SCINeRF: Neural Radiance Fields from a Snapshot Compressive Image
2403.20018
0
0

Abstract
In this paper, we explore the potential of Snapshot Compressive Imaging (SCI) technique for recovering the underlying 3D scene representation from a single temporal compressed image. SCI is a cost-effective method that enables the recording of high-dimensional data, such as hyperspectral or temporal information, into a single image using low-cost 2D imaging sensors. To achieve this, a series of specially designed 2D masks are usually employed, which not only reduces storage requirements but also offers potential privacy protection. Inspired by this, to take one step further, our approach builds upon the powerful 3D scene representation capabilities of neural radiance fields (NeRF). Specifically, we formulate the physical imaging process of SCI as part of the training of NeRF, allowing us to exploit its impressive performance in capturing complex scene structures. To assess the effectiveness of our method, we conduct extensive evaluations using both synthetic data and real data captured by our SCI system. Extensive experimental results demonstrate that our proposed approach surpasses the state-of-the-art methods in terms of image reconstruction and novel view image synthesis. Moreover, our method also exhibits the ability to restore high frame-rate multi-view consistent images by leveraging SCI and the rendering capabilities of NeRF. The code is available at https://github.com/WU-CVGL/SCINeRF.
Create account to get full access
Introduction
The provided text discusses the challenges faced by conventional high-speed imaging systems, such as high hardware cost and storage requirements. It then introduces the snapshot compressive imaging (SCI) system, which uses a hardware encoder and software decoder to capture high-speed scenes while reducing storage and transmission needs.
The text explains that the hardware encoder uses specially designed 2D masks to modulate the incoming light into a single compressed image. This allows lower-cost cameras to capture high-speed scenes. The software decoder then reconstructs the high frame-rate images using the compressed measurement and encoding masks.
Several image reconstruction algorithms have been proposed for SCI, ranging from model-based methods to deep learning approaches. However, these methods do not consider the underlying 3D scene structure and can only recover images corresponding to the applied encoding masks.
To address these limitations, the paper proposes SCINeRF, which recovers the 3D scene representation from a single compressed image using neural radiance fields (NeRF). SCINeRF performs a joint optimization on both the camera poses and NeRF to synthesize high-quality, multi-view consistent images from the learned 3D representation.
The paper also discusses the experimental setup and findings, which show that SCINeRF achieves superior performance over previous state-of-the-art SCI reconstruction methods in terms of image restoration and novel view synthesis. Additionally, SCINeRF presents an efficient and privacy-preserving approach for deploying NeRF on edge devices and cloud infrastructure.
Related Work
This paper reviews two main areas related to their work: snapshot compressive imaging (SCI) and neural radiance fields (NeRF).
For SCI, early decoding/reconstruction methods focused on regularized optimization-based approaches that solve an optimization problem iteratively. More recent methods use deep learning, training on synthetic SCI measurements and masks. These deep learning-based methods can reconstruct high-quality images, but lack generalization to real datasets and can only reconstruct images corresponding to the masks used.
For NeRF, the original method requires accurate camera poses as input, which are estimated using structure-from-motion software. To address this, some NeRF variants focus on optimizing the scene and camera parameters jointly, while others refine inaccurate camera poses during the optimization process.
The paper indicates that the current work builds on these prior efforts in SCI and NeRF.
Method
The method takes a single compressed image and encoding masks as input, and recovers the underlying 3D scene representation as well as camera poses. High frame-rate images can then be rendered from the learned 3D scene representation. The approach leverages NeRF as the underlying 3D scene representation due to its impressive representation capability. The real image formation process is followed to synthesize a snapshot compressed image from NeRF. By maximizing the photometric consistency between the synthesized image and the actual measurements, the method optimizes both NeRF and the camera poses. The overview of the method is presented in Figure 2.
This section provides background on the NeRF (Neural Radiance Fields) technique and its application to video compressed sensing imaging (SCI).
NeRF takes a set of multi-view input images and their associated camera parameters as input. It transfers the pixel information into rays and samples points along each ray. For each sampled point, NeRF estimates the volume density and view-dependent RGB color using a neural network. These estimates are then integrated along the rays using a volumetric rendering technique to synthesize the corresponding pixel intensities.
The video SCI imaging process involves modulating the captured image with a series of binary masks. This compressed measurement can be modeled as the sum of element-wise multiplications between the virtual frames (recovered using NeRF) and the binary masks.
To handle the unknown camera poses for the compressed frames, the approach initializes the poses using linear interpolation between the start and end poses. It then jointly optimizes the NeRF parameters and camera poses by minimizing the difference between the rendered and real captured compressed image.
Experiments
The paper validates the SCINeRF system on both synthetic and real datasets captured by the authors' system. It is evaluated against state-of-the-art (SOTA) single-channel imaging (SCI) image restoration methods. The experimental results demonstrate that SCINeRF delivers higher performance compared to existing works in terms of restoration quality.
The paper uses synthetic datasets from commonly-used multi-view datasets as well as Blender-generated datasets to better simulate real-world capturing. The real-world dataset was captured using an SCI imaging system consisting of a CCD camera and a DMD. The compression ratio for both synthetic and real datasets was 8.
SCINeRF is compared against SOTA SCI image restoration methods like GAP-TV, PnP-FFDNet, PnP-FastDVDNet, and EfficientSCI. In addition, the novel view image synthesis performance of SCINeRF is compared against vanilla NeRF using images reconstructed from the prior SOTA methods.
The results on the synthetic dataset show that SCINeRF achieves superior PSNR and LPIPS metrics, though the SSIM metric does not always exceed EfficientSCI. This is attributed to NeRF's rendering process introducing marginal information loss. On real datasets, SCINeRF outperforms the SOTA methods in recovering scenes with fine details.
Additional studies examine the effect of mask overlapping rate and high compression ratios. Higher overlapping rates up to 0.25 improve performance, but too high rates lead to degradation. SCINeRF maintains high image quality even under very high compression ratios, unlike the SOTA methods.
Conclusion
This paper presents SCINeRF, a novel approach for learning 3D scene representations from a single snapshot compressed image (SCI). SCINeRF uses neural radiance fields (NeRF) as its underlying scene representation due to NeRF's impressive representation capability.
The method exploits the physical image formation process of an SCI image to formulate the training objective, which allows for jointly optimizing the NeRF model and camera poses. Unlike previous work, SCINeRF considers the underlying 3D scene structure to ensure multi-view consistency among the recovered images.
Thorough evaluations are conducted against state-of-the-art SCI recovery techniques using both synthetic and real datasets. The results demonstrate the superior performance of SCINeRF compared to existing methods, highlighting the necessity of considering the 3D scene structure for effective SCI decoding.
The work was supported in part by grants from the National Natural Science Foundation of China, Westlake University, Westlake Education Foundation, and the Key Project of Westlake Institute for Optoelectronics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
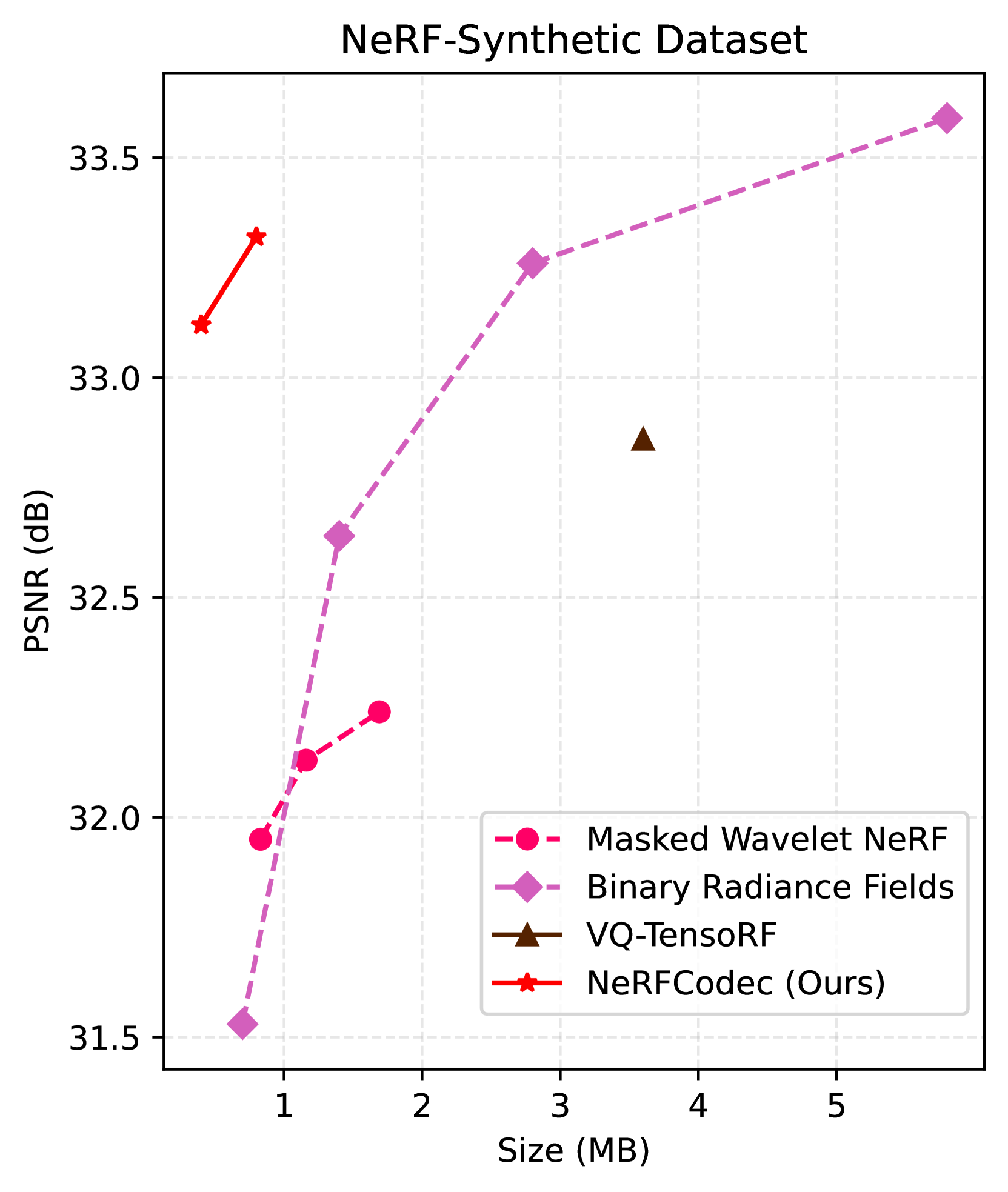
NeRFCodec: Neural Feature Compression Meets Neural Radiance Fields for Memory-Efficient Scene Representation
Sicheng Li, Hao Li, Yiyi Liao, Lu Yu
0
0
The emergence of Neural Radiance Fields (NeRF) has greatly impacted 3D scene modeling and novel-view synthesis. As a kind of visual media for 3D scene representation, compression with high rate-distortion performance is an eternal target. Motivated by advances in neural compression and neural field representation, we propose NeRFCodec, an end-to-end NeRF compression framework that integrates non-linear transform, quantization, and entropy coding for memory-efficient scene representation. Since training a non-linear transform directly on a large scale of NeRF feature planes is impractical, we discover that pre-trained neural 2D image codec can be utilized for compressing the features when adding content-specific parameters. Specifically, we reuse neural 2D image codec but modify its encoder and decoder heads, while keeping the other parts of the pre-trained decoder frozen. This allows us to train the full pipeline via supervision of rendering loss and entropy loss, yielding the rate-distortion balance by updating the content-specific parameters. At test time, the bitstreams containing latent code, feature decoder head, and other side information are transmitted for communication. Experimental results demonstrate our method outperforms existing NeRF compression methods, enabling high-quality novel view synthesis with a memory budget of 0.5 MB.
4/4/2024

Neural NeRF Compression
Tuan Pham, Stephan Mandt
0
0
Neural Radiance Fields (NeRFs) have emerged as powerful tools for capturing detailed 3D scenes through continuous volumetric representations. Recent NeRFs utilize feature grids to improve rendering quality and speed; however, these representations introduce significant storage overhead. This paper presents a novel method for efficiently compressing a grid-based NeRF model, addressing the storage overhead concern. Our approach is based on the non-linear transform coding paradigm, employing neural compression for compressing the model's feature grids. Due to the lack of training data involving many i.i.d scenes, we design an encoder-free, end-to-end optimized approach for individual scenes, using lightweight decoders. To leverage the spatial inhomogeneity of the latent feature grids, we introduce an importance-weighted rate-distortion objective and a sparse entropy model employing a masking mechanism. Our experimental results validate that our proposed method surpasses existing works in terms of grid-based NeRF compression efficacy and reconstruction quality.
6/14/2024

DistillNeRF: Perceiving 3D Scenes from Single-Glance Images by Distilling Neural Fields and Foundation Model Features
Letian Wang, Seung Wook Kim, Jiawei Yang, Cunjun Yu, Boris Ivanovic, Steven L. Waslander, Yue Wang, Sanja Fidler, Marco Pavone, Peter Karkus
0
0
We propose DistillNeRF, a self-supervised learning framework addressing the challenge of understanding 3D environments from limited 2D observations in autonomous driving. Our method is a generalizable feedforward model that predicts a rich neural scene representation from sparse, single-frame multi-view camera inputs, and is trained self-supervised with differentiable rendering to reconstruct RGB, depth, or feature images. Our first insight is to exploit per-scene optimized Neural Radiance Fields (NeRFs) by generating dense depth and virtual camera targets for training, thereby helping our model to learn 3D geometry from sparse non-overlapping image inputs. Second, to learn a semantically rich 3D representation, we propose distilling features from pre-trained 2D foundation models, such as CLIP or DINOv2, thereby enabling various downstream tasks without the need for costly 3D human annotations. To leverage these two insights, we introduce a novel model architecture with a two-stage lift-splat-shoot encoder and a parameterized sparse hierarchical voxel representation. Experimental results on the NuScenes dataset demonstrate that DistillNeRF significantly outperforms existing comparable self-supervised methods for scene reconstruction, novel view synthesis, and depth estimation; and it allows for competitive zero-shot 3D semantic occupancy prediction, as well as open-world scene understanding through distilled foundation model features. Demos and code will be available at https://distillnerf.github.io/.
6/19/2024
🧠
Transient Neural Radiance Fields for Lidar View Synthesis and 3D Reconstruction
Anagh Malik, Parsa Mirdehghan, Sotiris Nousias, Kiriakos N. Kutulakos, David B. Lindell
0
0
Neural radiance fields (NeRFs) have become a ubiquitous tool for modeling scene appearance and geometry from multiview imagery. Recent work has also begun to explore how to use additional supervision from lidar or depth sensor measurements in the NeRF framework. However, previous lidar-supervised NeRFs focus on rendering conventional camera imagery and use lidar-derived point cloud data as auxiliary supervision; thus, they fail to incorporate the underlying image formation model of the lidar. Here, we propose a novel method for rendering transient NeRFs that take as input the raw, time-resolved photon count histograms measured by a single-photon lidar system, and we seek to render such histograms from novel views. Different from conventional NeRFs, the approach relies on a time-resolved version of the volume rendering equation to render the lidar measurements and capture transient light transport phenomena at picosecond timescales. We evaluate our method on a first-of-its-kind dataset of simulated and captured transient multiview scans from a prototype single-photon lidar. Overall, our work brings NeRFs to a new dimension of imaging at transient timescales, newly enabling rendering of transient imagery from novel views. Additionally, we show that our approach recovers improved geometry and conventional appearance compared to point cloud-based supervision when training on few input viewpoints. Transient NeRFs may be especially useful for applications which seek to simulate raw lidar measurements for downstream tasks in autonomous driving, robotics, and remote sensing.
4/9/2024