Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
2406.10774
0
0
Abstract
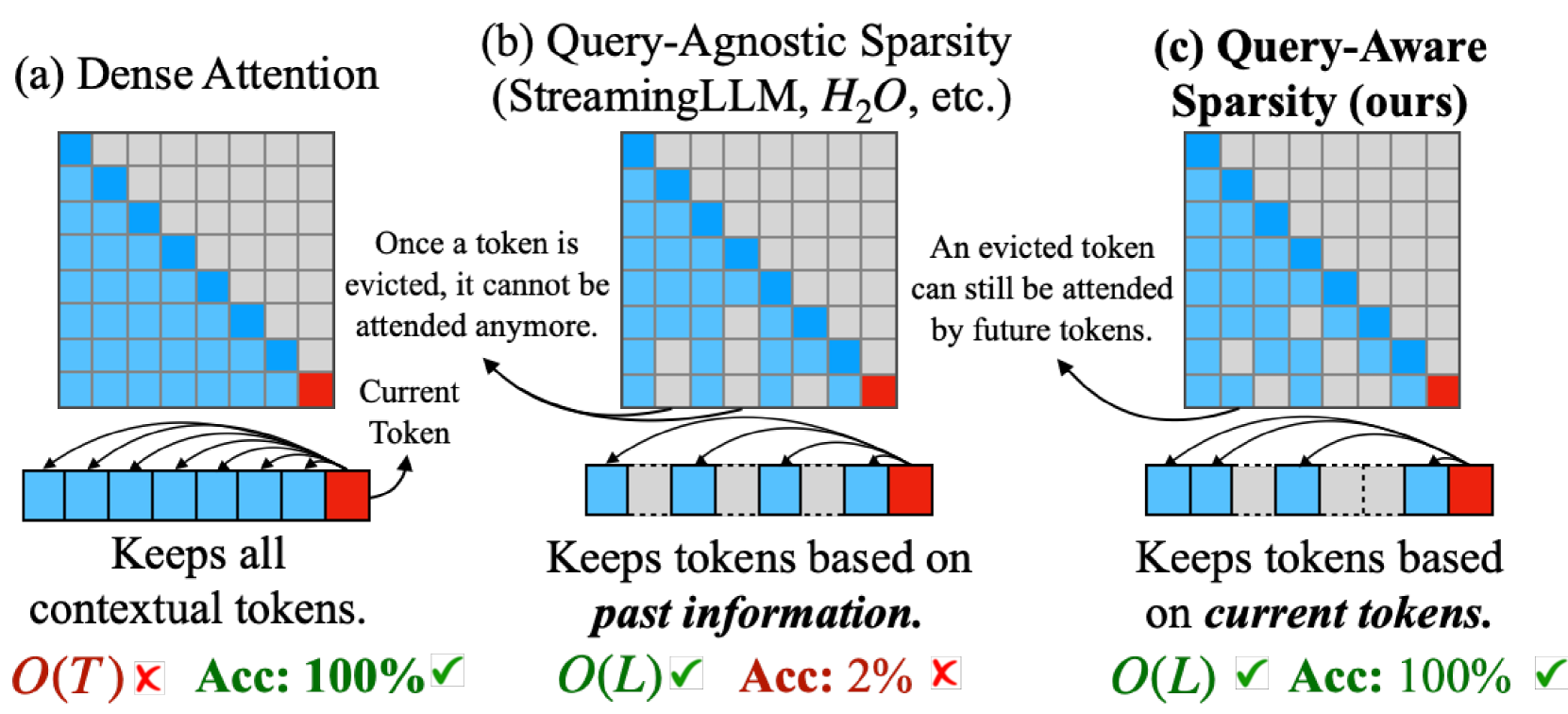
As the demand for long-context large language models (LLMs) increases, models with context windows of up to 128K or 1M tokens are becoming increasingly prevalent. However, long-context LLM inference is challenging since the inference speed decreases significantly as the sequence length grows. This slowdown is primarily caused by loading a large KV cache during self-attention. Previous works have shown that a small portion of critical tokens will dominate the attention outcomes. However, we observe the criticality of a token highly depends on the query. To this end, we propose Quest, a query-aware KV cache selection algorithm. Quest keeps track of the minimal and maximal Key values in KV cache pages and estimates the criticality of a given page using Query vectors. By only loading the Top-K critical KV cache pages for attention, Quest significantly speeds up self-attention without sacrificing accuracy. We show that Quest can achieve up to 2.23x self-attention speedup, which reduces inference latency by 7.03x while performing well on tasks with long dependencies with negligible accuracy loss. Code is available at http://github.com/mit-han-lab/Quest .
Create account to get full access
Overview
- The paper "Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference" proposes a novel approach to improve the efficiency of long-context inference for large language models (LLMs).
- It introduces a technique called "query-aware sparsity" that selectively activates the most relevant parts of the LLM based on the input query, reducing the computational and memory requirements during inference.
- The paper also explores other complementary techniques, such as QAQ: Quality-Adaptive Quantization for LLM Key-Value Cache and SnapKV: LLM Knows What You Are Looking, to further enhance the efficiency of long-context LLM inference.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, using these models to process long passages of text, known as "long-context inference," can be computationally expensive and memory-intensive.
The researchers behind the "Quest" paper have developed a technique called "query-aware sparsity" to address this problem. The idea is to selectively activate only the parts of the LLM that are most relevant to the input query, rather than processing the entire model. This reduces the computational and memory requirements during inference, making the process more efficient.
For example, imagine you're using an LLM to answer a specific question about a long article. The "query-aware sparsity" approach would focus the model's attention on the relevant sections of the article, rather than processing the entire text. This can save a significant amount of time and resources.
The paper also discusses complementary techniques, such as QAQ, which optimizes the storage of the LLM's internal data, and SnapKV, which helps the LLM understand what information the user is looking for. These approaches work together to make long-context LLM inference more efficient and practical for real-world applications.
Technical Explanation
The "Quest" paper introduces a novel technique called "query-aware sparsity" to improve the efficiency of long-context inference for large language models (LLMs). The key idea is to selectively activate only the most relevant parts of the LLM based on the input query, reducing the computational and memory requirements during inference.
The authors propose a two-stage approach. First, they use a lightweight "query encoder" to analyze the input query and identify the most relevant parts of the LLM that should be activated. This is done by learning a sparse attention map that highlights the important regions of the LLM's parameters.
In the second stage, the authors use this sparse attention map to guide the LLM's inference process, only activating the necessary parts of the model. This "query-aware sparsity" technique is complemented by other efficiency-enhancing methods, such as QAQ, which optimizes the storage of the LLM's internal data, and SnapKV, which helps the LLM understand what information the user is looking for.
The paper presents extensive experiments on various long-context tasks, including question answering and document summarization, demonstrating significant improvements in inference speed and memory usage compared to baseline methods. The authors also analyze the effectiveness of their approach under different query complexity scenarios and provide insights into the trade-offs between accuracy and efficiency.
Critical Analysis
The "Quest" paper presents a compelling and practical approach to improving the efficiency of long-context LLM inference. The key strength of the "query-aware sparsity" technique is its ability to selectively activate the most relevant parts of the LLM, reducing the computational and memory requirements without sacrificing too much accuracy.
However, the paper does acknowledge some limitations. The authors note that the performance of the "query-aware sparsity" technique may be sensitive to the quality of the query encoder, which could be a potential point of failure. Additionally, the paper does not explore the impact of the "query-aware sparsity" approach on the LLM's generalization capabilities or its ability to handle out-of-distribution queries.
Further research could investigate ways to make the query encoder more robust and explore the long-term implications of this selective activation approach on the LLM's overall performance and learning dynamics. QuickLLaMA, for example, also explores query-aware techniques for efficient LLM inference and could provide additional insights.
Overall, the "Quest" paper presents a promising direction for improving the efficiency of long-context LLM inference, with potential real-world applications in areas such as document retrieval, question answering, and dialogue systems. The authors' approach, combined with complementary techniques like QAQ and SnapKV, could lead to significant advancements in the field of efficient and practical LLM deployment.
Conclusion
The "Quest" paper introduces a novel technique called "query-aware sparsity" to improve the efficiency of long-context inference for large language models (LLMs). By selectively activating the most relevant parts of the LLM based on the input query, the approach reduces the computational and memory requirements during inference, making LLM deployment more practical for real-world applications.
The paper also explores complementary techniques, such as QAQ and SnapKV, that work together to enhance the overall efficiency of long-context LLM inference.
The "Quest" paper represents an important step forward in making LLMs more accessible and practical for a wide range of applications, from document retrieval to dialogue systems. As the field of AI continues to evolve, techniques like "query-aware sparsity" will play a crucial role in unlocking the full potential of these powerful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Quest: Query-centric Data Synthesis Approach for Long-context Scaling of Large Language Model
Chaochen Gao, Xing Wu, Qi Fu, Songlin Hu
0
0
Large language models, initially pre-trained with a limited context length, can better handle longer texts by continuing training on a corpus with extended contexts. However, obtaining effective long-context data is challenging due to the scarcity and uneven distribution of long documents across different domains. To address this issue, we propose a Query-centric data synthesis method, abbreviated as Quest. Quest is an interpretable method based on the observation that documents retrieved by similar queries are relevant but low-redundant, thus well-suited for synthesizing long-context data. The method is also scalable and capable of constructing large amounts of long-context data. Using Quest, we synthesize a long-context dataset up to 128k context length, significantly outperforming other data synthesis methods on multiple long-context benchmark datasets. In addition, we further verify that the Quest method is predictable through scaling law experiments, making it a reliable solution for advancing long-context models.
6/21/2024

Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
Qianchao Zhu, Jiangfei Duan, Chang Chen, Siran Liu, Xiuhong Li, Guanyu Feng, Xin Lv, Huanqi Cao, Xiao Chuanfu, Xingcheng Zhang, Dahua Lin, Chao Yang
0
0
Large language models (LLMs) now support extremely long context windows, but the quadratic complexity of vanilla attention results in significantly long Time-to-First-Token (TTFT) latency. Existing approaches to address this complexity require additional pretraining or finetuning, and often sacrifice model accuracy. In this paper, we first provide both theoretical and empirical foundations for near-lossless sparse attention. We find dynamically capturing head-specific sparse patterns at runtime with low overhead is crucial. To address this, we propose SampleAttention, an adaptive structured and near-lossless sparse attention. Leveraging observed significant sparse patterns, SampleAttention attends to a fixed percentage of adjacent tokens to capture local window patterns, and employs a two-stage query-guided key-value filtering approach, which adaptively select a minimum set of key-values with low overhead, to capture column stripe patterns. Comprehensive evaluations show that SampleAttention can seamlessly replace vanilla attention in off-the-shelf LLMs with nearly no accuracy loss, and reduces TTFT by up to $2.42times$ compared with FlashAttention.
7/1/2024
QAQ: Quality Adaptive Quantization for LLM KV Cache
Shichen Dong, Wen Cheng, Jiayu Qin, Wei Wang
0
0
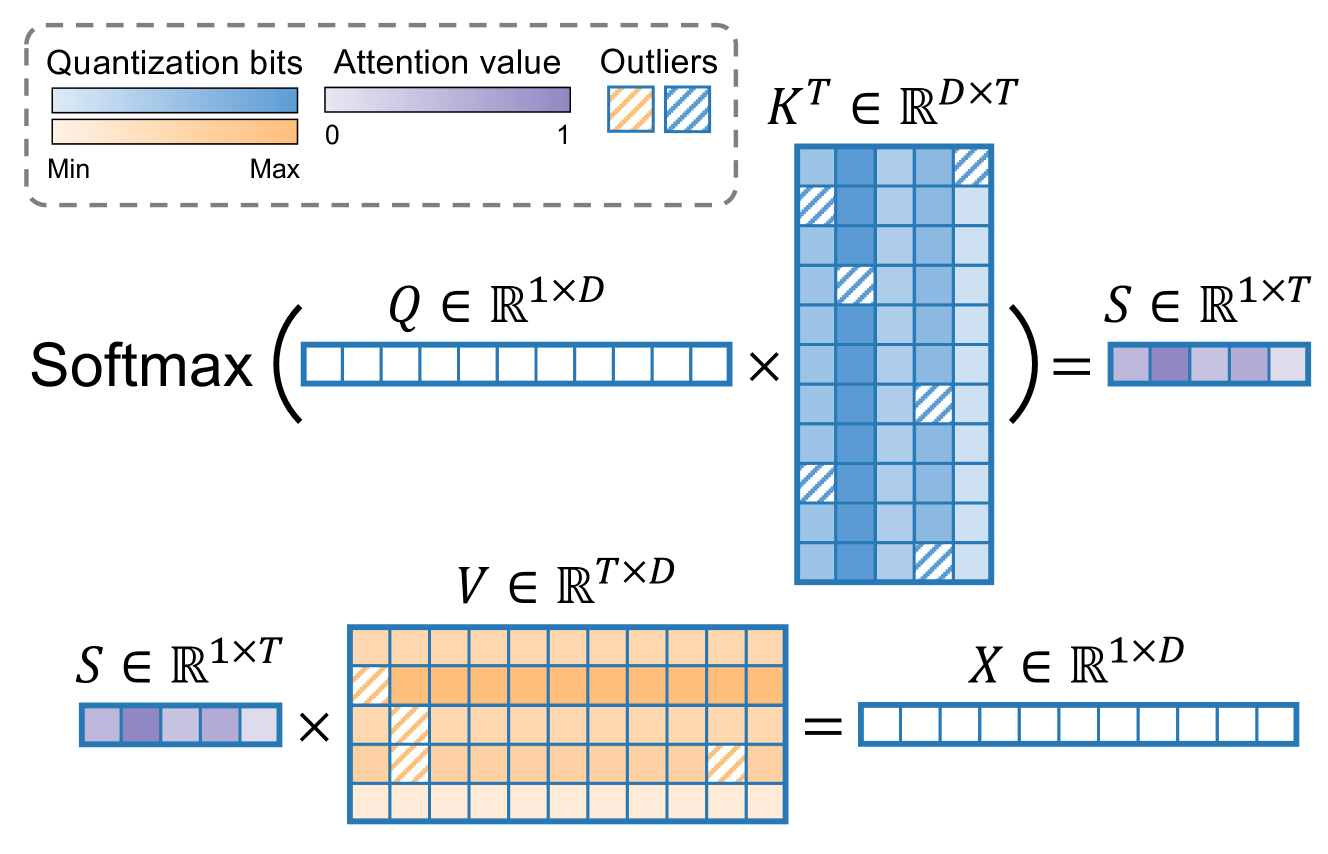
The emergence of LLMs has ignited a fresh surge of breakthroughs in NLP applications, particularly in domains such as question-answering systems and text generation. As the need for longer context grows, a significant bottleneck in model deployment emerges due to the linear expansion of the Key-Value (KV) cache with the context length. Existing methods primarily rely on various hypotheses, such as sorting the KV cache based on attention scores for replacement or eviction, to compress the KV cache and improve model throughput. However, heuristics used by these strategies may wrongly evict essential KV cache, which can significantly degrade model performance. In this paper, we propose QAQ, a Quality Adaptive Quantization scheme for the KV cache. We theoretically demonstrate that key cache and value cache exhibit distinct sensitivities to quantization, leading to the formulation of separate quantization strategies for their non-uniform quantization. Through the integration of dedicated outlier handling, as well as an improved attention-aware approach, QAQ achieves up to 10x the compression ratio of the KV cache size with a neglectable impact on model performance. QAQ significantly reduces the practical hurdles of deploying LLMs, opening up new possibilities for longer-context applications. The code is available at github.com/ClubieDong/KVCacheQuantization.
4/15/2024

QuickLLaMA: Query-aware Inference Acceleration for Large Language Models
Jingyao Li, Han Shi, Xin Jiang, Zhenguo Li, Hong Xu, Jiaya Jia
0
0
The capacity of Large Language Models (LLMs) to comprehend and reason over long contexts is pivotal for advancements in diverse fields. Yet, they still stuggle with capturing long-distance dependencies within sequences to deeply understand semantics. To address this issue, we introduce Query-aware Inference for LLMs (Q-LLM), a system designed to process extensive sequences akin to human cognition. By focusing on memory data relevant to a given query, Q-LLM can accurately capture pertinent information within a fixed window size and provide precise answers to queries. It doesn't require extra training and can be seamlessly integrated with any LLMs. Q-LLM using LLaMA3 (QuickLLaMA) can read Harry Potter within 30s and accurately answer the questions. Q-LLM improved by 7.17% compared to the current state-of-the-art on LLaMA3, and by 3.26% on Mistral on the $infty$-bench. In the Needle-in-a-Haystack task, On widely recognized benchmarks, Q-LLM improved upon the current SOTA by 7.0% on Mistral and achieves 100% on LLaMA3. Our code can be found in https://github.com/dvlab-research/Q-LLM.
6/12/2024