Scaling Analog Photonic Accelerators for Byte-Size, Integer General Matrix Multiply (GEMM) Kernels

0

Sign in to get full access
Overview
- This paper explores scaling analog photonic accelerators for efficient integer general matrix multiplication (GEMM) operations.
- The authors present a novel "byte-size" GEMM kernel design that leverages the unique properties of analog photonic hardware to achieve high performance and energy efficiency.
- The proposed approach introduces techniques like bit slicing and dataflow selection to address the challenges of scaling analog photonic accelerators.
Plain English Explanation
The paper describes a new way to use photonic hardware, which is technology that uses light instead of electricity, to perform a common computer operation called matrix multiplication. Matrix multiplication is a fundamental building block for many AI and machine learning algorithms, and it's important to find efficient ways to do it.
The key innovation is a "byte-size" design that breaks down the matrix multiplication into smaller, more manageable pieces. This allows the photonic hardware to handle the computation more efficiently, using less power and space. The authors also introduce some special techniques, like bit slicing and dataflow selection, to further optimize the performance of the photonic accelerator.
The goal is to create photonic hardware that can perform matrix multiplication faster and more energy-efficiently than traditional electronic processors, especially for the types of integer-based calculations commonly used in AI and machine learning. This could lead to more powerful and energy-efficient AI systems in the future.
Technical Explanation
The paper presents a novel approach to scaling analog photonic accelerators for efficient integer general matrix multiplication (GEMM) kernels. The authors' key contributions include:
-
A "byte-size" GEMM kernel design that exploits the unique properties of analog photonic hardware to achieve high performance and energy efficiency. This involves breaking down the matrix multiplication into smaller, more manageable "byte-size" chunks.
-
The introduction of bit slicing and dataflow selection techniques to address the challenges of scaling analog photonic accelerators.
-
An architecture-level modeling approach to evaluate the performance and energy efficiency of the proposed byte-size GEMM kernel on a photonic accelerator platform.
The authors demonstrate the effectiveness of their approach through extensive simulations and comparisons to state-of-the-art electronic and photonic GEMM accelerators. The results show that the proposed byte-size GEMM kernel can achieve significant improvements in terms of performance, energy efficiency, and scalability compared to existing solutions.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach to scaling analog photonic accelerators for efficient integer GEMM operations. The authors have carefully addressed the key challenges in this domain, such as the difficulties of scaling analog photonic hardware and the need for efficient dataflow management.
One potential limitation of the work is the reliance on simulation-based evaluation. While the authors have used detailed architecture-level modeling, it would be valuable to see experimental validation of the proposed techniques on a real photonic hardware platform. Additionally, the paper does not explore the integration of the byte-size GEMM kernel with larger AI/ML systems, which could uncover additional challenges and tradeoffs.
Further research could also investigate the applicability of the byte-size GEMM kernel and associated techniques to other types of matrix operations, such as sparse matrix multiplication, which is crucial for efficient graph computing. Exploring the interplay between the byte-size GEMM kernel and high-level dataflow selection algorithms could also lead to further improvements in performance and energy efficiency.
Conclusion
This paper presents a novel approach to scaling analog photonic accelerators for efficient integer GEMM operations, a crucial building block for many AI and machine learning applications. The proposed byte-size GEMM kernel design, coupled with techniques like bit slicing and dataflow selection, demonstrates significant performance and energy efficiency improvements compared to existing solutions.
The work highlights the potential of photonic hardware to revolutionize the field of AI/ML acceleration, particularly for integer-based computations. As the research in this area continues to evolve, we can expect to see even more advancements in the development of highly efficient and scalable photonic accelerators that can power the next generation of intelligent systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Scaling Analog Photonic Accelerators for Byte-Size, Integer General Matrix Multiply (GEMM) Kernels
Oluwaseun Adewunmi Alo, Sairam Sri Vatsavai, Ishan Thakkar
Deep Neural Networks (DNNs) predominantly rely on General Matrix Multiply (GEMM) kernels, which are often accelerated using specialized hardware architectures. Recently, analog photonic GEMM accelerators have emerged as a promising alternative, offering vastly superior speed and energy efficiency compared to traditional electronic accelerators. However, these photonic cannot support wider than 4-bit integer operands due to their inherent trade-offs between analog dynamic range and parallelism. This is often inadequate for DNN training as at least 8-bit wide operands are deemed necessary to prevent significant accuracy drops. To address these limitations, we introduce a scalable photonic GEMM accelerator named SPOGA. SPOGA utilizes enhanced features such as analog summation of homodyne optical signals and in-transduction positional weighting of operands. By employing an extended optical-analog dataflow that minimizes overheads associated with bit-sliced integer arithmetic, SPOGA supports byte-size integer GEMM kernels, achieving significant improvements in throughput, latency, and energy efficiency. Specifically, SPOGA demonstrates up to 14.4$times$, 2$times$, and 28.5$times$ improvements in frames-per-second (FPS), FPS/Watt, and FPS/Watt/mm$^2$ respectively, compared to existing state-of-the-art photonic solutions.
Read more7/9/2024
0
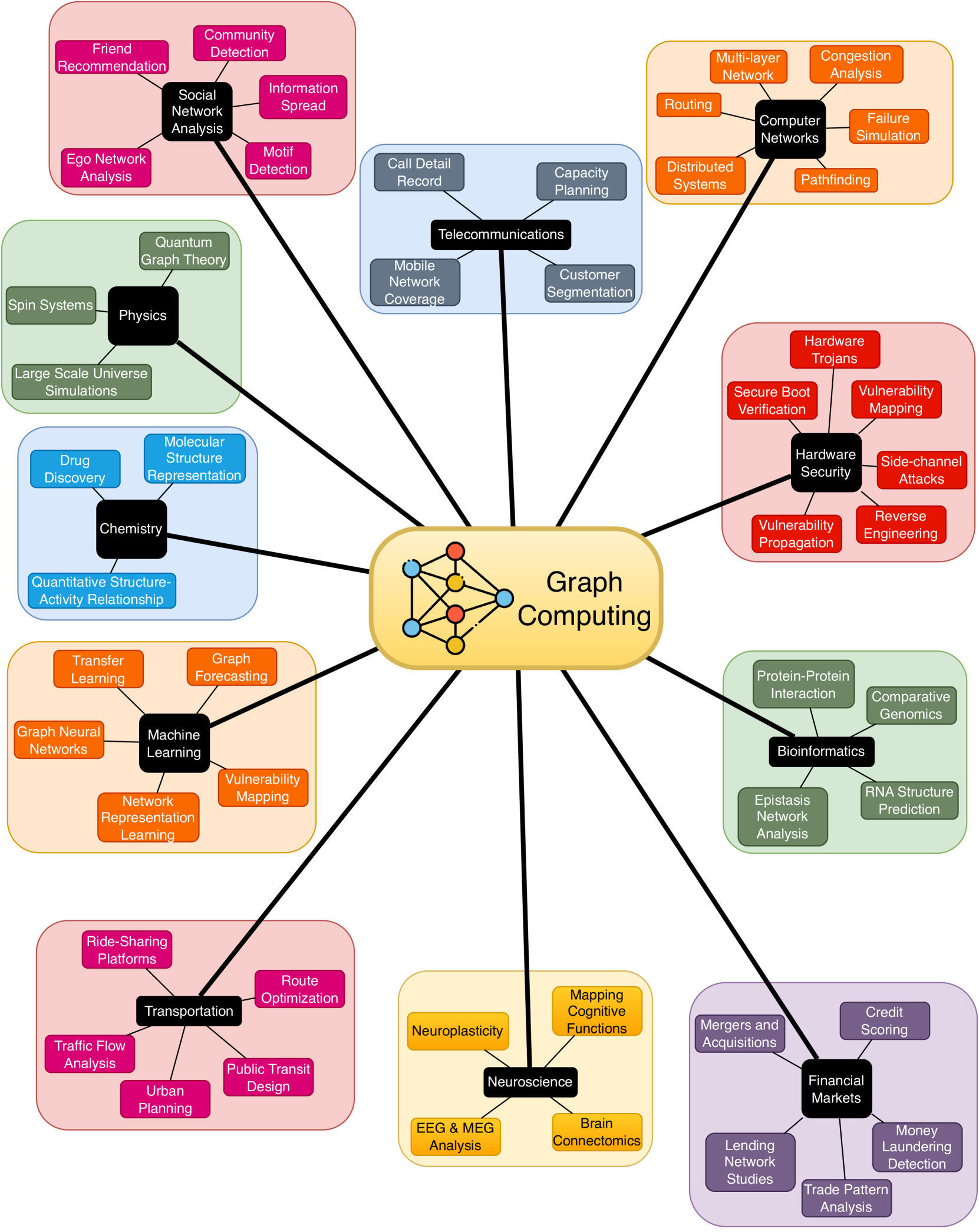
Enabling Accelerators for Graph Computing
Kaustubh Shivdikar
The advent of Graph Neural Networks (GNNs) has revolutionized the field of machine learning, offering a novel paradigm for learning on graph-structured data. Unlike traditional neural networks, GNNs are capable of capturing complex relationships and dependencies inherent in graph data, making them particularly suited for a wide range of applications including social network analysis, molecular chemistry, and network security. GNNs, with their unique structure and operation, present new computational challenges compared to conventional neural networks. This requires comprehensive benchmarking and a thorough characterization of GNNs to obtain insight into their computational requirements and to identify potential performance bottlenecks. In this thesis, we aim to develop a better understanding of how GNNs interact with the underlying hardware and will leverage this knowledge as we design specialized accelerators and develop new optimizations, leading to more efficient and faster GNN computations. A pivotal component within GNNs is the Sparse General Matrix-Matrix Multiplication (SpGEMM) kernel, known for its computational intensity and irregular memory access patterns. In this thesis, we address the challenges posed by SpGEMM by implementing a highly optimized hashing-based SpGEMM kernel tailored for a custom accelerator. Synthesizing these insights and optimizations, we design state-of-the-art hardware accelerators capable of efficiently handling various GNN workloads. Our accelerator architectures are built on our characterization of GNN computational demands, providing clear motivation for our approaches. This exploration into novel models underlines our comprehensive approach, as we strive to enable accelerators that are not just performant, but also versatile, able to adapt to the evolving landscape of graph computing.
Read more5/7/2024

0
SCATTER: Algorithm-Circuit Co-Sparse Photonic Accelerator with Thermal-Tolerant, Power-Efficient In-situ Light Redistribution
Ziang Yin, Nicholas Gangi, Meng Zhang, Jeff Zhang, Rena Huang, Jiaqi Gu
Photonic computing has emerged as a promising solution for accelerating computation-intensive artificial intelligence (AI) workloads. However, limited reconfigurability, high electrical-optical conversion cost, and thermal sensitivity limit the deployment of current optical analog computing engines to support power-restricted, performance-sensitive AI workloads at scale. Sparsity provides a great opportunity for hardware-efficient AI accelerators. However, current dense photonic accelerators fail to fully exploit the power-saving potential of algorithmic sparsity. It requires sparsity-aware hardware specialization with a fundamental re-design of photonic tensor core topology and cross-layer device-circuit-architecture-algorithm co-optimization aware of hardware non-ideality and power bottleneck. To trim down the redundant power consumption while maximizing robustness to thermal variations, we propose SCATTER, a novel algorithm-circuit co-sparse photonic accelerator featuring dynamically reconfigurable signal path via thermal-tolerant, power-efficient in-situ light redistribution and power gating. A power-optimized, crosstalk-aware dynamic sparse training framework is introduced to explore row-column structured sparsity and ensure marginal accuracy loss and maximum power efficiency. The extensive evaluation shows that our cross-stacked optimized accelerator SCATTER achieves a 511X area reduction and 12.4X power saving with superior crosstalk tolerance that enables unprecedented circuit layout compactness and on-chip power efficiency.
Read more7/9/2024
🤿
0
Architecture-Level Modeling of Photonic Deep Neural Network Accelerators
Tanner Andrulis, Gohar Irfan Chaudhry, Vinith M. Suriyakumar, Joel S. Emer, Vivienne Sze
Photonics is a promising technology to accelerate Deep Neural Networks as it can use optical interconnects to reduce data movement energy and it enables low-energy, high-throughput optical-analog computations. To realize these benefits in a full system (accelerator + DRAM), designers must ensure that the benefits of using the electrical, optical, analog, and digital domains exceed the costs of converting data between domains. Designers must also consider system-level energy costs such as data fetch from DRAM. Converting data and accessing DRAM can consume significant energy, so to evaluate and explore the photonic system space, there is a need for a tool that can model these full-system considerations. In this work, we show that similarities between Compute-in-Memory (CiM) and photonics let us use CiM system modeling tools to accurately model photonics systems. Bringing modeling tools to photonics enables evaluation of photonic research in a full-system context, rapid design space exploration, co-design, and comparison between systems. Using our open-source model, we show that cross-domain conversion and DRAM can consume a significant portion of photonic system energy. We then demonstrate optimizations that reduce conversions and DRAM accesses to improve photonic system energy efficiency by up to 3x.
Read more5/15/2024