Scalable Ensembling For Mitigating Reward Overoptimisation
2406.01013
0
0

Abstract
Reinforcement Learning from Human Feedback (RLHF) has enabled significant advancements within language modeling for powerful, instruction-following models. However, the alignment of these models remains a pressing challenge as the policy tends to overfit the learned proxy reward model past an inflection point of utility as measured by a gold reward model that is more performant -- a phenomenon known as overoptimisation. Prior work has mitigated this issue by computing a pessimistic statistic over an ensemble of reward models, which is common in Offline Reinforcement Learning but incredibly costly for language models with high memory requirements, making such approaches infeasible for sufficiently large models. To this end, we propose using a shared encoder but separate linear heads. We find this leads to similar performance as the full ensemble while allowing tremendous savings in memory and time required for training for models of similar size.
Create account to get full access
Overview
- This paper proposes a scalable ensembling method to mitigate reward overoptimization in reinforcement learning (RL) systems.
- Reward overoptimization occurs when an RL agent becomes overly focused on maximizing a specific reward signal, leading to unintended and potentially harmful behaviors.
- The authors' approach uses an ensemble of reward models to provide a more robust and diverse reward signal, helping to address this challenge.
Plain English Explanation
The paper focuses on a common problem in reinforcement learning called "reward overoptimization." This happens when an AI system becomes too focused on maximizing a specific reward signal, even if that means engaging in unintended or undesirable behaviors.
To address this, the authors suggest using an "ensemble" approach. An ensemble is a group of different models or systems that work together. In this case, the ensemble consists of multiple reward models that each provide a different perspective on what the AI system should be rewarded for.
By using this ensemble of reward models, the AI system is less likely to become fixated on a single, potentially flawed reward signal. Instead, it has to balance the various reward signals from the ensemble, leading to more well-rounded and beneficial behavior.
The key advantage of this approach is that it is "scalable," meaning it can be applied to large, complex AI systems without becoming unwieldy or impractical. This makes it a promising technique for helping to ensure that powerful AI systems remain aligned with human values and intentions, even as they become more capable.
Technical Explanation
The paper introduces a scalable ensembling method to mitigate reward overoptimization in reinforcement learning (RL) systems. Reward overoptimization occurs when an RL agent becomes overly focused on maximizing a specific reward signal, leading to unintended and potentially harmful behaviors.
The authors' approach uses an ensemble of reward models to provide a more robust and diverse reward signal to the RL agent. The ensemble is constructed by training multiple reward models, each with different architectures or training data, to capture a diverse set of reward signals.
During training, the RL agent must learn to balance the different reward signals from the ensemble, rather than fixating on a single reward. This helps to prevent the agent from becoming overly specialized and ensures that it learns a more well-rounded and beneficial policy.
The authors demonstrate the effectiveness of their approach through experiments on a range of benchmarks, including link to related paper: "Improving Reinforcement Learning from Human Feedback". They show that the ensemble-based method outperforms single-reward RL agents in terms of robustness and alignment with intended behaviors.
Critical Analysis
The authors present a promising approach to mitigating reward overoptimization, which is a critical challenge in the development of safe and reliable RL systems. The use of an ensemble of reward models is a clever and scalable solution, as it avoids the need to design a single, perfect reward function.
However, the paper does not address some potential limitations of the ensemble approach. For example, it's unclear how the ensemble is constructed and how the individual reward models are trained. There may be challenges in ensuring that the ensemble captures a truly diverse set of reward signals, especially if the training data or model architectures are not sufficiently varied.
Additionally, the paper does not discuss how the ensemble-based approach might perform in more complex, real-world environments where the reward structure is more ambiguous or difficult to define. It would be valuable to see further evaluation of the method in such settings, as this is where reward overoptimization is likely to be a greater concern.
Overall, the research presented in this paper is a valuable contribution to the field of link to related paper: "Online Merging of Optimizers for Boosting Rewards and Mitigating Tax" and link to related paper: "Leveraging Domain Knowledge for Efficient Reward Modelling in RLHF". The scalable ensembling approach offers a promising direction for further research and development in the area of link to related paper: "INFORM: Mitigating Reward Hacking in RLHF via Information" and link to related paper: "RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback".
Conclusion
The paper presents a scalable ensembling method for mitigating reward overoptimization in reinforcement learning systems. By using an ensemble of diverse reward models, the approach helps to prevent RL agents from becoming overly fixated on a single reward signal and engaging in unintended or harmful behaviors.
The authors demonstrate the effectiveness of their method through experiments on various benchmarks, showing that the ensemble-based approach outperforms single-reward RL agents in terms of robustness and alignment with intended behaviors.
While the paper highlights some important limitations that warrant further investigation, the proposed scalable ensembling technique represents a valuable contribution to the ongoing efforts to develop safe and reliable AI systems that reliably pursue intended goals and objectives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Improving Reinforcement Learning from Human Feedback with Efficient Reward Model Ensemble
Shun Zhang, Zhenfang Chen, Sunli Chen, Yikang Shen, Zhiqing Sun, Chuang Gan
0
0
Reinforcement Learning from Human Feedback (RLHF) is a widely adopted approach for aligning large language models with human values. However, RLHF relies on a reward model that is trained with a limited amount of human preference data, which could lead to inaccurate predictions. As a result, RLHF may produce outputs that are misaligned with human values. To mitigate this issue, we contribute a reward ensemble method that allows the reward model to make more accurate predictions. As using an ensemble of large language model-based reward models can be computationally and resource-expensive, we explore efficient ensemble methods including linear-layer ensemble and LoRA-based ensemble. Empirically, we run Best-of-$n$ and Proximal Policy Optimization with our ensembled reward models, and verify that our ensemble methods help improve the alignment performance of RLHF outputs.
5/24/2024

Scaling Laws for Reward Model Overoptimization in Direct Alignment Algorithms
Rafael Rafailov, Yaswanth Chittepu, Ryan Park, Harshit Sikchi, Joey Hejna, Bradley Knox, Chelsea Finn, Scott Niekum
0
0
Reinforcement Learning from Human Feedback (RLHF) has been crucial to the recent success of Large Language Models (LLMs), however, it is often a complex and brittle process. In the classical RLHF framework, a reward model is first trained to represent human preferences, which is in turn used by an online reinforcement learning (RL) algorithm to optimize the LLM. A prominent issue with such methods is emph{reward over-optimization} or emph{reward hacking}, where performance as measured by the learned proxy reward model increases, but true quality plateaus or even deteriorates. Direct Alignment Algorithms (DDAs) like Direct Preference Optimization have emerged as alternatives to the classical RLHF pipeline by circumventing the reward modeling phase. However, although DAAs do not use a separate proxy reward model, they still commonly deteriorate from over-optimization. While the so-called reward hacking phenomenon is not well-defined for DAAs, we still uncover similar trends: at higher KL budgets, DAA algorithms exhibit similar degradation patterns to their classic RLHF counterparts. In particular, we find that DAA methods deteriorate not only across a wide range of KL budgets but also often before even a single epoch of the dataset is completed. Through extensive empirical experimentation, this work formulates and formalizes the reward over-optimization or hacking problem for DAAs and explores its consequences across objectives, training regimes, and model scales.
6/6/2024
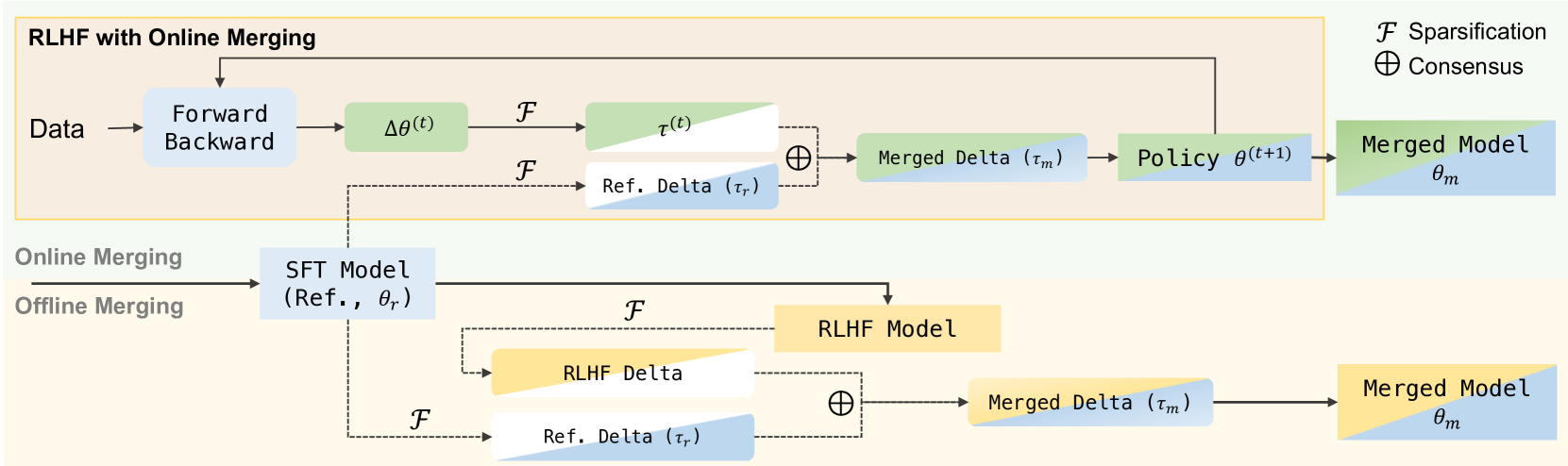
Online Merging Optimizers for Boosting Rewards and Mitigating Tax in Alignment
Keming Lu, Bowen Yu, Fei Huang, Yang Fan, Runji Lin, Chang Zhou
0
0
Effectively aligning Large Language Models (LLMs) with human-centric values while preventing the degradation of abilities acquired through Pre-training and Supervised Fine-tuning (SFT) poses a central challenge in Reinforcement Learning from Human Feedback (RLHF). In this paper, we first discover that interpolating RLHF and SFT model parameters can adjust the trade-off between human preference and basic capabilities, thereby reducing the alignment tax at the cost of alignment reward. Inspired by this, we propose integrating the RL policy and SFT models at each optimization step in RLHF to continuously regulate the training direction, introducing the Online Merging Optimizer. Specifically, we merge gradients with the parameter differences between SFT and pretrained models, effectively steering the gradient towards maximizing rewards in the direction of SFT optimization. We demonstrate that our optimizer works well with different LLM families, such as Qwen and LLaMA, across various model sizes ranging from 1.8B to 8B, various RLHF algorithms like DPO and KTO, and existing model merging methods. It significantly enhances alignment reward while mitigating alignment tax, achieving higher overall performance across 14 benchmarks.
5/29/2024

Regularizing Hidden States Enables Learning Generalizable Reward Model for LLMs
Rui Yang, Ruomeng Ding, Yong Lin, Huan Zhang, Tong Zhang
0
0
Reward models trained on human preference data have been proven to be effective for aligning Large Language Models (LLMs) with human intent within the reinforcement learning from human feedback (RLHF) framework. However, the generalization capabilities of current reward models to unseen prompts and responses are limited. This limitation can lead to an unexpected phenomenon known as reward over-optimization, where excessive optimization of rewards results in a decline in actual performance. While previous research has advocated for constraining policy optimization, our study proposes a novel approach to enhance the reward model's generalization ability against distribution shifts by regularizing the hidden states. Specifically, we retain the base model's language model head and incorporate a suite of text-generation losses to preserve the hidden states' text generation capabilities, while concurrently learning a reward head behind the same hidden states. Our experimental results demonstrate that the introduced regularization technique markedly improves the accuracy of learned reward models across a variety of out-of-distribution (OOD) tasks and effectively alleviate the over-optimization issue in RLHF, offering a more reliable and robust preference learning paradigm.
6/17/2024