SCALE: Self-regulated Clustered federAted LEarning in a Homogeneous Environment

0

Sign in to get full access
Overview
- The paper introduces SCALE, a self-regulated clustered federated learning approach for a homogeneous environment.
- It aims to address the challenges of data heterogeneity in federated learning by forming dynamic client clusters based on model similarity.
- SCALE regulates the training process and selects the most representative clients within each cluster to participate in the global model update.
Plain English Explanation
SCALE: Self-regulated Clustered federAted LEarning in a Homogeneous Environment proposes a new approach to federated learning, which is a way of training machine learning models across multiple devices without centralizing the data.
In traditional federated learning, the devices (called "clients") each have their own data, and they work together to train a shared model. However, the data on each device can be quite different, which can make it challenging to train an effective model.
To address this, the researchers developed SCALE, which stands for "Self-regulated Clustered federAted LEarning." The key idea behind SCALE is to group the clients into "clusters" based on the similarity of their models. This allows the system to tailor the training process to each cluster, rather than treating all the clients the same way.
SCALE also includes a "self-regulation" mechanism, which means the system can dynamically adjust the number of clients that participate in the global model update based on factors like model convergence and client similarity. This helps to ensure that the most relevant and representative clients are contributing to the final model.
By using this clustered and self-regulated approach, SCALE aims to improve the performance of federated learning, especially in situations where the client data is quite homogeneous (i.e., similar).
Technical Explanation
The SCALE approach works as follows:
-
Client Clustering: SCALE groups the clients into dynamic clusters based on the similarity of their local model parameters. This is done using a clustering algorithm that considers both the model parameters and the data distribution on each client.
-
Cluster-specific Training: Within each cluster, SCALE tailors the training process to the specific characteristics of that cluster. This includes adjusting hyperparameters, the number of local training steps, and the client selection strategy.
-
Self-Regulation: SCALE includes a self-regulation mechanism that determines the optimal number of clients to participate in the global model update. This is based on factors like model convergence and client similarity within each cluster.
-
Cluster-based Aggregation: When updating the global model, SCALE gives more weight to the updates from the most representative clients within each cluster, rather than treating all clients equally.
The researchers evaluated SCALE on several benchmark federated learning datasets and found that it outperformed traditional federated learning approaches, especially in scenarios with more homogeneous client data. SCALE was able to achieve higher model accuracy while using fewer client updates, demonstrating its efficiency and effectiveness.
Critical Analysis
The SCALE paper presents a promising approach to addressing the data heterogeneity challenges in federated learning. By dynamically clustering clients and tailoring the training process accordingly, SCALE seems to offer significant improvements over standard federated learning methods.
One potential limitation of the SCALE approach is that it may be sensitive to the initial client clustering, which could impact the overall performance. The researchers mention that they use a clustering algorithm that considers both model parameters and data distribution, but it would be interesting to see how SCALE performs with different clustering techniques or initializations.
Additionally, the paper focuses on a homogeneous environment, where the client data is relatively similar. It would be valuable to explore how SCALE might perform in more heterogeneous settings, where the client data is more diverse. The researchers acknowledge this as an area for future work.
Another aspect that could be further investigated is the interpretability and explainability of the SCALE approach. Understanding the reasons behind the client clustering and the self-regulation decisions could provide valuable insights and help build trust in the system.
Overall, the SCALE paper presents a compelling and well-designed federated learning approach that demonstrates the potential benefits of leveraging client similarity and self-regulation. Further research and real-world deployments could help validate the broader applicability and practical implications of this work.
Conclusion
The SCALE paper introduces a novel federated learning approach that addresses the challenge of data heterogeneity by dynamically clustering clients based on model similarity and self-regulating the training process. By tailoring the learning to each client cluster, SCALE achieves better model performance while using fewer client updates, making it a promising solution for federated learning in homogeneous environments.
The paper's technical contributions, such as the client clustering algorithm and the self-regulation mechanism, demonstrate the potential of incorporating client-specific characteristics into the federated learning framework. While the current focus is on homogeneous settings, exploring SCALE's performance in more diverse data environments could further expand its applicability and impact in the field of federated learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SCALE: Self-regulated Clustered federAted LEarning in a Homogeneous Environment
Sai Puppala, Ismail Hossain, Md Jahangir Alam, Sajedul Talukder, Zahidur Talukder, Syed Bahauddin
Federated Learning (FL) has emerged as a transformative approach for enabling distributed machine learning while preserving user privacy, yet it faces challenges like communication inefficiencies and reliance on centralized infrastructures, leading to increased latency and costs. This paper presents a novel FL methodology that overcomes these limitations by eliminating the dependency on edge servers, employing a server-assisted Proximity Evaluation for dynamic cluster formation based on data similarity, performance indices, and geographical proximity. Our integrated approach enhances operational efficiency and scalability through a Hybrid Decentralized Aggregation Protocol, which merges local model training with peer-to-peer weight exchange and a centralized final aggregation managed by a dynamically elected driver node, significantly curtailing global communication overhead. Additionally, the methodology includes Decentralized Driver Selection, Check-pointing to reduce network traffic, and a Health Status Verification Mechanism for system robustness. Validated using the breast cancer dataset, our architecture not only demonstrates a nearly tenfold reduction in communication overhead but also shows remarkable improvements in reducing training latency and energy consumption while maintaining high learning performance, offering a scalable, efficient, and privacy-preserving solution for the future of federated learning ecosystems.
Read more7/29/2024

0
Proximity-based Self-Federated Learning
Davide Domini, Gianluca Aguzzi, Nicolas Farabegoli, Mirko Viroli, Lukas Esterle
In recent advancements in machine learning, federated learning allows a network of distributed clients to collaboratively develop a global model without needing to share their local data. This technique aims to safeguard privacy, countering the vulnerabilities of conventional centralized learning methods. Traditional federated learning approaches often rely on a central server to coordinate model training across clients, aiming to replicate the same model uniformly across all nodes. However, these methods overlook the significance of geographical and local data variances in vast networks, potentially affecting model effectiveness and applicability. Moreover, relying on a central server might become a bottleneck in large networks, such as the ones promoted by edge computing. Our paper introduces a novel, fully-distributed federated learning strategy called proximity-based self-federated learning that enables the self-organised creation of multiple federations of clients based on their geographic proximity and data distribution without exchanging raw data. Indeed, unlike traditional algorithms, our approach encourages clients to share and adjust their models with neighbouring nodes based on geographic proximity and model accuracy. This method not only addresses the limitations posed by diverse data distributions but also enhances the model's adaptability to different regional characteristics creating specialized models for each federation. We demonstrate the efficacy of our approach through simulations on well-known datasets, showcasing its effectiveness over the conventional centralized federated learning framework.
Read more7/18/2024
0
Decentralized Personalized Federated Learning
Salma Kharrat, Marco Canini, Samuel Horvath
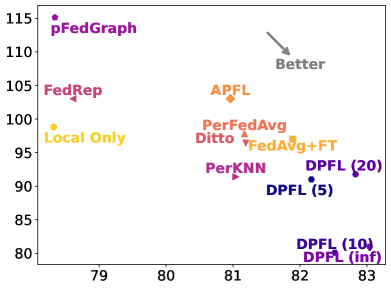
This work tackles the challenges of data heterogeneity and communication limitations in decentralized federated learning. We focus on creating a collaboration graph that guides each client in selecting suitable collaborators for training personalized models that leverage their local data effectively. Our approach addresses these issues through a novel, communication-efficient strategy that enhances resource efficiency. Unlike traditional methods, our formulation identifies collaborators at a granular level by considering combinatorial relations of clients, enhancing personalization while minimizing communication overhead. We achieve this through a bi-level optimization framework that employs a constrained greedy algorithm, resulting in a resource-efficient collaboration graph for personalized learning. Extensive evaluation against various baselines across diverse datasets demonstrates the superiority of our method, named DPFL. DPFL consistently outperforms other approaches, showcasing its effectiveness in handling real-world data heterogeneity, minimizing communication overhead, enhancing resource efficiency, and building personalized models in decentralized federated learning scenarios.
Read more6/11/2024

0
FedClust: Tackling Data Heterogeneity in Federated Learning through Weight-Driven Client Clustering
Md Sirajul Islam, Simin Javaherian, Fei Xu, Xu Yuan, Li Chen, Nian-Feng Tzeng
Federated learning (FL) is an emerging distributed machine learning paradigm that enables collaborative training of machine learning models over decentralized devices without exposing their local data. One of the major challenges in FL is the presence of uneven data distributions across client devices, violating the well-known assumption of independent-and-identically-distributed (IID) training samples in conventional machine learning. To address the performance degradation issue incurred by such data heterogeneity, clustered federated learning (CFL) shows its promise by grouping clients into separate learning clusters based on the similarity of their local data distributions. However, state-of-the-art CFL approaches require a large number of communication rounds to learn the distribution similarities during training until the formation of clusters is stabilized. Moreover, some of these algorithms heavily rely on a predefined number of clusters, thus limiting their flexibility and adaptability. In this paper, we propose {em FedClust}, a novel approach for CFL that leverages the correlation between local model weights and the data distribution of clients. {em FedClust} groups clients into clusters in a one-shot manner by measuring the similarity degrees among clients based on the strategically selected partial weights of locally trained models. We conduct extensive experiments on four benchmark datasets with different non-IID data settings. Experimental results demonstrate that {em FedClust} achieves higher model accuracy up to $sim$45% as well as faster convergence with a significantly reduced communication cost up to 2.7$times$ compared to its state-of-the-art counterparts.
Read more7/11/2024