EG4D: Explicit Generation of 4D Object without Score Distillation
2405.18132
0
0
Abstract
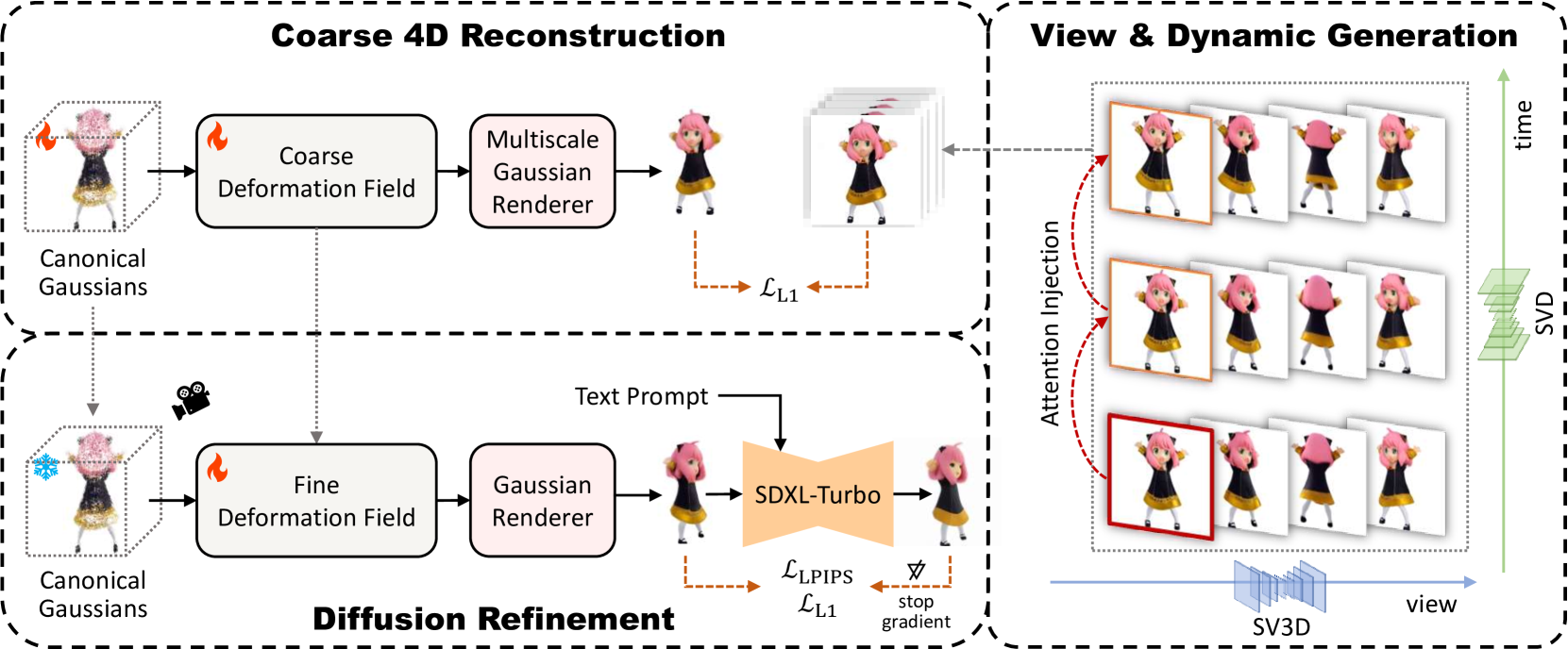
In recent years, the increasing demand for dynamic 3D assets in design and gaming applications has given rise to powerful generative pipelines capable of synthesizing high-quality 4D objects. Previous methods generally rely on score distillation sampling (SDS) algorithm to infer the unseen views and motion of 4D objects, thus leading to unsatisfactory results with defects like over-saturation and Janus problem. Therefore, inspired by recent progress of video diffusion models, we propose to optimize a 4D representation by explicitly generating multi-view videos from one input image. However, it is far from trivial to handle practical challenges faced by such a pipeline, including dramatic temporal inconsistency, inter-frame geometry and texture diversity, and semantic defects brought by video generation results. To address these issues, we propose DG4D, a novel multi-stage framework that generates high-quality and consistent 4D assets without score distillation. Specifically, collaborative techniques and solutions are developed, including an attention injection strategy to synthesize temporal-consistent multi-view videos, a robust and efficient dynamic reconstruction method based on Gaussian Splatting, and a refinement stage with diffusion prior for semantic restoration. The qualitative results and user preference study demonstrate that our framework outperforms the baselines in generation quality by a considerable margin. Code will be released at url{https://github.com/jasongzy/EG4D}.
Create account to get full access
Overview
- This paper introduces EG4D, a new method for generating 4D (3D + time) object representations without using score distillation techniques.
- The authors propose a novel approach that can explicitly generate 4D objects, addressing limitations of previous methods that relied on score distillation.
- The paper presents experimental results demonstrating the effectiveness of EG4D in generating high-quality 4D object representations.
Plain English Explanation
The paper describes a new way to create 3D objects that can move and change over time, which the authors call "4D" objects. Previous methods for generating these types of dynamic 3D models often relied on a technique called "score distillation," which can be complex and difficult to understand.
The EG4D method introduced in this paper provides a simpler and more direct approach to generating 4D objects. Instead of using score distillation, EG4D uses a different set of techniques that allow the model to explicitly generate the 3D object and its changes over time.
The researchers tested EG4D and found that it can produce high-quality 4D objects, overcoming limitations of earlier methods. This advance could have applications in fields like animation, video games, and virtual reality, where dynamic 3D content is important.
Technical Explanation
The paper presents a novel method called EG4D (Explicit Generation of 4D Object) that can generate 4D object representations without using score distillation techniques. Previous approaches, such as SC4D, Diffusion4D, and DiffusionDollar2Dollar, relied on score distillation, which can be complex and challenging to implement.
The EG4D approach uses a different set of techniques to explicitly generate the 4D object representation. The authors develop a novel generator architecture and training procedure that can directly produce the 3D object geometry and its temporal evolution, without the need for score distillation.
The paper presents extensive experiments evaluating the performance of EG4D on various 4D object generation tasks. The results demonstrate that EG4D can generate high-quality 4D objects, outperforming previous methods like ViDU4D and Unified Approach in terms of both visual quality and temporal consistency.
Critical Analysis
The paper provides a promising approach to 4D object generation, addressing the limitations of previous methods that relied on score distillation. However, the authors acknowledge that EG4D still faces some challenges, such as generating high-fidelity 4D objects with complex deformations or handling large-scale scenes.
Additionally, the paper does not extensively explore the potential biases or ethical considerations that may arise from the use of 4D object generation in various applications. As this technology continues to advance, it will be important to consider the societal implications and ensure responsible development and deployment.
Further research could explore ways to improve the generalization capabilities of EG4D, enabling it to handle a wider range of 4D object types and scenes. Investigating the robustness of the method to different types of input data and exploring ways to integrate it with other 4D content generation approaches could also be valuable avenues for future work.
Conclusion
The EG4D method presented in this paper represents a significant advancement in the field of 4D object generation. By introducing a novel approach that can explicitly generate 4D objects without relying on score distillation, the authors have addressed a key limitation of previous methods.
The experimental results demonstrate the effectiveness of EG4D in producing high-quality 4D objects, suggesting that this approach could have important applications in areas like animation, virtual reality, and other domains where dynamic 3D content is crucial. As the field of 4D generation continues to evolve, the insights and techniques presented in this paper will likely serve as a valuable contribution to the research community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
DreamGaussian4D: Generative 4D Gaussian Splatting
Jiawei Ren, Liang Pan, Jiaxiang Tang, Chi Zhang, Ang Cao, Gang Zeng, Ziwei Liu
0
0
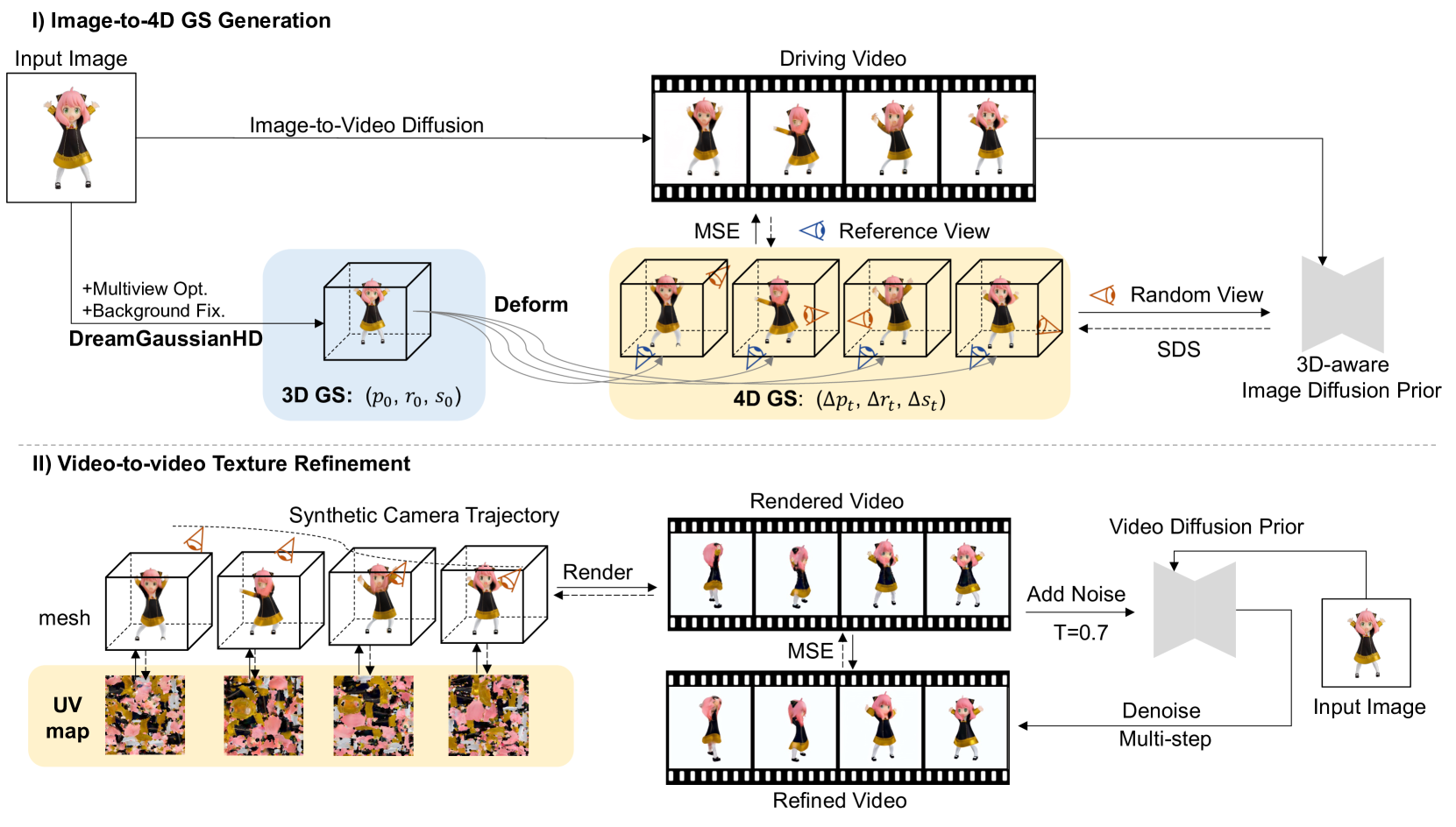
4D content generation has achieved remarkable progress recently. However, existing methods suffer from long optimization times, a lack of motion controllability, and a low quality of details. In this paper, we introduce DreamGaussian4D (DG4D), an efficient 4D generation framework that builds on Gaussian Splatting (GS). Our key insight is that combining explicit modeling of spatial transformations with static GS makes an efficient and powerful representation for 4D generation. Moreover, video generation methods have the potential to offer valuable spatial-temporal priors, enhancing the high-quality 4D generation. Specifically, we propose an integral framework with two major modules: 1) Image-to-4D GS - we initially generate static GS with DreamGaussianHD, followed by HexPlane-based dynamic generation with Gaussian deformation; and 2) Video-to-Video Texture Refinement - we refine the generated UV-space texture maps and meanwhile enhance their temporal consistency by utilizing a pre-trained image-to-video diffusion model. Notably, DG4D reduces the optimization time from several hours to just a few minutes, allows the generated 3D motion to be visually controlled, and produces animated meshes that can be realistically rendered in 3D engines.
6/11/2024
SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer
Zijie Wu, Chaohui Yu, Yanqin Jiang, Chenjie Cao, Fan Wang, Xiang Bai
0
0
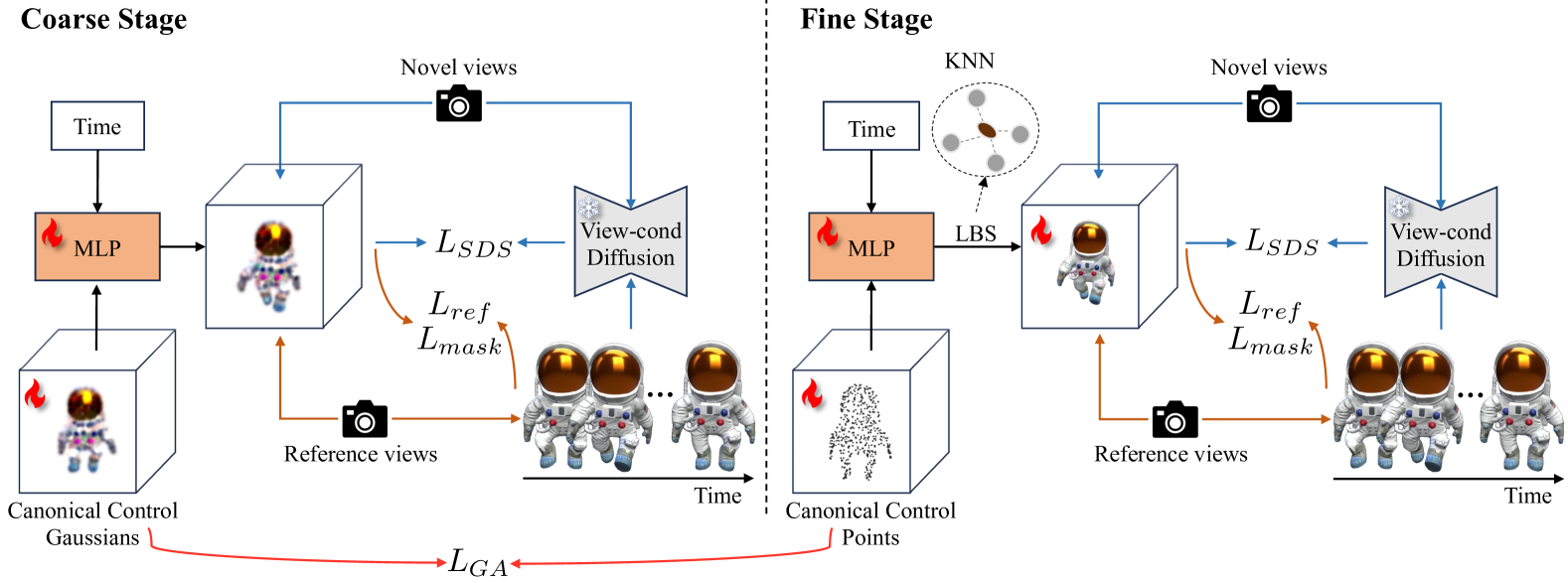
Recent advances in 2D/3D generative models enable the generation of dynamic 3D objects from a single-view video. Existing approaches utilize score distillation sampling to form the dynamic scene as dynamic NeRF or dense 3D Gaussians. However, these methods struggle to strike a balance among reference view alignment, spatio-temporal consistency, and motion fidelity under single-view conditions due to the implicit nature of NeRF or the intricate dense Gaussian motion prediction. To address these issues, this paper proposes an efficient, sparse-controlled video-to-4D framework named SC4D, that decouples motion and appearance to achieve superior video-to-4D generation. Moreover, we introduce Adaptive Gaussian (AG) initialization and Gaussian Alignment (GA) loss to mitigate shape degeneration issue, ensuring the fidelity of the learned motion and shape. Comprehensive experimental results demonstrate that our method surpasses existing methods in both quality and efficiency. In addition, facilitated by the disentangled modeling of motion and appearance of SC4D, we devise a novel application that seamlessly transfers the learned motion onto a diverse array of 4D entities according to textual descriptions.
4/8/2024

4Diffusion: Multi-view Video Diffusion Model for 4D Generation
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao
0
0
Current 4D generation methods have achieved noteworthy efficacy with the aid of advanced diffusion generative models. However, these methods lack multi-view spatial-temporal modeling and encounter challenges in integrating diverse prior knowledge from multiple diffusion models, resulting in inconsistent temporal appearance and flickers. In this paper, we propose a novel 4D generation pipeline, namely 4Diffusion aimed at generating spatial-temporally consistent 4D content from a monocular video. We first design a unified diffusion model tailored for multi-view video generation by incorporating a learnable motion module into a frozen 3D-aware diffusion model to capture multi-view spatial-temporal correlations. After training on a curated dataset, our diffusion model acquires reasonable temporal consistency and inherently preserves the generalizability and spatial consistency of the 3D-aware diffusion model. Subsequently, we propose 4D-aware Score Distillation Sampling loss, which is based on our multi-view video diffusion model, to optimize 4D representation parameterized by dynamic NeRF. This aims to eliminate discrepancies arising from multiple diffusion models, allowing for generating spatial-temporally consistent 4D content. Moreover, we devise an anchor loss to enhance the appearance details and facilitate the learning of dynamic NeRF. Extensive qualitative and quantitative experiments demonstrate that our method achieves superior performance compared to previous methods.
6/3/2024

Diffusion4D: Fast Spatial-temporal Consistent 4D Generation via Video Diffusion Models
Hanwen Liang, Yuyang Yin, Dejia Xu, Hanxue Liang, Zhangyang Wang, Konstantinos N. Plataniotis, Yao Zhao, Yunchao Wei
0
0
The availability of large-scale multimodal datasets and advancements in diffusion models have significantly accelerated progress in 4D content generation. Most prior approaches rely on multiple image or video diffusion models, utilizing score distillation sampling for optimization or generating pseudo novel views for direct supervision. However, these methods are hindered by slow optimization speeds and multi-view inconsistency issues. Spatial and temporal consistency in 4D geometry has been extensively explored respectively in 3D-aware diffusion models and traditional monocular video diffusion models. Building on this foundation, we propose a strategy to migrate the temporal consistency in video diffusion models to the spatial-temporal consistency required for 4D generation. Specifically, we present a novel framework, textbf{Diffusion4D}, for efficient and scalable 4D content generation. Leveraging a meticulously curated dynamic 3D dataset, we develop a 4D-aware video diffusion model capable of synthesizing orbital views of dynamic 3D assets. To control the dynamic strength of these assets, we introduce a 3D-to-4D motion magnitude metric as guidance. Additionally, we propose a novel motion magnitude reconstruction loss and 3D-aware classifier-free guidance to refine the learning and generation of motion dynamics. After obtaining orbital views of the 4D asset, we perform explicit 4D construction with Gaussian splatting in a coarse-to-fine manner. The synthesized multi-view consistent 4D image set enables us to swiftly generate high-fidelity and diverse 4D assets within just several minutes. Extensive experiments demonstrate that our method surpasses prior state-of-the-art techniques in terms of generation efficiency and 4D geometry consistency across various prompt modalities.
5/28/2024