SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer
2404.03736
0
1
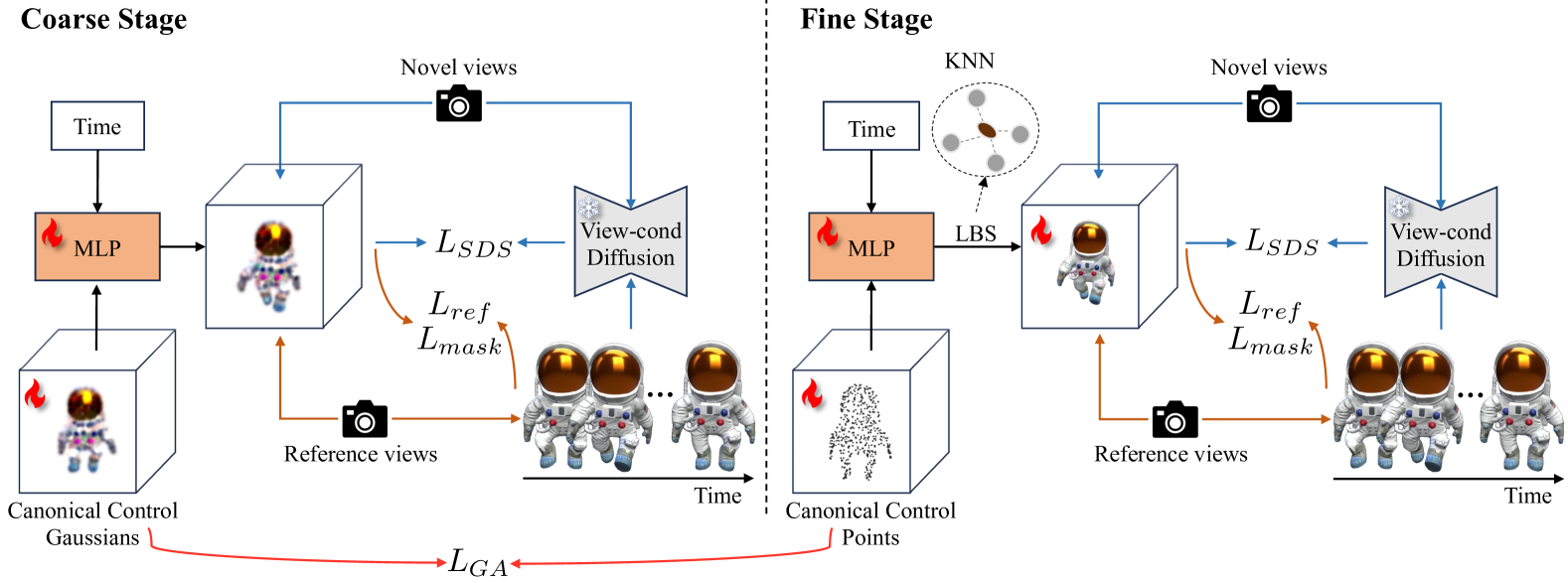
Abstract
Recent advances in 2D/3D generative models enable the generation of dynamic 3D objects from a single-view video. Existing approaches utilize score distillation sampling to form the dynamic scene as dynamic NeRF or dense 3D Gaussians. However, these methods struggle to strike a balance among reference view alignment, spatio-temporal consistency, and motion fidelity under single-view conditions due to the implicit nature of NeRF or the intricate dense Gaussian motion prediction. To address these issues, this paper proposes an efficient, sparse-controlled video-to-4D framework named SC4D, that decouples motion and appearance to achieve superior video-to-4D generation. Moreover, we introduce Adaptive Gaussian (AG) initialization and Gaussian Alignment (GA) loss to mitigate shape degeneration issue, ensuring the fidelity of the learned motion and shape. Comprehensive experimental results demonstrate that our method surpasses existing methods in both quality and efficiency. In addition, facilitated by the disentangled modeling of motion and appearance of SC4D, we devise a novel application that seamlessly transfers the learned motion onto a diverse array of 4D entities according to textual descriptions.
Create account to get full access
Overview
- This paper presents a method called SC4D (Sparse-Controlled Video-to-4D Generation and Motion Transfer) that can generate 4D (3D + time) content from a single input video.
- The key innovations are the use of sparse control points and a novel dynamic Gaussian splatting representation to efficiently represent and manipulate the 4D content.
- SC4D can perform various tasks, including 4D content generation, motion transfer between different actors, and 3D shape reconstruction from a single view.
Plain English Explanation
The paper introduces a new technique called SC4D that can take a regular video as input and turn it into a 3D animated scene that evolves over time. This 3D+time, or "4D", content can be very useful for applications like visual effects, video games, and virtual reality.
The key idea behind SC4D is to use a sparse set of "control points" that define the 3D shape and movement of the objects in the scene. These control points act like handles that you can grab and move around to manipulate the 4D content. This is more efficient than trying to model the entire 3D scene in detail.
To represent the 4D content, SC4D uses a novel technique called "dynamic Gaussian splatting". This treats each point in the 3D scene as a little 3D "blob" that can change shape and move over time, rather than a fixed 3D mesh. This allows the 4D content to be efficiently stored and edited.
With SC4D, you can not only generate new 4D content from a single video, but also transfer the motion from one actor to another. For example, you could take a video of someone dancing and apply that same dance moves to a different character. SC4D can also reconstruct 3D shape information from just a single camera view.
Overall, SC4D provides a powerful and flexible way to create 4D content from regular 2D videos, with applications in visual effects, animation, and virtual/augmented reality.
Technical Explanation
The key technical components of SC4D are:
-
Sparse Control Points: The 4D content is represented using a sparse set of 3D control points that define the shape and movement of the scene. This is more efficient than modeling the entire 3D geometry in detail.
-
Dynamic Gaussian Splatting: To represent the 4D content, SC4D uses a novel "dynamic Gaussian splatting" technique. Each point in the 3D scene is modeled as a 3D Gaussian "blob" that can change shape and move over time. This allows for compact and efficient representation of the 4D content.
-
Video-to-4D Generation: SC4D can take a single input video and automatically generate the corresponding 4D content, including the 3D shape and motion of the scene.
-
Motion Transfer: SC4D can transfer the motion from one actor in a video to a different actor, allowing for novel animation and visual effects.
-
3D Reconstruction: SC4D can also reconstruct the 3D shape of objects in a scene from a single camera view, by leveraging the sparse control point representation.
The paper demonstrates the capabilities of SC4D through a variety of experiments, showcasing its ability to generate high-quality 4D content, perform motion transfer, and reconstruct 3D shape from monocular video.
Critical Analysis
The paper presents a compelling and technically sophisticated approach to 4D content generation and manipulation. The use of sparse control points and dynamic Gaussian splatting is a clever way to efficiently represent and edit the 4D content, overcoming the limitations of traditional 3D mesh-based representations.
However, the paper does not address some potential limitations and areas for future research:
-
Generalization to Complex Scenes: The examples in the paper focus on relatively simple, single-object scenes. It's unclear how well SC4D would scale to more complex, multi-object environments.
-
Temporal Consistency: The paper does not discuss in detail how SC4D ensures temporal consistency in the generated 4D content, which is crucial for realistic animation.
-
Texture and Appearance Modeling: The focus of SC4D is on the 3D geometry and motion, but the paper does not address how texture and appearance information is handled.
-
Evaluation and Comparison: The paper could benefit from a more comprehensive evaluation of SC4D's performance, as well as comparisons to other state-of-the-art methods for 4D content generation and motion transfer.
Overall, SC4D represents an interesting and promising approach to 4D content creation, with potential applications in visual effects, animation, and virtual/augmented reality. Further research addressing the identified limitations could help solidify SC4D's position as a powerful tool for this emerging field.
Conclusion
The SC4D method presented in this paper offers a novel and efficient way to generate 4D content from a single input video. By using sparse control points and dynamic Gaussian splatting, SC4D can create high-quality 3D animations that evolve over time, enabling a variety of applications in visual effects, video game development, and virtual/augmented reality.
The key innovations of SC4D, such as the ability to transfer motion between different actors and reconstruct 3D shape from monocular video, demonstrate the versatility and potential of this approach. While the paper identifies some areas for future research, SC4D represents an important step forward in the field of 4D content creation and manipulation.
As the demand for immersive and interactive digital experiences continues to grow, techniques like SC4D will play an increasingly crucial role in enabling the development of next-generation media and entertainment applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
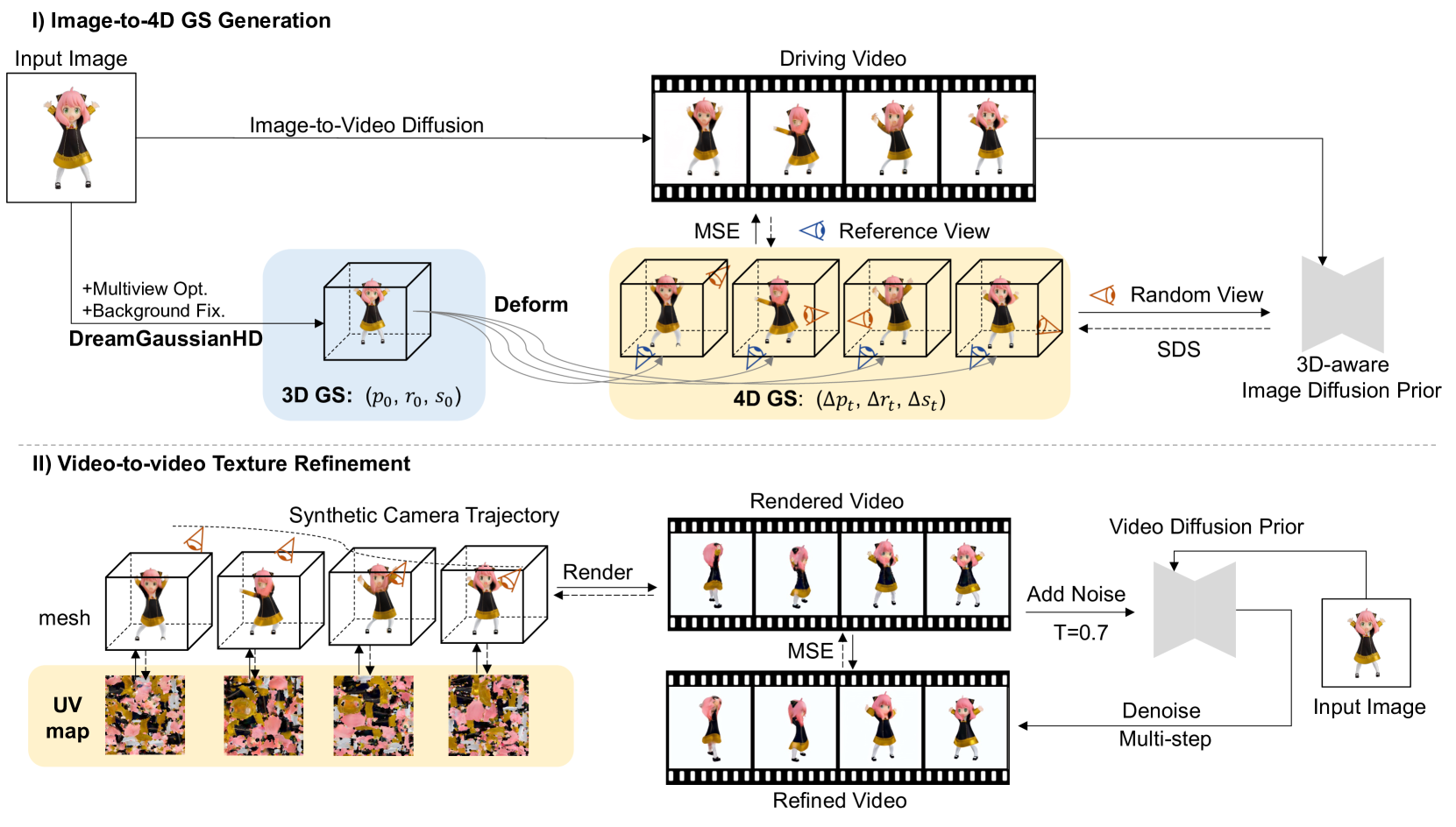
DreamGaussian4D: Generative 4D Gaussian Splatting
Jiawei Ren, Liang Pan, Jiaxiang Tang, Chi Zhang, Ang Cao, Gang Zeng, Ziwei Liu
0
0
4D content generation has achieved remarkable progress recently. However, existing methods suffer from long optimization times, a lack of motion controllability, and a low quality of details. In this paper, we introduce DreamGaussian4D (DG4D), an efficient 4D generation framework that builds on Gaussian Splatting (GS). Our key insight is that combining explicit modeling of spatial transformations with static GS makes an efficient and powerful representation for 4D generation. Moreover, video generation methods have the potential to offer valuable spatial-temporal priors, enhancing the high-quality 4D generation. Specifically, we propose an integral framework with two major modules: 1) Image-to-4D GS - we initially generate static GS with DreamGaussianHD, followed by HexPlane-based dynamic generation with Gaussian deformation; and 2) Video-to-Video Texture Refinement - we refine the generated UV-space texture maps and meanwhile enhance their temporal consistency by utilizing a pre-trained image-to-video diffusion model. Notably, DG4D reduces the optimization time from several hours to just a few minutes, allows the generated 3D motion to be visually controlled, and produces animated meshes that can be realistically rendered in 3D engines.
6/11/2024
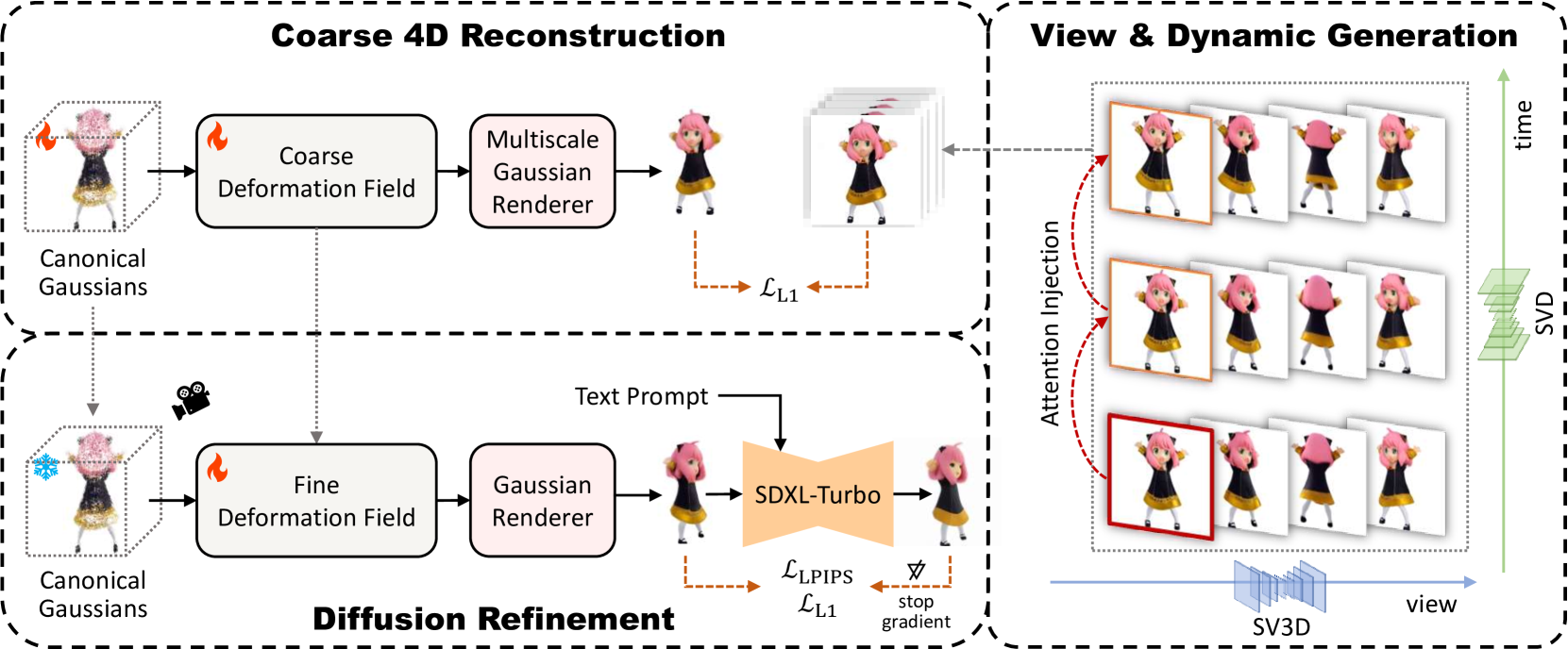
EG4D: Explicit Generation of 4D Object without Score Distillation
Qi Sun, Zhiyang Guo, Ziyu Wan, Jing Nathan Yan, Shengming Yin, Wengang Zhou, Jing Liao, Houqiang Li
0
0
In recent years, the increasing demand for dynamic 3D assets in design and gaming applications has given rise to powerful generative pipelines capable of synthesizing high-quality 4D objects. Previous methods generally rely on score distillation sampling (SDS) algorithm to infer the unseen views and motion of 4D objects, thus leading to unsatisfactory results with defects like over-saturation and Janus problem. Therefore, inspired by recent progress of video diffusion models, we propose to optimize a 4D representation by explicitly generating multi-view videos from one input image. However, it is far from trivial to handle practical challenges faced by such a pipeline, including dramatic temporal inconsistency, inter-frame geometry and texture diversity, and semantic defects brought by video generation results. To address these issues, we propose DG4D, a novel multi-stage framework that generates high-quality and consistent 4D assets without score distillation. Specifically, collaborative techniques and solutions are developed, including an attention injection strategy to synthesize temporal-consistent multi-view videos, a robust and efficient dynamic reconstruction method based on Gaussian Splatting, and a refinement stage with diffusion prior for semantic restoration. The qualitative results and user preference study demonstrate that our framework outperforms the baselines in generation quality by a considerable margin. Code will be released at url{https://github.com/jasongzy/EG4D}.
5/29/2024

Sync4D: Video Guided Controllable Dynamics for Physics-Based 4D Generation
Zhoujie Fu, Jiacheng Wei, Wenhao Shen, Chaoyue Song, Xiaofeng Yang, Fayao Liu, Xulei Yang, Guosheng Lin
0
0
In this work, we introduce a novel approach for creating controllable dynamics in 3D-generated Gaussians using casually captured reference videos. Our method transfers the motion of objects from reference videos to a variety of generated 3D Gaussians across different categories, ensuring precise and customizable motion transfer. We achieve this by employing blend skinning-based non-parametric shape reconstruction to extract the shape and motion of reference objects. This process involves segmenting the reference objects into motion-related parts based on skinning weights and establishing shape correspondences with generated target shapes. To address shape and temporal inconsistencies prevalent in existing methods, we integrate physical simulation, driving the target shapes with matched motion. This integration is optimized through a displacement loss to ensure reliable and genuine dynamics. Our approach supports diverse reference inputs, including humans, quadrupeds, and articulated objects, and can generate dynamics of arbitrary length, providing enhanced fidelity and applicability. Unlike methods heavily reliant on diffusion video generation models, our technique offers specific and high-quality motion transfer, maintaining both shape integrity and temporal consistency.
6/7/2024

4Diffusion: Multi-view Video Diffusion Model for 4D Generation
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao
0
0
Current 4D generation methods have achieved noteworthy efficacy with the aid of advanced diffusion generative models. However, these methods lack multi-view spatial-temporal modeling and encounter challenges in integrating diverse prior knowledge from multiple diffusion models, resulting in inconsistent temporal appearance and flickers. In this paper, we propose a novel 4D generation pipeline, namely 4Diffusion aimed at generating spatial-temporally consistent 4D content from a monocular video. We first design a unified diffusion model tailored for multi-view video generation by incorporating a learnable motion module into a frozen 3D-aware diffusion model to capture multi-view spatial-temporal correlations. After training on a curated dataset, our diffusion model acquires reasonable temporal consistency and inherently preserves the generalizability and spatial consistency of the 3D-aware diffusion model. Subsequently, we propose 4D-aware Score Distillation Sampling loss, which is based on our multi-view video diffusion model, to optimize 4D representation parameterized by dynamic NeRF. This aims to eliminate discrepancies arising from multiple diffusion models, allowing for generating spatial-temporally consistent 4D content. Moreover, we devise an anchor loss to enhance the appearance details and facilitate the learning of dynamic NeRF. Extensive qualitative and quantitative experiments demonstrate that our method achieves superior performance compared to previous methods.
6/3/2024