SceneTeller: Language-to-3D Scene Generation

0

Sign in to get full access
Overview
- Proposes a language-to-3D scene generation model called SceneTeller
- Generates 3D indoor scenes from textual descriptions
- Uses a novel Gaussian splatting approach to create 3D object shapes
- Incorporates scene stylization to produce visually appealing scenes
Plain English Explanation
SceneTeller: Language-to-3D Scene Generation is a system that can create 3D indoor scenes based on text descriptions. Instead of manually designing 3D objects and scenes, this model allows users to simply describe what they want, and the system will generate a 3D scene to match.
The key innovation is a technique called Gaussian splatting, which is used to create the 3D shapes of objects. This approach allows the model to generate detailed, realistic-looking 3D objects from the textual input. The system also incorporates "scene stylization" to make the generated scenes visually appealing and aesthetically consistent.
Overall, this research aims to make it easier for people to create 3D content by allowing them to describe what they want in natural language, rather than having to manually design every element of the scene.
Technical Explanation
The SceneTeller model takes a text description as input and generates a 3D indoor scene as output. The key technical components include:
- Language Encoder: Encodes the input text description into a compact feature representation.
- 3D Splatter: Uses a novel Gaussian splatting approach to generate detailed 3D object shapes from the language features.
- Scene Composer: Arranges the 3D objects into a coherent 3D scene.
- Scene Stylizer: Applies stylistic transformations to the scene to improve its visual appeal.
The Gaussian splatting technique represents 3D objects as a set of Gaussian kernels, which allows for flexible and detailed shape generation. The scene composer then arranges these 3D objects into a final 3D scene. Finally, the scene stylizer applies various stylistic transformations, such as adjusting lighting and materials, to enhance the visual quality of the output.
Critical Analysis
The SceneTeller paper presents a compelling approach for generating 3D indoor scenes from text descriptions. However, there are a few potential limitations and areas for further research:
- Dataset and Bias: The system was trained on a specific dataset of indoor scenes, which may limit its ability to generalize to other types of scenes or contexts. The dataset could also contain biases that get reflected in the generated output.
- Realism and Coherence: While the Gaussian splatting technique produces detailed 3D shapes, the overall scene coherence and realism could still be improved, especially for complex or cluttered scenes.
- User Evaluation: The paper focuses on quantitative metrics, but more user studies and qualitative evaluations would be helpful to understand the system's usability and user experience in real-world applications.
- Real-time Performance: The current system may not be suitable for real-time or interactive applications due to the computational complexity of the 3D generation and stylization processes.
Further research could explore ways to address these limitations, such as expanding the training dataset, improving scene composition algorithms, and optimizing the model for faster inference.
Conclusion
SceneTeller represents an important step towards making 3D content creation more accessible to non-experts. By allowing users to simply describe what they want, rather than having to manually design every element, this system has the potential to democratize 3D scene generation and open up new creative possibilities.
While the current system has some limitations, the underlying techniques, such as Gaussian splatting and scene stylization, are promising and could inspire further advancements in this field. As language-guided 3D generation models continue to evolve, they could become powerful tools for a wide range of applications, from gaming and virtual reality to architectural design and education.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SceneTeller: Language-to-3D Scene Generation
Bac{s}ak Melis Ocal, Maxim Tatarchenko, Sezer Karaoglu, Theo Gevers
Designing high-quality indoor 3D scenes is important in many practical applications, such as room planning or game development. Conventionally, this has been a time-consuming process which requires both artistic skill and familiarity with professional software, making it hardly accessible for layman users. However, recent advances in generative AI have established solid foundation for democratizing 3D design. In this paper, we propose a pioneering approach for text-based 3D room design. Given a prompt in natural language describing the object placement in the room, our method produces a high-quality 3D scene corresponding to it. With an additional text prompt the users can change the appearance of the entire scene or of individual objects in it. Built using in-context learning, CAD model retrieval and 3D-Gaussian-Splatting-based stylization, our turnkey pipeline produces state-of-the-art 3D scenes, while being easy to use even for novices. Our project page is available at https://sceneteller.github.io/.
Read more7/31/2024

0
DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Shijie Zhou, Zhiwen Fan, Dejia Xu, Haoran Chang, Pradyumna Chari, Tejas Bharadwaj, Suya You, Zhangyang Wang, Achuta Kadambi
The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary flat (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/
Read more7/26/2024
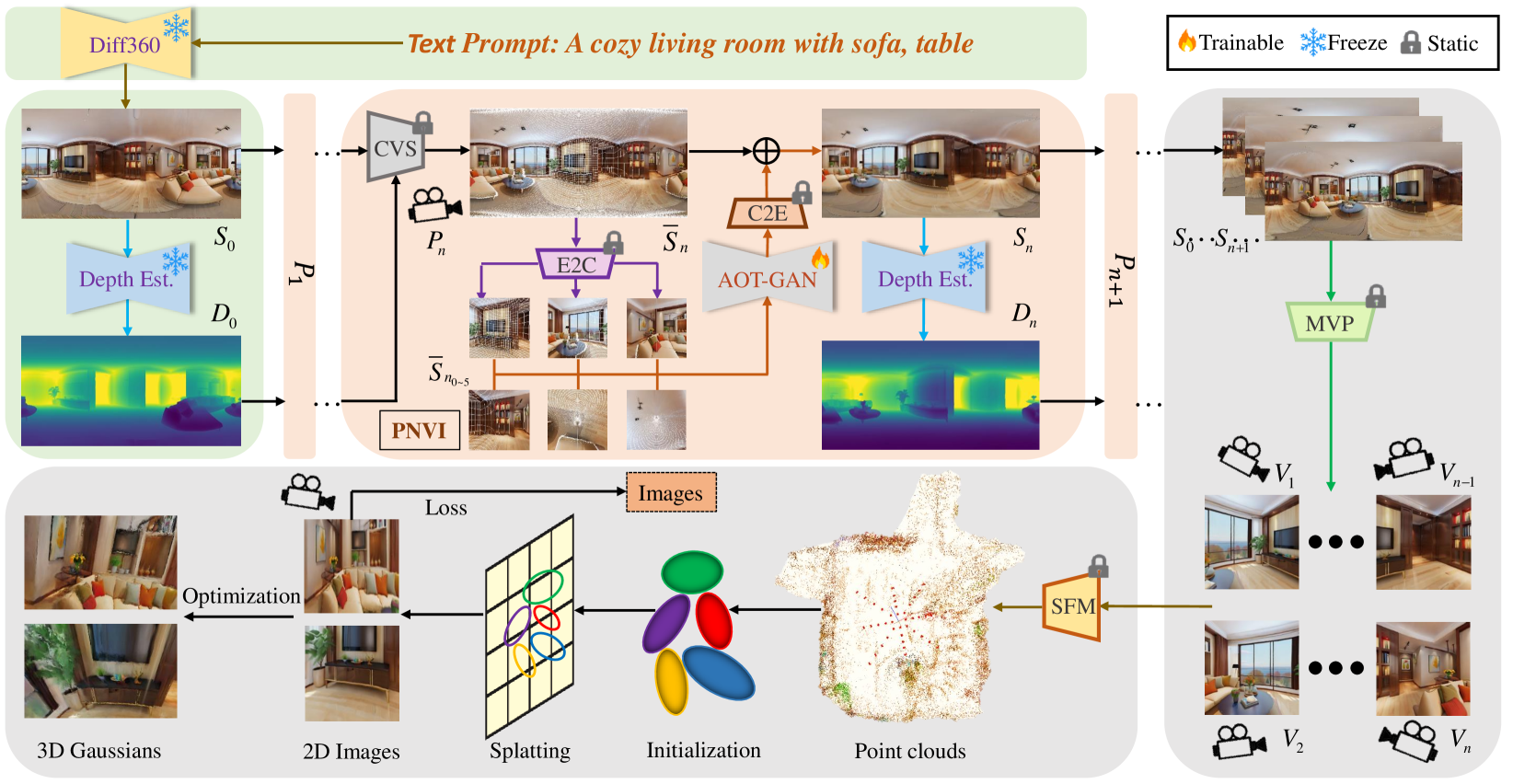
0
FastScene: Text-Driven Fast 3D Indoor Scene Generation via Panoramic Gaussian Splatting
Yikun Ma, Dandan Zhan, Zhi Jin
Text-driven 3D indoor scene generation holds broad applications, ranging from gaming and smart homes to AR/VR applications. Fast and high-fidelity scene generation is paramount for ensuring user-friendly experiences. However, existing methods are characterized by lengthy generation processes or necessitate the intricate manual specification of motion parameters, which introduces inconvenience for users. Furthermore, these methods often rely on narrow-field viewpoint iterative generations, compromising global consistency and overall scene quality. To address these issues, we propose FastScene, a framework for fast and higher-quality 3D scene generation, while maintaining the scene consistency. Specifically, given a text prompt, we generate a panorama and estimate its depth, since the panorama encompasses information about the entire scene and exhibits explicit geometric constraints. To obtain high-quality novel views, we introduce the Coarse View Synthesis (CVS) and Progressive Novel View Inpainting (PNVI) strategies, ensuring both scene consistency and view quality. Subsequently, we utilize Multi-View Projection (MVP) to form perspective views, and apply 3D Gaussian Splatting (3DGS) for scene reconstruction. Comprehensive experiments demonstrate FastScene surpasses other methods in both generation speed and quality with better scene consistency. Notably, guided only by a text prompt, FastScene can generate a 3D scene within a mere 15 minutes, which is at least one hour faster than state-of-the-art methods, making it a paradigm for user-friendly scene generation.
Read more5/10/2024

0
Lay-A-Scene: Personalized 3D Object Arrangement Using Text-to-Image Priors
Ohad Rahamim, Hilit Segev, Idan Achituve, Yuval Atzmon, Yoni Kasten, Gal Chechik
Generating 3D visual scenes is at the forefront of visual generative AI, but current 3D generation techniques struggle with generating scenes with multiple high-resolution objects. Here we introduce Lay-A-Scene, which solves the task of Open-set 3D Object Arrangement, effectively arranging unseen objects. Given a set of 3D objects, the task is to find a plausible arrangement of these objects in a scene. We address this task by leveraging pre-trained text-to-image models. We personalize the model and explain how to generate images of a scene that contains multiple predefined objects without neglecting any of them. Then, we describe how to infer the 3D poses and arrangement of objects from a 2D generated image by finding a consistent projection of objects onto the 2D scene. We evaluate the quality of Lay-A-Scene using 3D objects from Objaverse and human raters and find that it often generates coherent and feasible 3D object arrangements.
Read more6/5/2024