SDL-MVS: View Space and Depth Deformable Learning Paradigm for Multi-View Stereo Reconstruction in Remote Sensing
2405.17140
0
0

Abstract
Research on multi-view stereo based on remote sensing images has promoted the development of large-scale urban 3D reconstruction. However, remote sensing multi-view image data suffers from the problems of occlusion and uneven brightness between views during acquisition, which leads to the problem of blurred details in depth estimation. To solve the above problem, we re-examine the deformable learning method in the Multi-View Stereo task and propose a novel paradigm based on view Space and Depth deformable Learning (SDL-MVS), aiming to learn deformable interactions of features in different view spaces and deformably model the depth ranges and intervals to enable high accurate depth estimation. Specifically, to solve the problem of view noise caused by occlusion and uneven brightness, we propose a Progressive Space deformable Sampling (PSS) mechanism, which performs deformable learning of sampling points in the 3D frustum space and the 2D image space in a progressive manner to embed source features to the reference feature adaptively. To further optimize the depth, we introduce Depth Hypothesis deformable Discretization (DHD), which achieves precise positioning of the depth prior by adaptively adjusting the depth range hypothesis and performing deformable discretization of the depth interval hypothesis. Finally, our SDL-MVS achieves explicit modeling of occlusion and uneven brightness faced in multi-view stereo through the deformable learning paradigm of view space and depth, achieving accurate multi-view depth estimation. Extensive experiments on LuoJia-MVS and WHU datasets show that our SDL-MVS reaches state-of-the-art performance. It is worth noting that our SDL-MVS achieves an MAE error of 0.086, an accuracy of 98.9% for <0.6m, and 98.9% for <3-interval on the LuoJia-MVS dataset under the premise of three views as input.
Create account to get full access
Overview
- Proposes a novel "SDL-MVS" framework for multi-view stereo (MVS) reconstruction in remote sensing applications
- Combines view space and depth deformable learning to improve the accuracy and robustness of 3D reconstruction
- Leverages deep learning to learn deformations in both view space and depth space for better MVS modeling
Plain English Explanation
The paper presents a new approach called SDL-MVS (View Space and Depth Deformable Learning Paradigm for Multi-View Stereo Reconstruction) that aims to improve the accuracy and reliability of 3D reconstruction from multiple camera views, particularly in remote sensing applications.
Traditional multi-view stereo (MVS) techniques can struggle with challenges like varying camera viewpoints, occlusions, and complex scene geometries. The SDL-MVS framework tackles these issues by using deep learning to learn the deformations that occur in both the view space (how the scene appears from different camera angles) and the depth space (the 3D structure of the scene).
By modeling these deformations, the system can more effectively match features across views and estimate accurate 3D depth information, leading to higher quality 3D reconstructions. This is especially valuable for applications like aerial or satellite imaging, where the camera positions and scene complexity can be significant barriers to effective 3D modeling.
The key innovation of SDL-MVS is jointly learning the deformations in both the view space and depth space, rather than treating them independently. This allows the system to better capture the interplay between how the scene is observed and its underlying 3D structure, resulting in more robust and accurate 3D reconstructions.
Technical Explanation
The SDL-MVS framework consists of several key components:
-
View Space Deformable Learning: This module aims to learn the deformations that occur when the same scene is observed from different camera viewpoints. By modeling these view-dependent distortions, the system can better match corresponding features across multiple views.
-
Depth Space Deformable Learning: This component focuses on learning the deformations in the depth space, which represent the 3D structure of the scene. Modeling these depth-related deformations helps the system estimate more accurate 3D depth information.
-
Joint View-Depth Deformable Learning: The core innovation of SDL-MVS is the joint optimization of the view space and depth space deformable learning modules. This allows the system to capture the interplay between the observed views and the underlying 3D structure, leading to more robust and accurate 3D reconstructions.
The authors evaluate SDL-MVS on several remote sensing datasets and compare its performance to state-of-the-art MVS methods, such as Adaptive Learning for Multi-View Stereo Reconstruction, RobustMVS: Single-Domain Generalized Deep Multi-View Stereo, and MGS-SLAM: Monocular Sparse Tracking and Gaussian Mapping for SLAM. The results demonstrate that SDL-MVS outperforms these alternatives in terms of both accuracy and robustness, particularly in challenging remote sensing scenarios.
Critical Analysis
The paper presents a well-designed and comprehensive framework for multi-view stereo reconstruction, with a strong focus on addressing the unique challenges of remote sensing applications. The joint optimization of view space and depth space deformable learning is a novel and promising approach that goes beyond existing techniques.
However, the authors acknowledge some limitations of their work. For instance, the current implementation of SDL-MVS may struggle with highly complex scenes or extreme viewpoint variations, and further research is needed to address these edge cases. Additionally, the computational complexity of the joint optimization process could be a concern for real-time or resource-constrained applications.
Another potential area for improvement is the incorporation of additional cues, such as semantic information or learned priors, to further enhance the 3D reconstruction accuracy. The authors also note that testing on a wider range of remote sensing datasets would be valuable to fully evaluate the generalization capabilities of SDL-MVS.
Overall, the SDL-MVS framework represents a significant advancement in the field of multi-view stereo reconstruction, particularly for remote sensing applications. The authors have demonstrated the effectiveness of their approach and provided a solid foundation for future research in this area.
Conclusion
The SDL-MVS framework proposed in this paper offers a novel and effective solution for multi-view stereo reconstruction in remote sensing applications. By jointly learning the deformations in both view space and depth space, the system is able to better capture the complex relationships between observed camera views and the underlying 3D structure of the scene, leading to more accurate and robust 3D reconstructions.
The successful evaluation of SDL-MVS on various remote sensing datasets, and its performance improvements over state-of-the-art methods, suggest that this approach could have a significant impact on a wide range of applications that rely on accurate 3D modeling, such as urban planning, land use analysis, and environmental monitoring. Further research to address the identified limitations and explore additional enhancements could further strengthen the capabilities of SDL-MVS and solidify its position as a leading solution for multi-view stereo reconstruction in remote sensing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Adaptive Learning for Multi-view Stereo Reconstruction
Qinglu Min, Jie Zhao, Zhihao Zhang, Chen Min
0
0
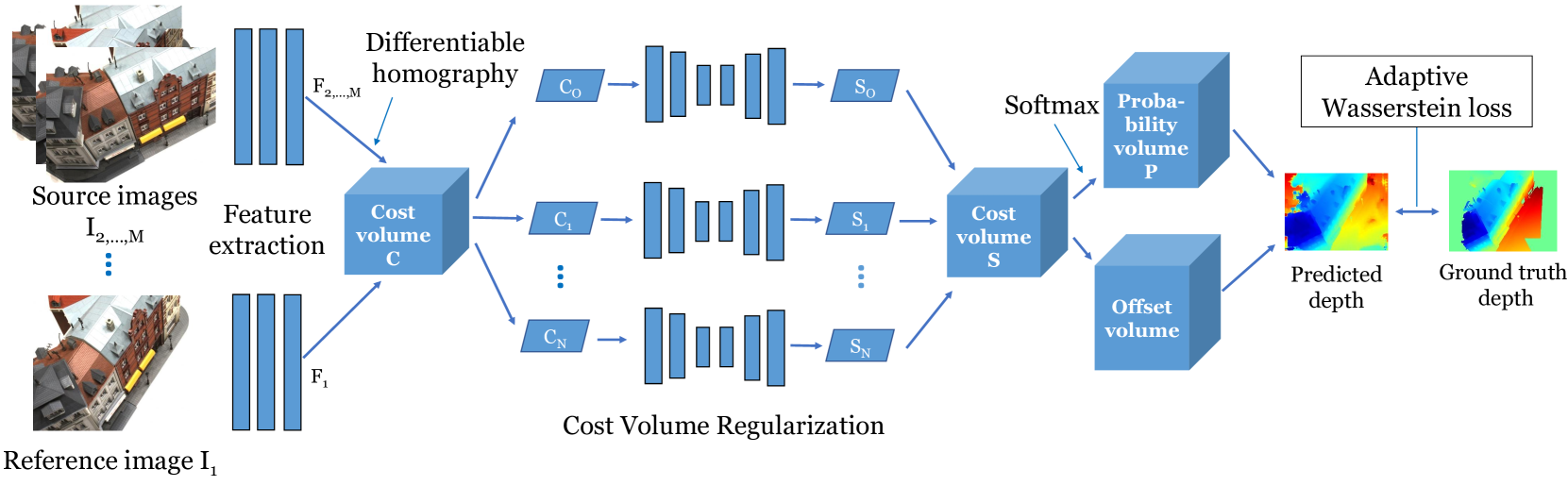
Deep learning has recently demonstrated its excellent performance on the task of multi-view stereo (MVS). However, loss functions applied for deep MVS are rarely studied. In this paper, we first analyze existing loss functions' properties for deep depth based MVS approaches. Regression based loss leads to inaccurate continuous results by computing mathematical expectation, while classification based loss outputs discretized depth values. To this end, we then propose a novel loss function, named adaptive Wasserstein loss, which is able to narrow down the difference between the true and predicted probability distributions of depth. Besides, a simple but effective offset module is introduced to better achieve sub-pixel prediction accuracy. Extensive experiments on different benchmarks, including DTU, Tanks and Temples and BlendedMVS, show that the proposed method with the adaptive Wasserstein loss and the offset module achieves state-of-the-art performance.
4/9/2024
RobustMVS: Single Domain Generalized Deep Multi-view Stereo
Hongbin Xu, Weitao Chen, Baigui Sun, Xuansong Xie, Wenxiong Kang
0
0
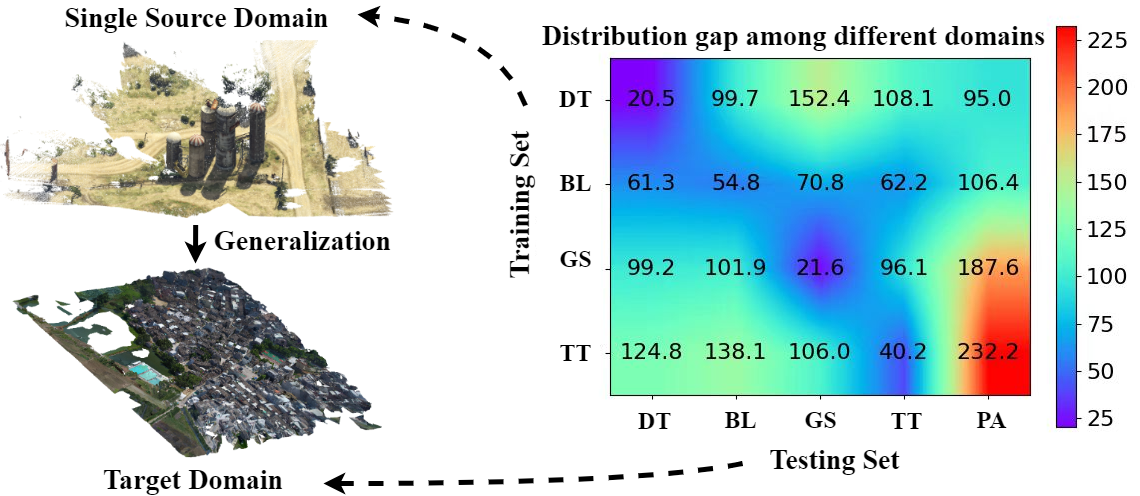
Despite the impressive performance of Multi-view Stereo (MVS) approaches given plenty of training samples, the performance degradation when generalizing to unseen domains has not been clearly explored yet. In this work, we focus on the domain generalization problem in MVS. To evaluate the generalization results, we build a novel MVS domain generalization benchmark including synthetic and real-world datasets. In contrast to conventional domain generalization benchmarks, we consider a more realistic but challenging scenario, where only one source domain is available for training. The MVS problem can be analogized back to the feature matching task, and maintaining robust feature consistency among views is an important factor for improving generalization performance. To address the domain generalization problem in MVS, we propose a novel MVS framework, namely RobustMVS. A DepthClustering-guided Whitening (DCW) loss is further introduced to preserve the feature consistency among different views, which decorrelates multi-view features from viewpoint-specific style information based on geometric priors from depth maps. The experimental results further show that our method achieves superior performance on the domain generalization benchmark.
5/16/2024
⚙️
PlaneMVS: 3D Plane Reconstruction from Multi-View Stereo
Jiachen Liu, Pan Ji, Nitin Bansal, Changjiang Cai, Qingan Yan, Xiaolei Huang, Yi Xu
0
0
We present a novel framework named PlaneMVS for 3D plane reconstruction from multiple input views with known camera poses. Most previous learning-based plane reconstruction methods reconstruct 3D planes from single images, which highly rely on single-view regression and suffer from depth scale ambiguity. In contrast, we reconstruct 3D planes with a multi-view-stereo (MVS) pipeline that takes advantage of multi-view geometry. We decouple plane reconstruction into a semantic plane detection branch and a plane MVS branch. The semantic plane detection branch is based on a single-view plane detection framework but with differences. The plane MVS branch adopts a set of slanted plane hypotheses to replace conventional depth hypotheses to perform plane sweeping strategy and finally learns pixel-level plane parameters and its planar depth map. We present how the two branches are learned in a balanced way, and propose a soft-pooling loss to associate the outputs of the two branches and make them benefit from each other. Extensive experiments on various indoor datasets show that PlaneMVS significantly outperforms state-of-the-art (SOTA) single-view plane reconstruction methods on both plane detection and 3D geometry metrics. Our method even outperforms a set of SOTA learning-based MVS methods thanks to the learned plane priors. To the best of our knowledge, this is the first work on 3D plane reconstruction within an end-to-end MVS framework. Source code: https://github.com/oppo-us-research/PlaneMVS.
6/7/2024
MVSBoost: An Efficient Point Cloud-based 3D Reconstruction
Umair Haroon, Ahmad AlMughrabi, Ricardo Marques, Petia Radeva
0
0
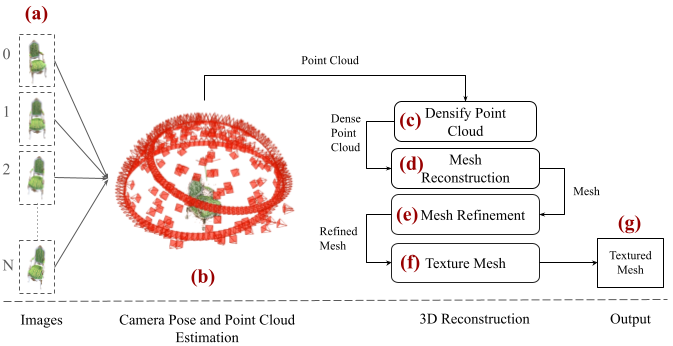
Efficient and accurate 3D reconstruction is crucial for various applications, including augmented and virtual reality, medical imaging, and cinematic special effects. While traditional Multi-View Stereo (MVS) systems have been fundamental in these applications, using neural implicit fields in implicit 3D scene modeling has introduced new possibilities for handling complex topologies and continuous surfaces. However, neural implicit fields often suffer from computational inefficiencies, overfitting, and heavy reliance on data quality, limiting their practical use. This paper presents an enhanced MVS framework that integrates multi-view 360-degree imagery with robust camera pose estimation via Structure from Motion (SfM) and advanced image processing for point cloud densification, mesh reconstruction, and texturing. Our approach significantly improves upon traditional MVS methods, offering superior accuracy and precision as validated using Chamfer distance metrics on the Realistic Synthetic 360 dataset. The developed MVS technique enhances the detail and clarity of 3D reconstructions and demonstrates superior computational efficiency and robustness in complex scene reconstruction, effectively handling occlusions and varying viewpoints. These improvements suggest that our MVS framework can compete with and potentially exceed current state-of-the-art neural implicit field methods, especially in scenarios requiring real-time processing and scalability.
6/21/2024