SANeRF-HQ: Segment Anything for NeRF in High Quality

0
Sign in to get full access
Overview
- This paper presents a novel method called SANeRF-HQ, which enables high-quality segmentation of objects within Neural Radiance Fields (NeRFs) - a popular technique for 3D scene representation.
- The key contributions include:
- A segmentation model that can accurately separate individual objects from the NeRF, with high-fidelity details.
- A framework for integrating the segmentation model with the NeRF optimization process, enabling end-to-end training.
- Comprehensive experiments demonstrating the effectiveness of SANeRF-HQ on complex 3D scenes.
Plain English Explanation
SANeRF-HQ is a new technique that allows you to break down and isolate individual objects within a 3D scene represented by a Neural Radiance Field (NeRF). NeRFs are a powerful way to capture the geometry and appearance of a 3D environment, but they typically treat the scene as a single, unified whole.
The key innovation in SANeRF-HQ is a segmentation model that can identify and extract the different objects in the NeRF, preserving the high-quality details of each one. This is done by integrating the segmentation directly into the NeRF optimization process, allowing the model to learn how to separate the objects in an end-to-end fashion.
The researchers demonstrate that SANeRF-HQ can effectively isolate individual objects, even in complex 3D scenes with many elements. This could be useful for applications like 3D object generation, scene understanding, and robotic perception, where having a detailed, segmented 3D representation is crucial.
Technical Explanation
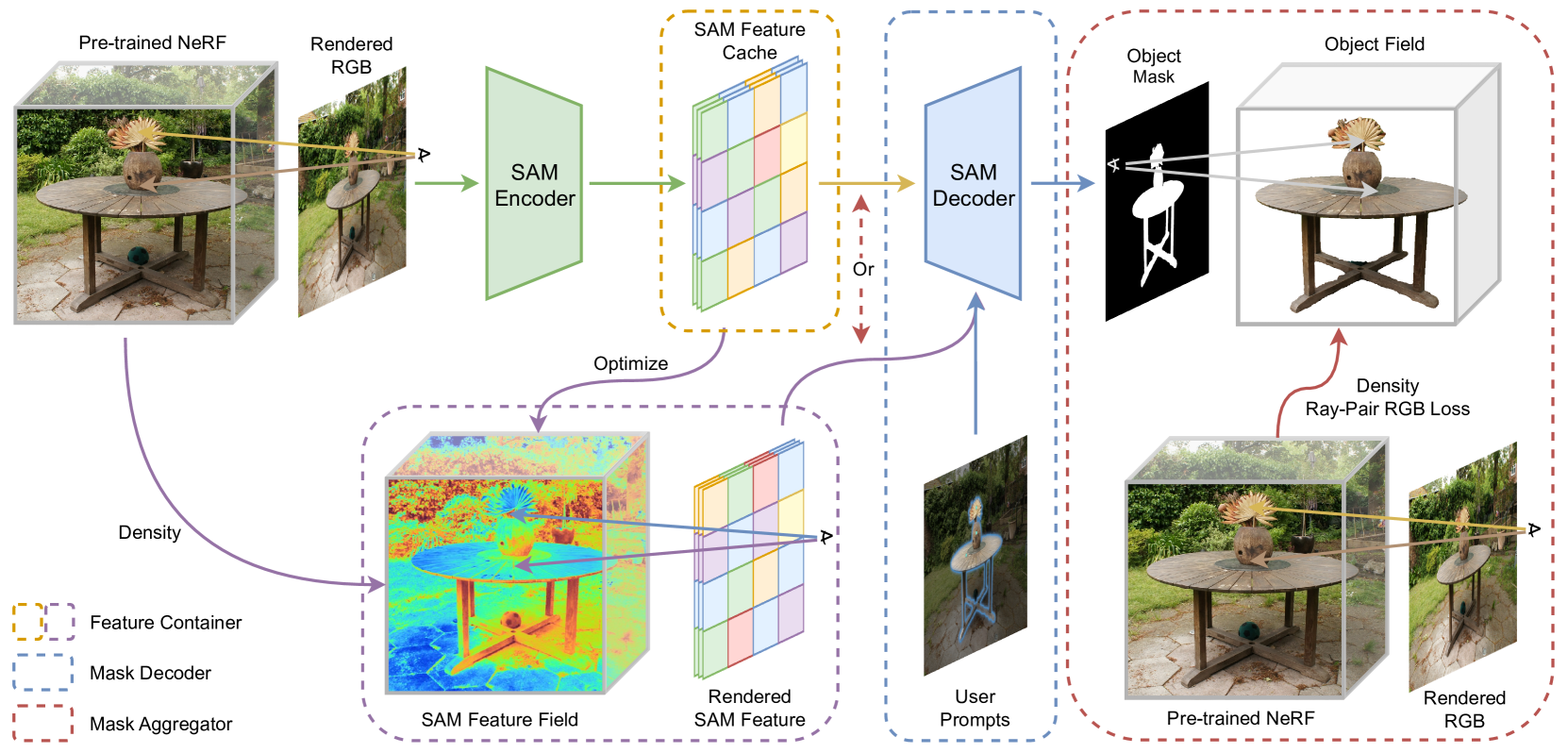
The core of SANeRF-HQ is a segmentation model that takes a NeRF as input and outputs a set of per-object density and color fields. This is achieved by embedding the segmentation module directly into the NeRF optimization process, allowing the model to learn how to separate the objects in an end-to-end fashion.
Specifically, the NeRF is represented as a set of per-object density and color fields, each of which is parameterized by a separate neural network. A semantic segmentation module is then used to predict a per-pixel object mask, which is used to select the appropriate per-object fields when rendering the final image.
The researchers demonstrate that this approach can effectively segment complex 3D scenes, preserving high-fidelity details for each identified object. They evaluate SANeRF-HQ on a range of datasets, showing significant improvements over baseline methods in terms of both segmentation accuracy and render quality.
Critical Analysis
The paper presents a compelling approach for high-quality object segmentation within NeRFs, which is an important capability for many 3D vision and robotics applications. However, there are a few potential limitations and areas for further research:
- The segmentation model is still limited to a fixed number of objects, which may not be suitable for scenes with a highly variable or unknown number of elements. Extending the approach to handle open-set segmentation could be a valuable direction.
- The paper does not explore the efficiency or inference speed of the SANeRF-HQ model, which could be an important practical consideration for real-time applications.
- While the experiments demonstrate strong performance on synthetic datasets, further validation on real-world, noisy data would be helpful to assess the robustness of the approach.
Overall, SANeRF-HQ represents an exciting advance in 3D scene understanding, and the authors have laid the groundwork for further research in this direction. Continuing to improve the performance and capabilities of these segmentation models could lead to significant breakthroughs in a variety of 3D perception tasks.
Conclusion
The SANeRF-HQ method presented in this paper represents an important step forward in enabling high-quality object segmentation within Neural Radiance Fields. By integrating the segmentation directly into the NeRF optimization process, the approach can accurately isolate individual objects while preserving the rich, detailed 3D information captured by the NeRF.
This capability has numerous potential applications, from 3D scene understanding and object generation to robotic perception and beyond. As researchers continue to build upon this work, we can expect to see increasingly powerful and versatile tools for analyzing and manipulating complex 3D environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SANeRF-HQ: Segment Anything for NeRF in High Quality
Yichen Liu, Benran Hu, Chi-Keung Tang, Yu-Wing Tai
Recently, the Segment Anything Model (SAM) has showcased remarkable capabilities of zero-shot segmentation, while NeRF (Neural Radiance Fields) has gained popularity as a method for various 3D problems beyond novel view synthesis. Though there exist initial attempts to incorporate these two methods into 3D segmentation, they face the challenge of accurately and consistently segmenting objects in complex scenarios. In this paper, we introduce the Segment Anything for NeRF in High Quality (SANeRF-HQ) to achieve high-quality 3D segmentation of any target object in a given scene. SANeRF-HQ utilizes SAM for open-world object segmentation guided by user-supplied prompts, while leveraging NeRF to aggregate information from different viewpoints. To overcome the aforementioned challenges, we employ density field and RGB similarity to enhance the accuracy of segmentation boundary during the aggregation. Emphasizing on segmentation accuracy, we evaluate our method on multiple NeRF datasets where high-quality ground-truths are available or manually annotated. SANeRF-HQ shows a significant quality improvement over state-of-the-art methods in NeRF object segmentation, provides higher flexibility for object localization, and enables more consistent object segmentation across multiple views. Results and code are available at the project site: https://lyclyc52.github.io/SANeRF-HQ/.
Read more4/9/2024

0
DiscoNeRF: Class-Agnostic Object Field for 3D Object Discovery
Corentin Dumery, Aoxiang Fan, Ren Li, Nicolas Talabot, Pascal Fua
Neural Radiance Fields (NeRFs) have become a powerful tool for modeling 3D scenes from multiple images. However, NeRFs remain difficult to segment into semantically meaningful regions. Previous approaches to 3D segmentation of NeRFs either require user interaction to isolate a single object, or they rely on 2D semantic masks with a limited number of classes for supervision. As a consequence, they generalize poorly to class-agnostic masks automatically generated in real scenes. This is attributable to the ambiguity arising from zero-shot segmentation, yielding inconsistent masks across views. In contrast, we propose a method that is robust to inconsistent segmentations and successfully decomposes the scene into a set of objects of any class. By introducing a limited number of competing object slots against which masks are matched, a meaningful object representation emerges that best explains the 2D supervision and minimizes an additional regularization term. Our experiments demonstrate the ability of our method to generate 3D panoptic segmentations on complex scenes, and extract high-quality 3D assets from NeRFs that can then be used in virtual 3D environments.
Read more9/9/2024
🏅
0
Segment Anything in 3D with Radiance Fields
Jiazhong Cen, Jiemin Fang, Zanwei Zhou, Chen Yang, Lingxi Xie, Xiaopeng Zhang, Wei Shen, Qi Tian
The Segment Anything Model (SAM) emerges as a powerful vision foundation model to generate high-quality 2D segmentation results. This paper aims to generalize SAM to segment 3D objects. Rather than replicating the data acquisition and annotation procedure which is costly in 3D, we design an efficient solution, leveraging the radiance field as a cheap and off-the-shelf prior that connects multi-view 2D images to the 3D space. We refer to the proposed solution as SA3D, short for Segment Anything in 3D. With SA3D, the user is only required to provide a 2D segmentation prompt (e.g., rough points) for the target object in a single view, which is used to generate its corresponding 2D mask with SAM. Next, SA3D alternately performs mask inverse rendering and cross-view self-prompting across various views to iteratively refine the 3D mask of the target object. For one view, mask inverse rendering projects the 2D mask obtained by SAM into the 3D space with guidance of the density distribution learned by the radiance field for 3D mask refinement; Then, cross-view self-prompting extracts reliable prompts automatically as the input to SAM from the rendered 2D mask of the inaccurate 3D mask for a new view. We show in experiments that SA3D adapts to various scenes and achieves 3D segmentation within seconds. Our research reveals a potential methodology to lift the ability of a 2D segmentation model to 3D. Our code is available at https://github.com/Jumpat/SegmentAnythingin3D.
Read more4/17/2024
📊
0
DatasetNeRF: Efficient 3D-aware Data Factory with Generative Radiance Fields
Yu Chi, Fangneng Zhan, Sibo Wu, Christian Theobalt, Adam Kortylewski
Progress in 3D computer vision tasks demands a huge amount of data, yet annotating multi-view images with 3D-consistent annotations, or point clouds with part segmentation is both time-consuming and challenging. This paper introduces DatasetNeRF, a novel approach capable of generating infinite, high-quality 3D-consistent 2D annotations alongside 3D point cloud segmentations, while utilizing minimal 2D human-labeled annotations. Specifically, we leverage the strong semantic prior within a 3D generative model to train a semantic decoder, requiring only a handful of fine-grained labeled samples. Once trained, the decoder efficiently generalizes across the latent space, enabling the generation of infinite data. The generated data is applicable across various computer vision tasks, including video segmentation and 3D point cloud segmentation. Our approach not only surpasses baseline models in segmentation quality, achieving superior 3D consistency and segmentation precision on individual images, but also demonstrates versatility by being applicable to both articulated and non-articulated generative models. Furthermore, we explore applications stemming from our approach, such as 3D-aware semantic editing and 3D inversion.
Read more8/20/2024