Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition

0

Sign in to get full access
Overview
- Seed-ASR is a research paper that explores using large language models (LLMs) for speech recognition in diverse speech and context scenarios.
- The paper proposes a novel approach called Seed-ASR that leverages the powerful language understanding capabilities of LLMs to improve automatic speech recognition (ASR) performance.
- The research aims to address the challenges of handling diverse speech and contexts in traditional ASR systems.
Plain English Explanation
The Seed-ASR paper explores a new way to do speech recognition using large language models (LLMs). Traditional speech recognition systems can struggle when dealing with a wide variety of speech patterns, accents, and contexts. The researchers behind Seed-ASR believe that LLMs, which are trained on massive amounts of text data, can help improve speech recognition in these challenging scenarios.
The core idea of Seed-ASR is to leverage the powerful language understanding capabilities of LLMs to enhance the performance of automatic speech recognition (ASR) systems. By integrating LLMs into the ASR pipeline, the researchers aim to help the system better handle diverse speech and contexts, such as different accents, speaking styles, background noise, and conversational settings.
The Seed-ASR approach works by using the LLM to provide additional context and understanding to the ASR system. Rather than just transcribing the raw audio, the system can draw on the LLM's knowledge to better interpret the spoken language, understand the intended meaning, and produce more accurate and contextually relevant transcripts.
Technical Explanation
The Seed-ASR architecture consists of two main components: an acoustic model and a language model. The acoustic model is responsible for converting the raw audio input into a sequence of speech tokens, while the language model, based on an LLM, provides contextual information to improve the accuracy of the transcription.
The researchers trained and evaluated the Seed-ASR system on a diverse range of speech datasets, including conversational speech, accented speech, and speech in noisy environments. The results demonstrate that the Seed-ASR approach outperforms traditional ASR systems, particularly in challenging speech and context scenarios.
Critical Analysis
The Seed-ASR paper acknowledges some limitations of the proposed approach. For example, the researchers note that the performance of Seed-ASR is still dependent on the quality and coverage of the underlying LLM, and that further research is needed to optimize the integration of the LLM and the acoustic model.
Additionally, the paper does not address potential privacy and security concerns that may arise from the use of LLMs in speech recognition systems, particularly in sensitive or personal applications. Further research and discussion on these ethical and practical implications would be valuable.
Conclusion
The Seed-ASR research presents a promising approach to improving automatic speech recognition by leveraging the language understanding capabilities of large language models. By integrating LLMs into the ASR pipeline, the Seed-ASR system demonstrates improved performance in diverse speech and context scenarios, which could have important implications for a wide range of speech-based applications, from virtual assistants to transcription services.
While the research shows promising results, continued development and exploration of the ethical and practical considerations of using LLMs in speech recognition will be crucial as this technology evolves.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Ye Bai, Jingping Chen, Jitong Chen, Wei Chen, Zhuo Chen, Chuang Ding, Linhao Dong, Qianqian Dong, Yujiao Du, Kepan Gao, Lu Gao, Yi Guo, Minglun Han, Ting Han, Wenchao Hu, Xinying Hu, Yuxiang Hu, Deyu Hua, Lu Huang, Mingkun Huang, Youjia Huang, Jishuo Jin, Fanliu Kong, Zongwei Lan, Tianyu Li, Xiaoyang Li, Zeyang Li, Zehua Lin, Rui Liu, Shouda Liu, Lu Lu, Yizhou Lu, Jingting Ma, Shengtao Ma, Yulin Pei, Chen Shen, Tian Tan, Xiaogang Tian, Ming Tu, Bo Wang, Hao Wang, Yuping Wang, Yuxuan Wang, Hanzhang Xia, Rui Xia, Shuangyi Xie, Hongmin Xu, Meng Yang, Bihong Zhang, Jun Zhang, Wanyi Zhang, Yang Zhang, Yawei Zhang, Yijie Zheng, Ming Zou
Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
Read more7/11/2024

0
Contextualization of ASR with LLM using phonetic retrieval-based augmentation
Zhihong Lei, Xingyu Na, Mingbin Xu, Ernest Pusateri, Christophe Van Gysel, Yuanyuan Zhang, Shiyi Han, Zhen Huang
Large language models (LLMs) have shown superb capability of modeling multimodal signals including audio and text, allowing the model to generate spoken or textual response given a speech input. However, it remains a challenge for the model to recognize personal named entities, such as contacts in a phone book, when the input modality is speech. In this work, we start with a speech recognition task and propose a retrieval-based solution to contextualize the LLM: we first let the LLM detect named entities in speech without any context, then use this named entity as a query to retrieve phonetically similar named entities from a personal database and feed them to the LLM, and finally run context-aware LLM decoding. In a voice assistant task, our solution achieved up to 30.2% relative word error rate reduction and 73.6% relative named entity error rate reduction compared to a baseline system without contextualization. Notably, our solution by design avoids prompting the LLM with the full named entity database, making it highly efficient and applicable to large named entity databases.
Read more9/25/2024
🗣️
0
Speech Recognition Rescoring with Large Speech-Text Foundation Models
Prashanth Gurunath Shivakumar, Jari Kolehmainen, Aditya Gourav, Yi Gu, Ankur Gandhe, Ariya Rastrow, Ivan Bulyko
Large language models (LLM) have demonstrated the ability to understand human language by leveraging large amount of text data. Automatic speech recognition (ASR) systems are often limited by available transcribed speech data and benefit from a second pass rescoring using LLM. Recently multi-modal large language models, particularly speech and text foundational models have demonstrated strong spoken language understanding. Speech-Text foundational models leverage large amounts of unlabelled and labelled data both in speech and text modalities to model human language. In this work, we propose novel techniques to use multi-modal LLM for ASR rescoring. We also explore discriminative training to further improve the foundational model rescoring performance. We demonstrate cross-modal knowledge transfer in speech-text LLM can benefit rescoring. Our experiments demonstrate up-to 20% relative improvements over Whisper large ASR and up-to 15% relative improvements over text-only LLM.
Read more9/26/2024
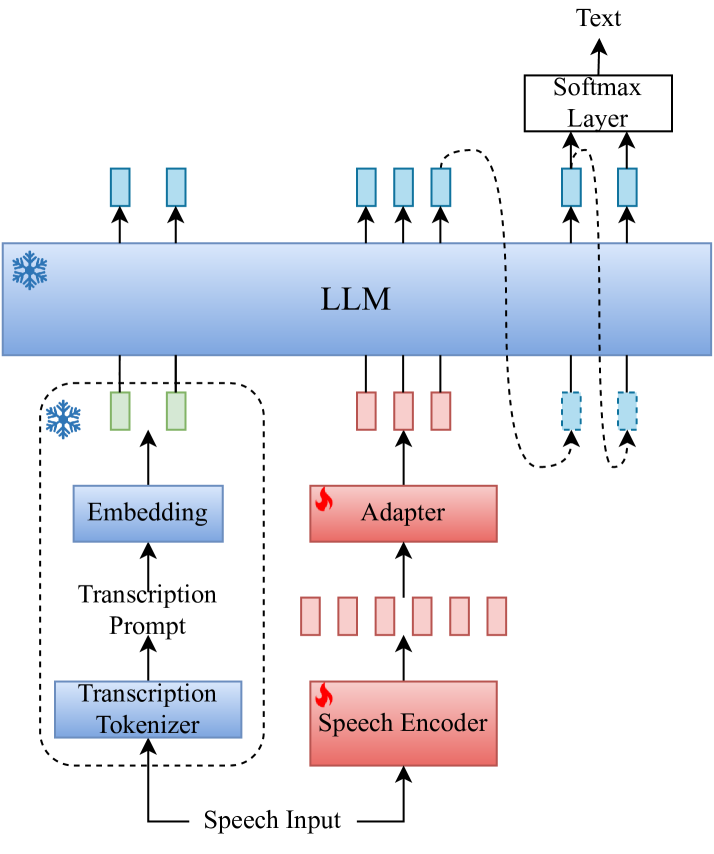
0
A Transcription Prompt-based Efficient Audio Large Language Model for Robust Speech Recognition
Yangze Li, Xiong Wang, Songjun Cao, Yike Zhang, Long Ma, Lei Xie
Audio-LLM introduces audio modality into a large language model (LLM) to enable a powerful LLM to recognize, understand, and generate audio. However, during speech recognition in noisy environments, we observed the presence of illusions and repetition issues in audio-LLM, leading to substitution and insertion errors. This paper proposes a transcription prompt-based audio-LLM by introducing an ASR expert as a transcription tokenizer and a hybrid Autoregressive (AR) Non-autoregressive (NAR) decoding approach to solve the above problems. Experiments on 10k-hour WenetSpeech Mandarin corpus show that our approach decreases 12.2% and 9.6% CER relatively on Test_Net and Test_Meeting evaluation sets compared with baseline. Notably, we reduce the decoding repetition rate on the evaluation set to zero, showing that the decoding repetition problem has been solved fundamentally.
Read more8/20/2024