MVSBoost: An Efficient Point Cloud-based 3D Reconstruction
2406.13515
0
0
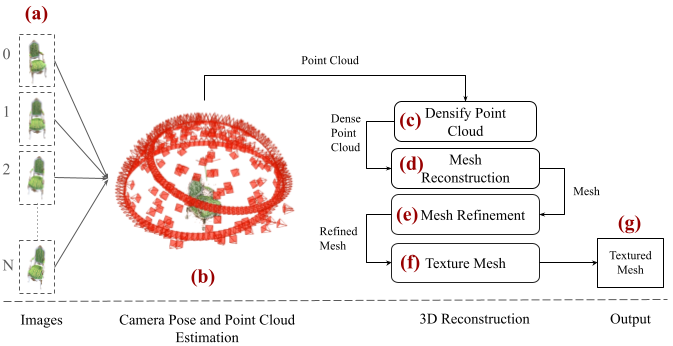
Abstract
Efficient and accurate 3D reconstruction is crucial for various applications, including augmented and virtual reality, medical imaging, and cinematic special effects. While traditional Multi-View Stereo (MVS) systems have been fundamental in these applications, using neural implicit fields in implicit 3D scene modeling has introduced new possibilities for handling complex topologies and continuous surfaces. However, neural implicit fields often suffer from computational inefficiencies, overfitting, and heavy reliance on data quality, limiting their practical use. This paper presents an enhanced MVS framework that integrates multi-view 360-degree imagery with robust camera pose estimation via Structure from Motion (SfM) and advanced image processing for point cloud densification, mesh reconstruction, and texturing. Our approach significantly improves upon traditional MVS methods, offering superior accuracy and precision as validated using Chamfer distance metrics on the Realistic Synthetic 360 dataset. The developed MVS technique enhances the detail and clarity of 3D reconstructions and demonstrates superior computational efficiency and robustness in complex scene reconstruction, effectively handling occlusions and varying viewpoints. These improvements suggest that our MVS framework can compete with and potentially exceed current state-of-the-art neural implicit field methods, especially in scenarios requiring real-time processing and scalability.
Create account to get full access
Overview
- This paper introduces MVSBoost, an efficient point cloud-based 3D reconstruction method that leverages multi-view stereo (MVS) techniques to generate high-quality 3D models.
- The key innovations of MVSBoost include a novel cost volume optimization scheme and an efficient data processing pipeline that enables fast and accurate 3D reconstruction from multi-view images.
- The authors demonstrate the effectiveness of MVSBoost through extensive experiments, showing that it outperforms state-of-the-art MVS methods in terms of both reconstruction quality and computational efficiency.
Plain English Explanation
MVSBoost is a new way to create 3D models from a collection of 2D images. It works by combining information from multiple viewpoints (multi-view stereo) to build a detailed 3D representation of the scene.
The core idea behind MVSBoost is to optimize a "cost volume" - a 3D grid that represents the estimated depth and confidence at each point in the scene. This is done using a novel optimization algorithm that is both efficient and effective, allowing MVSBoost to generate high-quality 3D models quickly.
Compared to other state-of-the-art 3D reconstruction methods, MVSBoost stands out in two key ways:
-
Reconstruction Quality: MVSBoost can produce 3D models with greater detail and accuracy than previous approaches, capturing fine-grained geometric features.
-
Computational Efficiency: The MVSBoost pipeline is designed to be fast and scalable, allowing it to process large-scale datasets efficiently.
These advantages make MVSBoost a valuable tool for a wide range of applications, from 3D mapping and urban modeling to virtual and augmented reality experiences.
Technical Explanation
The core innovation of MVSBoost is a novel cost volume optimization scheme that efficiently combines information from multiple viewpoints to estimate the 3D structure of a scene. The authors formulate this as an energy minimization problem, where the goal is to find the depth and confidence values that best explain the observed image data.
To achieve this, MVSBoost first constructs a 3D cost volume by projecting 2D image features into a discretized 3D space. This cost volume is then optimized using a multi-scale iterative refinement process, which progressively refines the depth and confidence estimates to converge on an accurate 3D reconstruction.
The authors also introduce an efficient data processing pipeline that enables MVSBoost to scale to large-scale datasets. This includes techniques for reducing memory consumption, accelerating feature matching, and parallelizing the optimization process.
Through extensive experiments, the authors demonstrate that MVSBoost outperforms state-of-the-art MVS methods like Fast Generalizable Gaussian Splatting Reconstruction, PlaneMVS, ResFM, and SDL-MVS in terms of both reconstruction quality and computational efficiency.
Critical Analysis
The authors provide a thorough evaluation of MVSBoost's performance, demonstrating its superiority over other state-of-the-art MVS methods. However, the paper does not address some potential limitations of the approach:
- Sensitivity to Occlusions: Like many MVS methods, MVSBoost may struggle with scenes containing significant occlusions, which could lead to incomplete or inaccurate 3D reconstructions.
- Dependence on Image Quality: The performance of MVSBoost is likely to be affected by the quality and resolution of the input images, as poor image data could degrade the accuracy of the cost volume optimization.
- Scalability to Extremely Large Datasets: While the authors show that MVSBoost can handle large-scale datasets, it is unclear how the method would scale to truly massive, internet-scale image collections.
Further research could explore ways to address these limitations, such as incorporating more robust occlusion handling techniques or investigating the use of self-supervised neural implicit feature fields to improve the method's flexibility and scalability.
Conclusion
Overall, MVSBoost represents an important advance in the field of 3D reconstruction from multi-view images. By introducing a novel cost volume optimization scheme and an efficient data processing pipeline, the authors have developed a method that can generate high-quality 3D models quickly and at scale.
The superior performance of MVSBoost, as demonstrated in the paper, suggests that it could have a significant impact on a wide range of applications, from urban planning and autonomous navigation to virtual and augmented reality. As the demand for accurate and accessible 3D data continues to grow, methods like MVSBoost will likely play an increasingly important role in shaping the future of spatial computing and visualization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo
Tianqi Liu, Guangcong Wang, Shoukang Hu, Liao Shen, Xinyi Ye, Yuhang Zang, Zhiguo Cao, Wei Li, Ziwei Liu
0
0
We present MVSGaussian, a new generalizable 3D Gaussian representation approach derived from Multi-View Stereo (MVS) that can efficiently reconstruct unseen scenes. Specifically, 1) we leverage MVS to encode geometry-aware Gaussian representations and decode them into Gaussian parameters. 2) To further enhance performance, we propose a hybrid Gaussian rendering that integrates an efficient volume rendering design for novel view synthesis. 3) To support fast fine-tuning for specific scenes, we introduce a multi-view geometric consistent aggregation strategy to effectively aggregate the point clouds generated by the generalizable model, serving as the initialization for per-scene optimization. Compared with previous generalizable NeRF-based methods, which typically require minutes of fine-tuning and seconds of rendering per image, MVSGaussian achieves real-time rendering with better synthesis quality for each scene. Compared with the vanilla 3D-GS, MVSGaussian achieves better view synthesis with less training computational cost. Extensive experiments on DTU, Real Forward-facing, NeRF Synthetic, and Tanks and Temples datasets validate that MVSGaussian attains state-of-the-art performance with convincing generalizability, real-time rendering speed, and fast per-scene optimization.
5/21/2024
⚙️
PlaneMVS: 3D Plane Reconstruction from Multi-View Stereo
Jiachen Liu, Pan Ji, Nitin Bansal, Changjiang Cai, Qingan Yan, Xiaolei Huang, Yi Xu
0
0
We present a novel framework named PlaneMVS for 3D plane reconstruction from multiple input views with known camera poses. Most previous learning-based plane reconstruction methods reconstruct 3D planes from single images, which highly rely on single-view regression and suffer from depth scale ambiguity. In contrast, we reconstruct 3D planes with a multi-view-stereo (MVS) pipeline that takes advantage of multi-view geometry. We decouple plane reconstruction into a semantic plane detection branch and a plane MVS branch. The semantic plane detection branch is based on a single-view plane detection framework but with differences. The plane MVS branch adopts a set of slanted plane hypotheses to replace conventional depth hypotheses to perform plane sweeping strategy and finally learns pixel-level plane parameters and its planar depth map. We present how the two branches are learned in a balanced way, and propose a soft-pooling loss to associate the outputs of the two branches and make them benefit from each other. Extensive experiments on various indoor datasets show that PlaneMVS significantly outperforms state-of-the-art (SOTA) single-view plane reconstruction methods on both plane detection and 3D geometry metrics. Our method even outperforms a set of SOTA learning-based MVS methods thanks to the learned plane priors. To the best of our knowledge, this is the first work on 3D plane reconstruction within an end-to-end MVS framework. Source code: https://github.com/oppo-us-research/PlaneMVS.
6/7/2024

RESFM: Robust Equivariant Multiview Structure from Motion
Fadi Khatib, Yoni Kasten, Dror Moran, Meirav Galun, Ronen Basri
0
0
Multiview Structure from Motion is a fundamental and challenging computer vision problem. A recent deep-based approach was proposed utilizing matrix equivariant architectures for the simultaneous recovery of camera pose and 3D scene structure from large image collections. This work however made the unrealistic assumption that the point tracks given as input are clean of outliers. Here we propose an architecture suited to dealing with outliers by adding an inlier/outlier classifying module that respects the model equivariance and by adding a robust bundle adjustment step. Experiments demonstrate that our method can be successfully applied in realistic settings that include large image collections and point tracks extracted with common heuristics and include many outliers.
4/23/2024

SDL-MVS: View Space and Depth Deformable Learning Paradigm for Multi-View Stereo Reconstruction in Remote Sensing
Yong-Qiang Mao, Hanbo Bi, Liangyu Xu, Kaiqiang Chen, Zhirui Wang, Xian Sun, Kun Fu
0
0
Research on multi-view stereo based on remote sensing images has promoted the development of large-scale urban 3D reconstruction. However, remote sensing multi-view image data suffers from the problems of occlusion and uneven brightness between views during acquisition, which leads to the problem of blurred details in depth estimation. To solve the above problem, we re-examine the deformable learning method in the Multi-View Stereo task and propose a novel paradigm based on view Space and Depth deformable Learning (SDL-MVS), aiming to learn deformable interactions of features in different view spaces and deformably model the depth ranges and intervals to enable high accurate depth estimation. Specifically, to solve the problem of view noise caused by occlusion and uneven brightness, we propose a Progressive Space deformable Sampling (PSS) mechanism, which performs deformable learning of sampling points in the 3D frustum space and the 2D image space in a progressive manner to embed source features to the reference feature adaptively. To further optimize the depth, we introduce Depth Hypothesis deformable Discretization (DHD), which achieves precise positioning of the depth prior by adaptively adjusting the depth range hypothesis and performing deformable discretization of the depth interval hypothesis. Finally, our SDL-MVS achieves explicit modeling of occlusion and uneven brightness faced in multi-view stereo through the deformable learning paradigm of view space and depth, achieving accurate multi-view depth estimation. Extensive experiments on LuoJia-MVS and WHU datasets show that our SDL-MVS reaches state-of-the-art performance. It is worth noting that our SDL-MVS achieves an MAE error of 0.086, an accuracy of 98.9% for <0.6m, and 98.9% for <3-interval on the LuoJia-MVS dataset under the premise of three views as input.
5/28/2024