Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
2406.15486
0
0

Abstract
Large language models (LLMs) now support extremely long context windows, but the quadratic complexity of vanilla attention results in significantly long Time-to-First-Token (TTFT) latency. Existing approaches to address this complexity require additional pretraining or finetuning, and often sacrifice model accuracy. In this paper, we first provide both theoretical and empirical foundations for near-lossless sparse attention. We find dynamically capturing head-specific sparse patterns at runtime with low overhead is crucial. To address this, we propose SampleAttention, an adaptive structured and near-lossless sparse attention. Leveraging observed significant sparse patterns, SampleAttention attends to a fixed percentage of adjacent tokens to capture local window patterns, and employs a two-stage query-guided key-value filtering approach, which adaptively select a minimum set of key-values with low overhead, to capture column stripe patterns. Comprehensive evaluations show that SampleAttention can seamlessly replace vanilla attention in off-the-shelf LLMs with nearly no accuracy loss, and reduces TTFT by up to $2.42times$ compared with FlashAttention.
Create account to get full access
Overview
- This paper introduces a new approach called Adaptive Structured Sparse Attention (ASSA) for accelerating long-context language model inference.
- ASSA adaptively adjusts the sparsity pattern of attention layers to achieve near-lossless speedup compared to standard dense attention.
- The method leverages structured sparsity and can be applied to a variety of large language models (LLMs) without retraining.
Plain English Explanation
Language models like GPT-3 are powerful, but running them on long input texts can be slow. This paper presents a new technique called Adaptive Structured Sparse Attention (ASSA) that can speed up the inference process for these models without significantly impacting their accuracy.
The key idea is to take advantage of sparsity - the fact that many of the connections between words in the model are weak and can be safely removed. ASSA paper and other works like HIP Attention and QUEST have shown that you can prune these weak connections to get a speedup.
ASSA goes a step further by adaptively adjusting the sparsity pattern as it runs the model. This means the model can focus its attention on the most important parts of the long input text, speeding things up without losing much accuracy. The approach also uses a structured sparsity pattern, which allows it to be efficiently implemented on hardware like GPUs.
By using ASSA, the authors were able to accelerate long-context language model inference by up to 2.5x with only a small drop in performance. This could make these powerful models much more practical to use in real-world applications that require processing lengthy inputs.
Technical Explanation
The key innovation in this paper is the Adaptive Structured Sparse Attention (ASSA) mechanism. ASSA builds on prior work like Sparser is Faster, HIP Attention, and QUEST that have shown the benefits of sparsifying attention layers in large language models.
The key innovation is that ASSA adaptively adjusts the sparsity pattern of the attention layers during inference. This allows the model to focus its attention on the most important parts of the long input text, achieving a near-lossless speedup compared to standard dense attention.
ASSA works by learning a set of sparse attention masks that are applied to the attention weights. These masks are learned in an unsupervised way during a pre-processing step, using techniques like low-rank matrix factorization. During inference, the appropriate mask is selected based on the current input, allowing the sparsity pattern to adapt.
The authors also leverage structured sparsity, organizing the sparse connections in a way that enables efficient GPU acceleration. This is in contrast to approaches that use unstructured sparsity, which can be harder to implement efficiently.
The paper evaluates ASSA on a variety of large language models and long-context tasks, showing speedups of up to 2.5x with minimal accuracy degradation. This demonstrates the effectiveness of the adaptive sparse attention mechanism.
Critical Analysis
The ASSA approach represents a promising step forward in accelerating large language models for long-context applications. The ability to adaptively adjust the sparsity pattern is a clever idea that builds on prior work in sparse attention.
One potential limitation is that the pre-processing step to learn the sparse attention masks adds some computational overhead. The authors mention this, but note that the cost is amortized over many inference runs. It would be interesting to see how ASSA compares to approaches that learn the sparsity pattern on-the-fly, like Lean Attention and MOA.
Another area for further exploration is the interaction between ASSA and other model compression techniques. Combining ASSA with methods like weight pruning, quantization, or distillation could lead to even greater efficiency gains.
Overall, the ASSA approach is a well-designed and empirically validated contribution to the field of efficient large language model inference. With further refinement and integration with other techniques, it has the potential to make these powerful models more practical for real-world applications.
Conclusion
This paper introduces Adaptive Structured Sparse Attention (ASSA), a new method for accelerating long-context language model inference with minimal accuracy degradation. By adaptively adjusting the sparsity pattern of attention layers, ASSA can achieve speedups of up to 2.5x compared to standard dense attention.
The structured sparsity used by ASSA enables efficient GPU implementation, making it a practical solution for deploying large language models in real-world applications that require processing lengthy inputs. While there are some limitations to address, ASSA represents an important advance in the field of efficient deep learning inference.
As large language models continue to grow in scale and capability, techniques like ASSA will be crucial for making these powerful models accessible and practical. The insights from this work, along with related approaches in sparse attention, could have a significant impact on the future of efficient AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Sparser is Faster and Less is More: Efficient Sparse Attention for Long-Range Transformers
Chao Lou, Zixia Jia, Zilong Zheng, Kewei Tu
0
0
Accommodating long sequences efficiently in autoregressive Transformers, especially within an extended context window, poses significant challenges due to the quadratic computational complexity and substantial KV memory requirements inherent in self-attention mechanisms. In this work, we introduce SPARSEK Attention, a novel sparse attention mechanism designed to overcome these computational and memory obstacles while maintaining performance. Our approach integrates a scoring network and a differentiable top-k mask operator, SPARSEK, to select a constant number of KV pairs for each query, thereby enabling gradient-based optimization. As a result, SPARSEK Attention offers linear time complexity and constant memory footprint during generation. Experimental results reveal that SPARSEK Attention outperforms previous sparse attention methods and provides significant speed improvements during both training and inference, particularly in language modeling and downstream tasks. Furthermore, our method can be seamlessly integrated into pre-trained Large Language Models (LLMs) with minimal fine-tuning, offering a practical solution for effectively managing long-range dependencies in diverse applications.
6/26/2024

HiP Attention: Sparse Sub-Quadratic Attention with Hierarchical Attention Pruning
Heejun Lee, Geon Park, Youngwan Lee, Jina Kim, Wonyoung Jeong, Myeongjae Jeon, Sung Ju Hwang
0
0
In modern large language models (LLMs), increasing sequence lengths is a crucial challenge for enhancing their comprehension and coherence in handling complex tasks such as multi-modal question answering. However, handling long context sequences with LLMs is prohibitively costly due to the conventional attention mechanism's quadratic time and space complexity, and the context window size is limited by the GPU memory. Although recent works have proposed linear and sparse attention mechanisms to address this issue, their real-world applicability is often limited by the need to re-train pre-trained models. In response, we propose a novel approach, Hierarchically Pruned Attention (HiP), which simultaneously reduces the training and inference time complexity from $O(T^2)$ to $O(T log T)$ and the space complexity from $O(T^2)$ to $O(T)$. To this end, we devise a dynamic sparse attention mechanism that generates an attention mask through a novel tree-search-like algorithm for a given query on the fly. HiP is training-free as it only utilizes the pre-trained attention scores to spot the positions of the top-$k$ most significant elements for each query. Moreover, it ensures that no token is overlooked, unlike the sliding window-based sub-quadratic attention methods, such as StreamingLLM. Extensive experiments on diverse real-world benchmarks demonstrate that HiP significantly reduces prompt (i.e., prefill) and decoding latency and memory usage while maintaining high generation performance with little or no degradation. As HiP allows pretrained LLMs to scale to millions of tokens on commodity GPUs with no additional engineering due to its easy plug-and-play deployment, we believe that our work will have a large practical impact, opening up the possibility to many long-context LLM applications previously infeasible.
6/17/2024
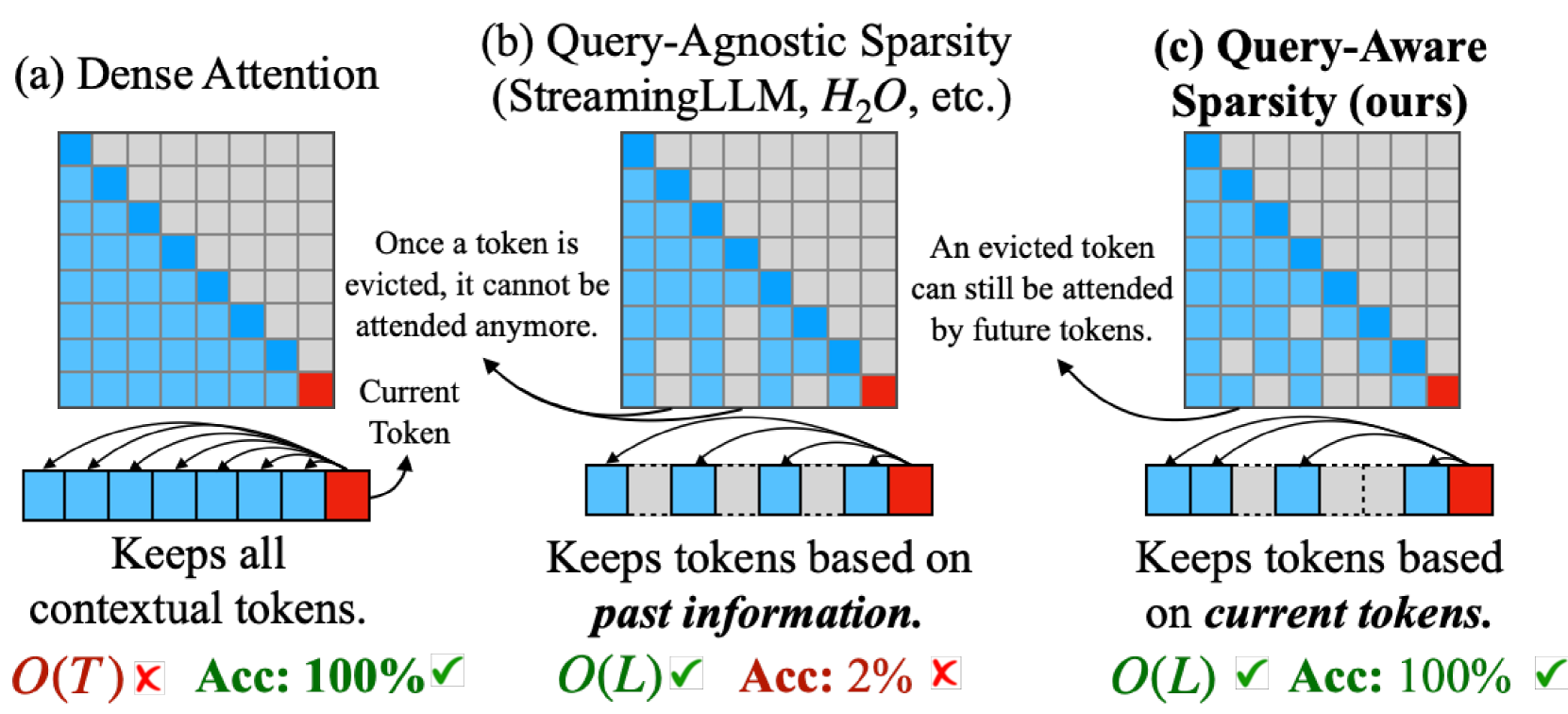
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, Song Han
0
0
As the demand for long-context large language models (LLMs) increases, models with context windows of up to 128K or 1M tokens are becoming increasingly prevalent. However, long-context LLM inference is challenging since the inference speed decreases significantly as the sequence length grows. This slowdown is primarily caused by loading a large KV cache during self-attention. Previous works have shown that a small portion of critical tokens will dominate the attention outcomes. However, we observe the criticality of a token highly depends on the query. To this end, we propose Quest, a query-aware KV cache selection algorithm. Quest keeps track of the minimal and maximal Key values in KV cache pages and estimates the criticality of a given page using Query vectors. By only loading the Top-K critical KV cache pages for attention, Quest significantly speeds up self-attention without sacrificing accuracy. We show that Quest can achieve up to 2.23x self-attention speedup, which reduces inference latency by 7.03x while performing well on tasks with long dependencies with negligible accuracy loss. Code is available at http://github.com/mit-han-lab/Quest .
6/18/2024

Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
0
0
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
5/20/2024