LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
2404.15522
0
0
Abstract
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really reason over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
Create account to get full access
Overview
- This paper proposes a systematic approach to evaluating the logical reasoning abilities of large language models (LLMs).
- The authors argue that existing evaluation methods often focus on narrow tasks or lack comprehensive coverage of logical reasoning skills.
- The paper introduces a new evaluation framework that assesses LLMs' deductive reasoning capabilities across a diverse set of logical concepts and reasoning patterns.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, their ability to reason logically has been a topic of interest and debate. This paper aims to address this by proposing a more comprehensive way to evaluate the logical reasoning skills of LLMs.
The authors believe that existing evaluation methods often focus on specific tasks or only cover a limited set of logical reasoning abilities. To address this, they have developed a new framework that assesses LLMs' deductive reasoning skills across a wide range of logical concepts and reasoning patterns.
This framework is designed to provide a more thorough and systematic understanding of LLMs' logical reasoning capabilities. By testing their performance on a diverse set of logical reasoning tasks, the researchers hope to gain valuable insights into the strengths and weaknesses of these models when it comes to logical thinking.
The findings from this evaluation could help researchers and developers better understand the capabilities and limitations of LLMs, and guide the development of more advanced models with stronger logical reasoning abilities. This could have important implications for applications that require robust logical reasoning, such as tasks that involve complex decision-making or critical reasoning.
Technical Explanation
The paper introduces a new evaluation framework for assessing the logical reasoning abilities of large language models (LLMs). The framework consists of a diverse set of logical reasoning tasks that cover various concepts and reasoning patterns, such as propositional logic, quantification, and conditional reasoning.
The authors argue that existing evaluation methods often focus on narrow tasks or lack comprehensive coverage of logical reasoning skills. To address this, they have designed a suite of logical reasoning problems that challenge LLMs in different ways, such as requiring them to make inferences, identify logical fallacies, and apply formal rules of logic.
The evaluation framework is implemented as a benchmark, which the authors use to assess the performance of several state-of-the-art LLMs, including GPT-3, InstructGPT, and Megatron-LLM. The results of their experiments reveal both the strengths and limitations of these models when it comes to logical reasoning, providing insights into the types of reasoning patterns they excel at and struggle with.
The paper also discusses the potential implications of their findings for the development of more advanced LLMs with stronger logical reasoning capabilities. The authors suggest that the proposed evaluation framework could serve as a valuable tool for researchers and developers to systematically assess and improve the logical reasoning abilities of their models.
Critical Analysis
The authors have made a compelling case for the need to more rigorously evaluate the logical reasoning abilities of large language models (LLMs). The proposed evaluation framework appears to be a significant step forward in this direction, as it provides a comprehensive and systematic approach to assessing a wide range of logical reasoning skills.
One potential limitation of the study is that it focuses primarily on deductive reasoning, which may not capture the full scope of logical reasoning abilities. Future research could explore the models' performance on other types of reasoning, such as inductive or abductive reasoning.
Additionally, the authors acknowledge that the evaluation framework is limited to textual inputs and outputs, and may not fully capture the potential of LLMs to reason logically in more interactive or multimodal settings. Expanding the evaluation to include other modalities could provide a more complete understanding of the models' logical reasoning capabilities.
Another area for further exploration is the relationship between LLMs' logical reasoning abilities and their performance on real-world tasks that require robust logical thinking. While the proposed evaluation framework provides insights into the models' deductive reasoning skills, it would be valuable to understand how these skills translate to practical applications.
Overall, the paper presents a significant contribution to the ongoing efforts to understand and improve the logical reasoning abilities of large language models. The proposed evaluation framework offers a solid foundation for further research and development in this important area of AI.
Conclusion
This paper introduces a systematic approach to evaluating the logical reasoning abilities of large language models (LLMs). The authors argue that existing evaluation methods often lack comprehensive coverage of logical reasoning skills, and propose a new evaluation framework that assesses LLMs' deductive reasoning capabilities across a diverse set of logical concepts and reasoning patterns.
The findings from this evaluation provide valuable insights into the strengths and limitations of state-of-the-art LLMs, such as GPT-3, InstructGPT, and Megatron-LLM, when it comes to logical thinking. These insights could inform the development of more advanced models with stronger logical reasoning abilities, which could have important implications for applications that require robust logical reasoning.
While the proposed evaluation framework represents a significant step forward, the authors acknowledge that further research is needed to explore the models' logical reasoning abilities in more interactive and multimodal settings, as well as to understand how these skills translate to practical applications. Nonetheless, this paper provides a solid foundation for continued efforts to systematically evaluate and improve the logical reasoning capabilities of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
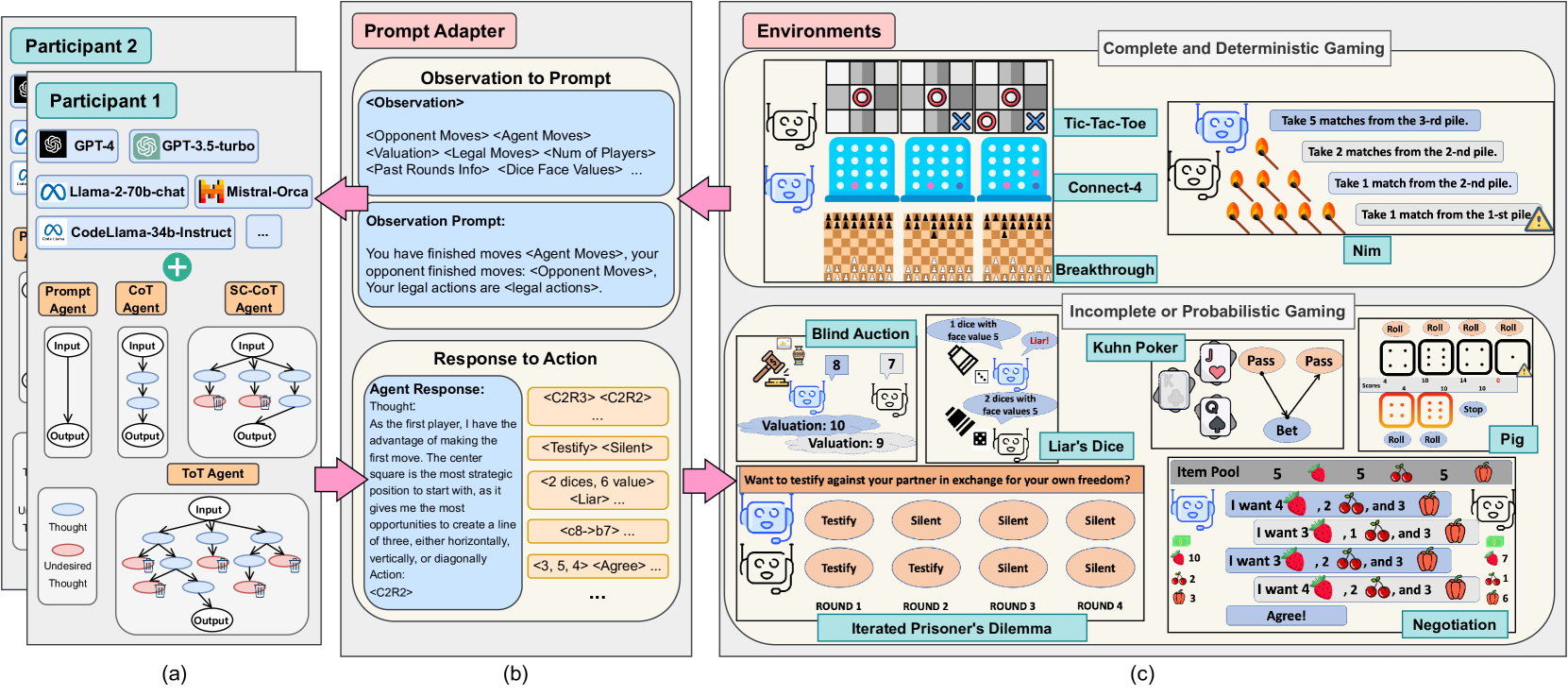
GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, Kaidi Xu
0
0
As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we (1) Characterize the game-theoretic reasoning of LLMs; and (2) Perform LLM-vs.-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Most open-source LLMs, e.g., CodeLlama-34b-Instruct and Llama-2-70b-chat, are less competitive than commercial LLMs, e.g., GPT-4, in complex games, yet the recently released Llama-3-70b-Instruct makes up for this shortcoming. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. We further characterize the game-theoretic properties of LLMs, such as equilibrium and Pareto Efficiency in repeated games. Detailed error profiles are provided for a better understanding of LLMs' behavior. We hope our research provides standardized protocols and serves as a foundation to spur further explorations in the strategic reasoning of LLMs.
6/11/2024

Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
0
0
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on genuine reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
4/3/2024

Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, Soujanya Poria
0
0
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
6/28/2024
🚀
Can LLMs Reason with Rules? Logic Scaffolding for Stress-Testing and Improving LLMs
Siyuan Wang, Zhongyu Wei, Yejin Choi, Xiang Ren
0
0
Large language models (LLMs) have achieved impressive human-like performance across various reasoning tasks. However, their mastery of underlying inferential rules still falls short of human capabilities. To investigate this, we propose a logic scaffolding inferential rule generation framework, to construct an inferential rule base, ULogic, comprising both primitive and compositional rules across five domains. Our analysis of GPT-series models over a rule subset reveals significant gaps in LLMs' logic understanding compared to human performance, especially in compositional and structural complex rules with certain bias patterns. We further distill these rules into a smaller-scale inference engine for flexible rule generation and enhancing downstream reasoning. Through a multi-judger evaluation, our inference engine proves effective in generating accurate, complex and abstract conclusions and premises, and improve various commonsense reasoning tasks. Overall, our work sheds light on LLMs' limitations in grasping inferential rule and suggests ways to enhance their logical reasoning abilities~footnote{Code and data are available at url{https://github.com/SiyuanWangw/ULogic}.}.
6/24/2024