Scaling Synthetic Logical Reasoning Datasets with Context-Sensitive Declarative Grammars
2406.11035
0
0
🧪
Abstract
Logical reasoning remains a challenge for natural language processing, but it can be improved by training language models to mimic theorem provers on procedurally generated problems. Previous work used domain-specific proof generation algorithms, which biases reasoning toward specific proof traces and limits auditability and extensibility. We present a simpler and more general declarative framework with flexible context-sensitive rules binding multiple languages (specifically, simplified English and the TPTP theorem-proving language). We construct first-order logic problems by selecting up to 32 premises and one hypothesis. We demonstrate that using semantic constraints during generation and careful English verbalization of predicates enhances logical reasoning without hurting natural English tasks. We use relatively small DeBERTa-v3 models to achieve state-of-the-art accuracy on the FOLIO human-authored logic dataset, surpassing GPT-4 in accuracy with or without an external solver by 12%.
Create account to get full access
Overview
- Researchers explore how to improve logical reasoning in natural language processing by training language models to mimic theorem provers on procedurally generated problems.
- Previous approaches used domain-specific proof generation algorithms, which limited their flexibility and auditability.
- This paper presents a more general declarative framework with flexible context-sensitive rules binding multiple languages, including simplified English and the TPTP theorem-proving language.
- The authors demonstrate that using semantic constraints during generation and careful English verbalization of predicates can enhance logical reasoning without hurting performance on natural English tasks.
Plain English Explanation
Logical reasoning is a fundamental challenge for natural language processing (NLP) systems, but researchers have found a way to improve it. They trained language models to mimic the way theorem provers solve logical problems that were automatically generated.
Previous approaches used specialized algorithms to generate the logical problems, which made the reasoning biased towards specific proof patterns. This also limited how well the systems could be audited and expanded.
The researchers in this paper took a simpler and more general approach. They created a flexible framework that uses context-sensitive rules to translate between simplified English and a formal theorem-proving language. This allows the language models to reason about logic in a more versatile and transparent way.
The team constructed logic problems by selecting up to 32 premises and one hypothesis. They found that using semantic constraints during problem generation and carefully translating the English predicates into formal language helped the models reason more logically without hurting their performance on natural language tasks.
Remarkably, the researchers were able to achieve state-of-the-art accuracy on a human-authored logic dataset using relatively small language models, surpassing even the powerful GPT-4 model. This suggests their approach is an effective way to improve logical reasoning in large language models.
Technical Explanation
The paper presents a new declarative framework for training natural language processing (NLP) models to improve their logical reasoning abilities. Previous work relied on domain-specific proof generation algorithms, which biased the reasoning towards particular proof traces and limited the flexibility and auditability of the systems.
In contrast, the authors introduce a more general approach that uses context-sensitive rules to bind multiple languages, including simplified English and the TPTP theorem-proving language. This allows for greater versatility and transparency in the reasoning process.
The researchers constructed first-order logic problems by selecting up to 32 premises and one hypothesis. They found that using semantic constraints during the generation process and carefully verbalizing the predicates in natural English enhanced the models' logical reasoning without hurting their performance on standard natural language tasks.
Experiments on the FOLIO human-authored logic dataset showed that relatively small DeBERTa-v3 models were able to achieve state-of-the-art accuracy, surpassing the powerful GPT-4 model in both accuracy with and without an external solver. This suggests the proposed framework is an effective way to improve the logical reasoning abilities of large language models.
Critical Analysis
The paper presents a promising approach for enhancing logical reasoning in natural language processing, but it also acknowledges several limitations and areas for further research.
One potential concern is the reliance on carefully crafted English verbalization of the predicates, which may not generalize well to more natural or diverse language usage. The authors note that further work is needed to improve the flexibility and robustness of the natural language interface.
Additionally, the experiments were conducted on a relatively small dataset of human-authored logic problems. While the results are impressive, it would be valuable to see how the framework performs on larger and more diverse benchmarks to better assess its broader applicability.
Another area for exploration is the integration of the declarative reasoning framework with other aspects of language understanding, such as commonsense reasoning and grounded world knowledge. Combining these capabilities could lead to more holistic and effective logical reasoning in NLP systems.
Overall, the paper presents a thoughtful and innovative approach to a critical challenge in the field of natural language processing. The researchers have demonstrated the potential of their framework, and further advancements in this direction could significantly enhance the logical reasoning abilities of large language models.
Conclusion
This paper introduces a novel declarative framework for training natural language processing models to improve their logical reasoning abilities. By using flexible context-sensitive rules to bind multiple languages, including simplified English and formal theorem-proving syntax, the researchers were able to achieve state-of-the-art accuracy on a human-authored logic dataset.
The key insights from this work suggest that enhancing semantic constraints and careful verbalization of logical predicates can enhance reasoning without compromising performance on standard natural language tasks. This approach represents a promising step forward in the ongoing effort to develop more robust and capable language AI systems.
As the field of natural language processing continues to evolve, the techniques and insights presented in this paper could have far-reaching implications for a wide range of applications, from intelligent assistants and question-answering systems to automated reasoning and decision-support tools. By improving the logical reasoning abilities of language models, we can unlock new possibilities for AI to engage in more nuanced, contextual, and reliable communication with humans.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Transformers in the Service of Description Logic-based Contexts
Angelos Poulis, Eleni Tsalapati, Manolis Koubarakis
0
0
Recent advancements in transformer-based models have initiated research interests in investigating their ability to learn to perform reasoning tasks. However, most of the contexts used for this purpose are in practice very simple: generated from short (fragments of) first-order logic sentences with only a few logical operators and quantifiers. In this work, we construct the natural language dataset, DELTA$_D$, using the description logic language $mathcal{ALCQ}$. DELTA$_D$ contains 384K examples, and increases in two dimensions: i) reasoning depth, and ii) linguistic complexity. In this way, we systematically investigate the reasoning ability of a supervised fine-tuned DeBERTa-based model and of two large language models (GPT-3.5, GPT-4) with few-shot prompting. Our results demonstrate that the DeBERTa-based model can master the reasoning task and that the performance of GPTs can improve significantly even when a small number of samples is provided (9 shots). We open-source our code and datasets.
4/29/2024

Disentangling Logic: The Role of Context in Large Language Model Reasoning Capabilities
Wenyue Hua, Kaijie Zhu, Lingyao Li, Lizhou Fan, Shuhang Lin, Mingyu Jin, Haochen Xue, Zelong Li, JinDong Wang, Yongfeng Zhang
0
0
This study intends to systematically disentangle pure logic reasoning and text understanding by investigating the contrast across abstract and contextualized logical problems from a comprehensive set of domains. We explore whether LLMs demonstrate genuine reasoning capabilities across various domains when the underlying logical structure remains constant. We focus on two main questions (1) Can abstract logical problems alone accurately benchmark an LLM's reasoning ability in real-world scenarios, disentangled from contextual support in practical settings? (2) Does fine-tuning LLMs on abstract logic problem generalize to contextualized logic problems and vice versa? To investigate these questions, we focus on standard propositional logic, specifically propositional deductive and abductive logic reasoning. In particular, we construct instantiated datasets for deductive and abductive reasoning with 4 levels of difficulty, encompassing 12 distinct categories or domains based on the categorization of Wikipedia. Our experiments aim to provide insights into disentangling context in logical reasoning and the true reasoning capabilities of LLMs and their generalization potential. The code and dataset are available at: https://github.com/agiresearch/ContextHub.
6/6/2024
LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, Chitta Baral
0
0
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really reason over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
6/7/2024
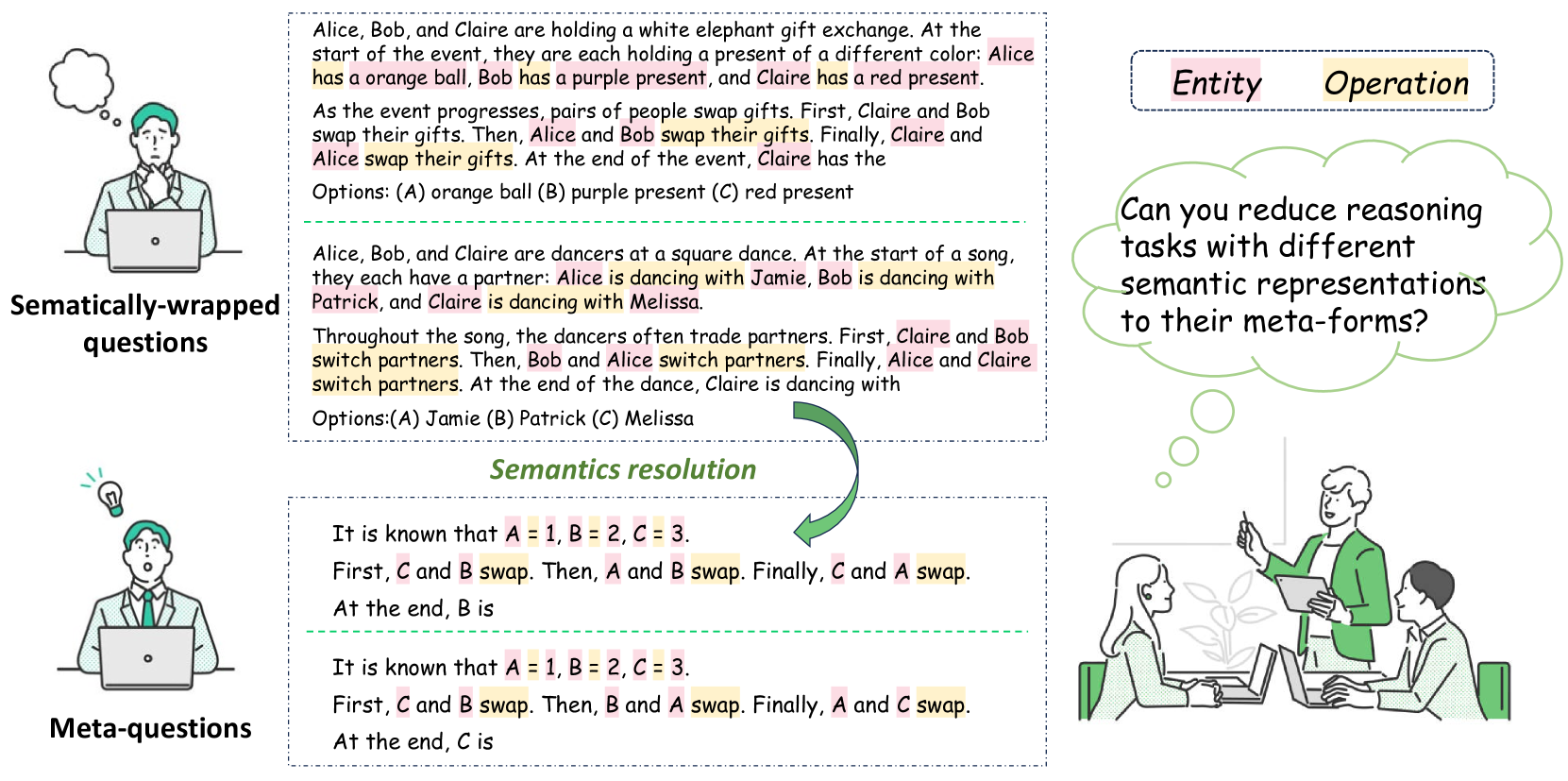
Meta-Reasoning: Semantics-Symbol Deconstruction for Large Language Models
Yiming Wang, Zhuosheng Zhang, Pei Zhang, Baosong Yang, Rui Wang
0
0
Neural-symbolic methods have demonstrated efficiency in enhancing the reasoning abilities of large language models (LLMs). However, existing methods mainly rely on syntactically mapping natural languages to complete formal languages like Python and SQL. Those methods require that reasoning tasks be convertible into programs, which cater to the computer execution mindset and deviate from human reasoning habits. To broaden symbolic methods' applicability and adaptability in the real world, we propose the Meta-Reasoning from a linguistic perspective. This method empowers LLMs to deconstruct reasoning-independent semantic information into generic symbolic representations, thereby efficiently capturing more generalized reasoning knowledge. We conduct extensive experiments on more than ten datasets encompassing conventional reasoning tasks like arithmetic, symbolic, and logical reasoning, and the more complex interactive reasoning tasks like theory-of-mind reasoning. Experimental results demonstrate that Meta-Reasoning significantly enhances in-context reasoning accuracy, learning efficiency, out-of-domain generalization, and output stability compared to the Chain-of-Thought technique. Code and data are publicly available at url{https://github.com/Alsace08/Meta-Reasoning}.
6/4/2024