segmentation benchmarks reveal that our variable BBP perturbation significantly improves model resilience. Notably, on Kvasir, 1-shot fine-tuning boosts the DICE score by 20% and 37% with 50 and 100-pixel BBP perturbations during inference, respectively. Moreover, our experiments show that 1-shot, 5-shot, and 10-shot PP-SAM with 50-pixel perturbations during inference outperform a recent state-of-the-art (SOTA) polyp segmentation method by 26%, 7%, and 5% DICE scores, respectively. Our results motivate the broader applicability of our PP-SAM for other medical imaging tasks with limited samples. Our implementation is available at https://github.com/SLDGroup/PP-SAM.
Read more5/28/2024
0
SimSAM: Zero-shot Medical Image Segmentation via Simulated Interaction
Benjamin Towle, Xin Chen, Ke Zhou
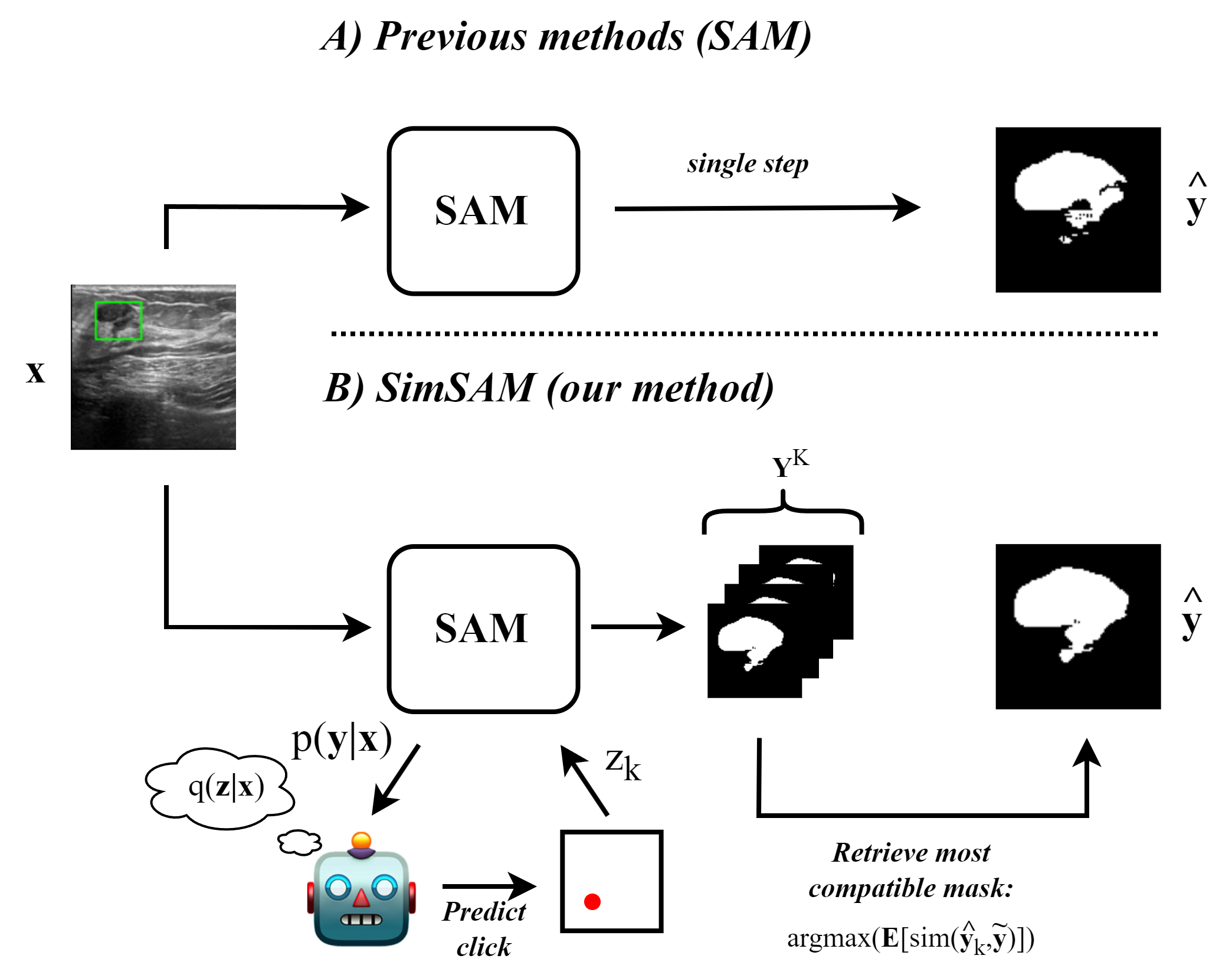
The recently released Segment Anything Model (SAM) has shown powerful zero-shot segmentation capabilities through a semi-automatic annotation setup in which the user can provide a prompt in the form of clicks or bounding boxes. There is growing interest around applying this to medical imaging, where the cost of obtaining expert annotations is high, privacy restrictions may limit sharing of patient data, and model generalisation is often poor. However, there are large amounts of inherent uncertainty in medical images, due to unclear object boundaries, low-contrast media, and differences in expert labelling style. Currently, SAM is known to struggle in a zero-shot setting to adequately annotate the contours of the structure of interest in medical images, where the uncertainty is often greatest, thus requiring significant manual correction. To mitigate this, we introduce textbf{Sim}ulated Interaction for textbf{S}egment textbf{A}nything textbf{M}odel (textsc{textbf{SimSAM}}), an approach that leverages simulated user interaction to generate an arbitrary number of candidate masks, and uses a novel aggregation approach to output the most compatible mask. Crucially, our method can be used during inference directly on top of SAM, without any additional training requirement. Quantitatively, we evaluate our method across three publicly available medical imaging datasets, and find that our approach leads to up to a 15.5% improvement in contour segmentation accuracy compared to zero-shot SAM. Our code is available at url{https://github.com/BenjaminTowle/SimSAM}.
Read more6/4/2024